Identifizieren linearer Modelle mithilfe der Befehlszeile
Einführung
Ziele
Schätzen und Validieren linearer Modelle anhand von MISO-Daten, um herauszufinden, welches der Modelle die Systemdynamiken am besten beschreibt.
Nach Abschluss dieses Tutorials können Sie die folgenden Aufgaben mithilfe der Befehlszeile ausführen:
Erstellen von Datenobjekten zum Darstellen von Daten.
Plotten der Daten.
Verarbeiten von Daten durch Entfernen von Offsets aus den Eingangs- und Ausgangssignalen.
Schätzen und Validieren linearer Modelle anhand der Daten.
Simulieren und Vorhersagen des Modellausgangs.
Hinweis
In diesem Tutorial werden Zeitdomänendaten verwendet, um zu veranschaulichen, wie Sie lineare Modelle schätzen können. Derselbe Workflow kann auch zum Anpassen von Frequenzdomänendaten verwendet werden.
Datenbeschreibung
In diesem Tutorial wird die Datendatei co2data.mat verwendet, die zwei Versuche mit Zeitdomänendaten von zwei Eingängen und einem Ausgang (MISO) aus einem stationären Zustand enthält, den der Operator ausgehend von Gleichgewichtswerten gestört hat.
Im ersten Versuch führte der Operator eine Impulswelle an beiden Eingängen ein. Im zweiten Versuch führte der Operator eine Impulswelle am ersten Eingang und ein Schrittsignal am zweiten Eingang ein.
Vorbereiten von Daten
Laden von Daten in den MATLAB-Workspace
Laden Sie die Daten.
load co2data
Mit diesem Befehl werden die folgenden fünf Variablen in den MATLAB-Workspace geladen:
Input_exp1undOutput_exp1sind die Eingangs- bzw. Ausgangsdaten des ersten Versuchs.Input_exp2undOutput_exp2sind die Eingangs- bzw. Ausgangsdaten des zweiten Versuchs.Timeist der Zeitvektor von 0 bis 1000 Minuten, der sich in gleichmäßigen Schritten von0.5min. erhöht.
Für beide Versuche bestehen die Eingangsdaten aus zwei Spalten mit Werten. Die erste Spalte mit Werten entspricht der Geschwindigkeit des Chemikalienverbrauchs (in Kilogramm pro Minute), die zweite Spalte mit Werten entspricht der Stromstärke (in Ampere). Die Ausgangsdaten befinden sich in einer einzelnen Spalte, deren Werte die Geschwindigkeit der Kohlendioxidproduktion (in Milligramm pro Minute) angeben.
Plotten der Eingangs-/Ausgangsdaten
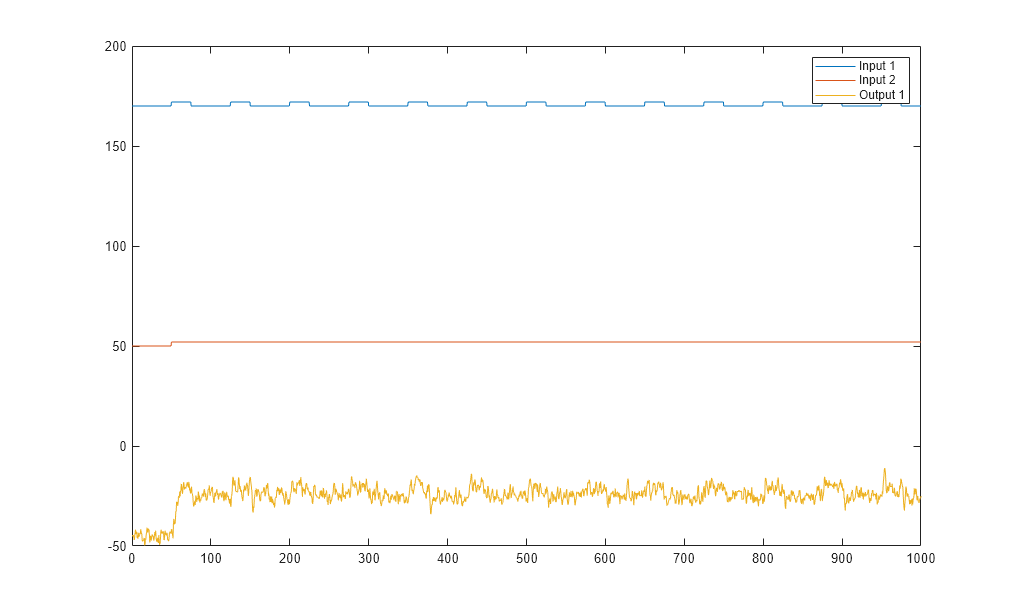
Plotten Sie die Eingangs- und Ausgangsdaten beider Versuche.
plot(Time,Input_exp1,Time,Output_exp1) legend('Input 1','Input 2','Output 1') figure plot(Time,Input_exp2,Time,Output_exp2) legend('Input 1','Input 2','Output 1')
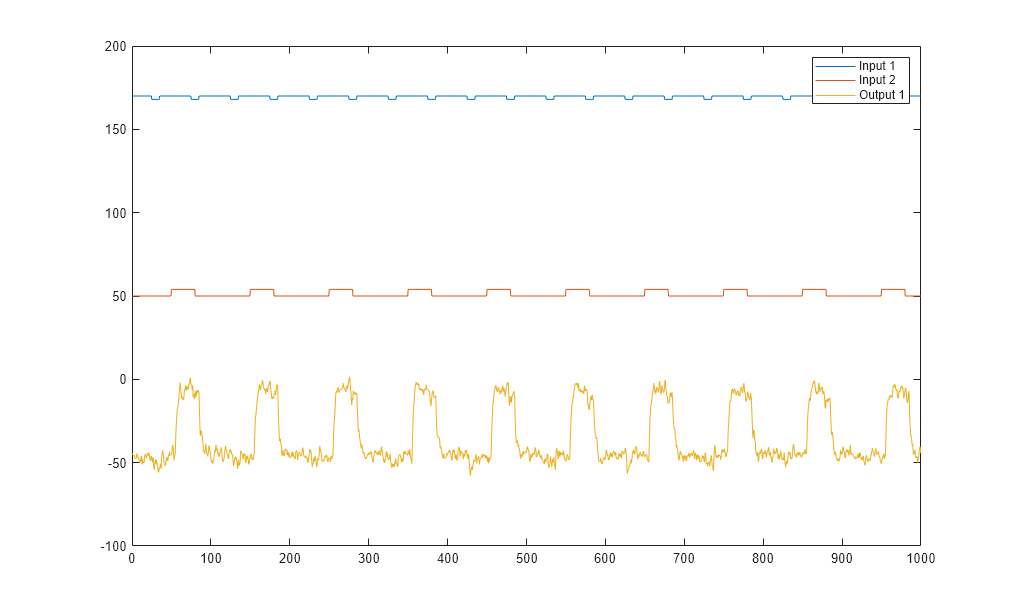
Das erste Diagramm zeigt den ersten Versuch, bei dem der Operator eine Impulswelle auf jeden Eingang anwendet, um das jeweilige stationäre Gleichgewicht zu stören.
Das zweite Diagramm zeigt den zweiten Versuch, bei dem der Operator eine Impulswelle auf den ersten Eingang und ein Schrittsignal auf den zweiten Eingang anwendet.
Entfernen der Gleichgewichtswerte aus den Daten
Beim Plotten der Daten, wie in Plotten der Eingangs-/Ausgangsdaten beschrieben, wird deutlich, dass die Eingänge und Ausgänge Gleichgewichtswerte ungleich null aufweisen. In diesem Teil des Tutorials subtrahieren Sie Gleichgewichtswerte von den Daten.
Sie subtrahieren die Mittelwerte von den jeweiligen Signalen, weil Sie in der Regel lineare Modelle erstellen, die die Antworten für Abweichungen von einem physikalischen Gleichgewicht beschreiben. Bei stationären Daten kann man davon ausgehen, dass die mittleren Pegel der Signale einem solchen Gleichgewicht entsprechen. Auf diese Weise können Sie Modelle um den Nullwert herum suchen, ohne die absoluten Gleichgewichtspegel in physikalischen Einheiten modellieren zu müssen.
Vergrößern Sie die Diagramme, um zu sehen, dass der früheste Zeitpunkt, zu dem der Operator eine Störung auf die Eingänge anwendet, nach 25 Minuten stationärer Bedingungen (oder nach den ersten 50 Abtastungen) eintritt. Somit stellt der Durchschnittswert der ersten 50 Abtastungen die Gleichgewichtsbedingungen dar.
Verwenden Sie die folgenden Befehle, um die Gleichgewichtswerte von den Eingängen und Ausgängen in beiden Versuchen zu entfernen:
Input_exp1 = Input_exp1-... ones(size(Input_exp1,1),1)*mean(Input_exp1(1:50,:)); Output_exp1 = Output_exp1-... mean(Output_exp1(1:50,:)); Input_exp2 = Input_exp2-... ones(size(Input_exp2,1),1)*mean(Input_exp2(1:50,:)); Output_exp2 = Output_exp2-... mean(Output_exp2(1:50,:));
Verwenden von Objekten zum Darstellen von Daten für die Systemidentifikation
Die Datenobjekte der System Identification Toolbox™, iddata und idfrd, verkapseln Datenwerte und Dateneigenschaften zu einer einzigen Einheit. Sie können diese Datenobjekte mithilfe der Befehle der System Identification Toolbox komfortabel als einzelne Einheiten bearbeiten.
In diesem Teil des Tutorials erstellen Sie zwei iddata-Objekte: eines für jeden der beiden Versuche. Sie verwenden die Daten aus Versuch 1 für die Modellschätzung und die Daten aus Versuch 2 für die Modellvalidierung. Sie arbeiten mit zwei unabhängigen Datensätzen, weil Sie einen Datensatz für die Modellschätzung und den anderen für die Modellvalidierung verwenden.
Hinweis
Wenn zwei unabhängige Datensätze nicht verfügbar sind, können Sie einen Datensatz in zwei Teile splitten, wobei davon ausgegangen wird, dass jeder Teil genug Informationen enthält, um die Systemdynamiken angemessen darzustellen.
Erstellen von iddata-Objekten
Sie müssen die Beispieldaten bereits in den MATLAB®-Workspace geladen haben, wie in Laden von Daten in den MATLAB-Workspace beschrieben.
Verwenden Sie diese Befehle, um zwei Datenobjekte, ze und zv zu erstellen:
Ts = 0.5; % Sample time is 0.5 min
ze = iddata(Output_exp1,Input_exp1,Ts);
zv = iddata(Output_exp2,Input_exp2,Ts);
ze enthält Daten aus Versuch 1 und zv enthält Daten aus Versuch 2. Ts ist die Abtastzeit.
Der iddata-Konstruktor erfordert drei Argumente für Zeitdomänendaten und weist folgende Syntax auf:
data_obj = iddata(output,input,sampling_interval);
Zum Anzeigen der Eigenschaften eines iddata-Objekts verwenden Sie den Befehl get. Beispielsweise geben Sie zum Abrufen der Eigenschaften der Schätzdaten den folgenden Befehl ein:
Weitere Informationen zu den Eigenschaften dieses Datenobjekts finden Sie auf der Referenzseite zu iddata.
Zum Ändern von Dateneigenschaften können Sie die Punktschreibweise oder den Befehl set verwenden. Wenn Sie beispielsweise Kanalnamen und Einheiten zuweisen möchten, mit denen die Diagrammachsen beschriftet sind, geben Sie die folgende Syntax in das MATLAB-Befehlsfenster ein:
Tipp
Bei Eigenschaftennamen, z. B. InputUnit, muss die Groß-/Kleinschreibung nicht beachtet werden. Sie können Eigenschaftennamen, die mit Input oder Output beginnen, auch abkürzen, indem Sie im Namen u anstatt Input und y anstatt Output verwenden. Beispielsweise ist OutputUnit gleichbedeutend mit yunit.
Plotten der Daten in einem Datenobjekt
Sie können iddata-Objekte mithilfe des plot-Befehls plotten.
Plotten Sie die Schätzdaten.
plot(ze)
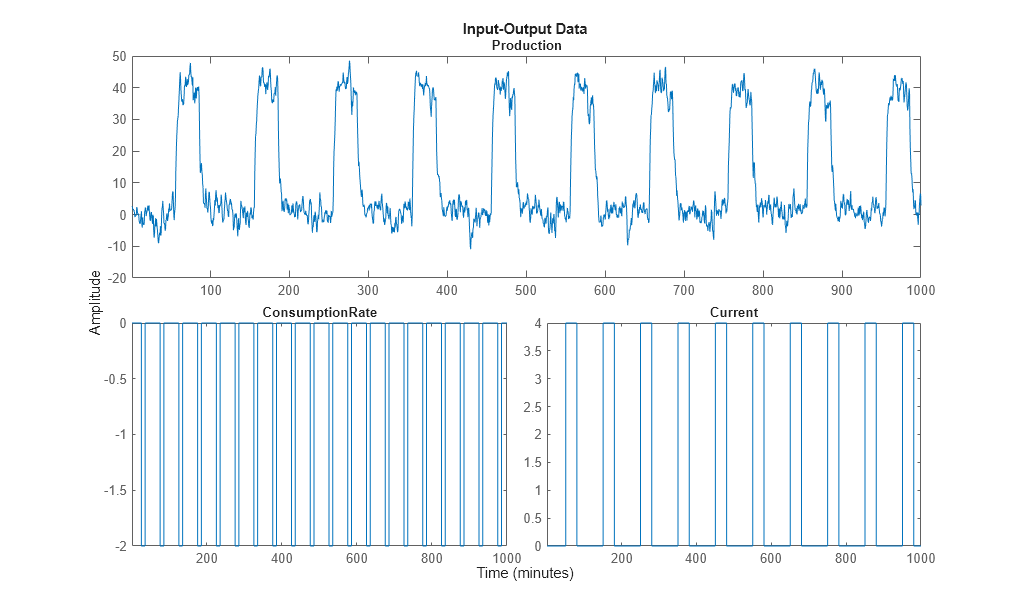
Entlang der unteren Achsen sind die Eingänge ConsumptionRate und Current und entlang der oberen Achsen ist der Ausgang ProductionRate abgebildet.
Auswählen einer Teilmenge der Daten
Erstellen Sie zunächst einen neuen Datensatz, der nur die ersten 1000 Abtastungen der ursprünglichen Schätzungs- und Validierungsdatensätze enthält, um die Berechnungen zu beschleunigen.
Ze1 = ze(1:1000); Zv1 = zv(1:1000);
Ausführliche Informationen zum Erstellen von Indizes in iddata-Objekten finden Sie auf der entsprechenden Referenzseite.
Schätzung von Impulsantwort-Modellen
Wozu dient die Schätzung von Sprungantwort- und Frequenzgangmodellen?
Frequenzgang- und Sprungantwortmodelle sind nichtparametrische Modelle, mit denen sich die dynamischen Eigenschaften Ihres Systems leichter verstehen lassen. Diese Modelle werden nicht durch eine kompakte mathematische Formel mit anpassbaren Parametern dargestellt. Stattdessen bestehen sie aus Datentabellen.
In diesem Teil des Tutorials schätzen Sie diese Modelle mithilfe des Datensatzes ze. Sie müssen ze bereits erstellt haben, wie in Erstellen von iddata-Objekten beschrieben.
Die Antwortdiagramme aus diesen Modellen veranschaulichen die folgenden Eigenschaften des Systems:
Die Antwort des ersten Eingangs zum Ausgang kann eine Funktion zweiter Ordnung sein.
Die Antwort des zweiten Eingangs zum Ausgang kann eine Funktion erster Ordnung oder eine Funktion mit Überdämpfung sein.
Schätzung des Frequenzgangs
Das Produkt System Identification Toolbox stellt drei Funktionen für die Schätzung des Frequenzgangs zur Verfügung:
Verwenden Sie spa, um den Frequenzgang zu schätzen.
Ge = spa(ze);
Plotten Sie den Frequenzgang als Bode-Diagramm.
bode(Ge)
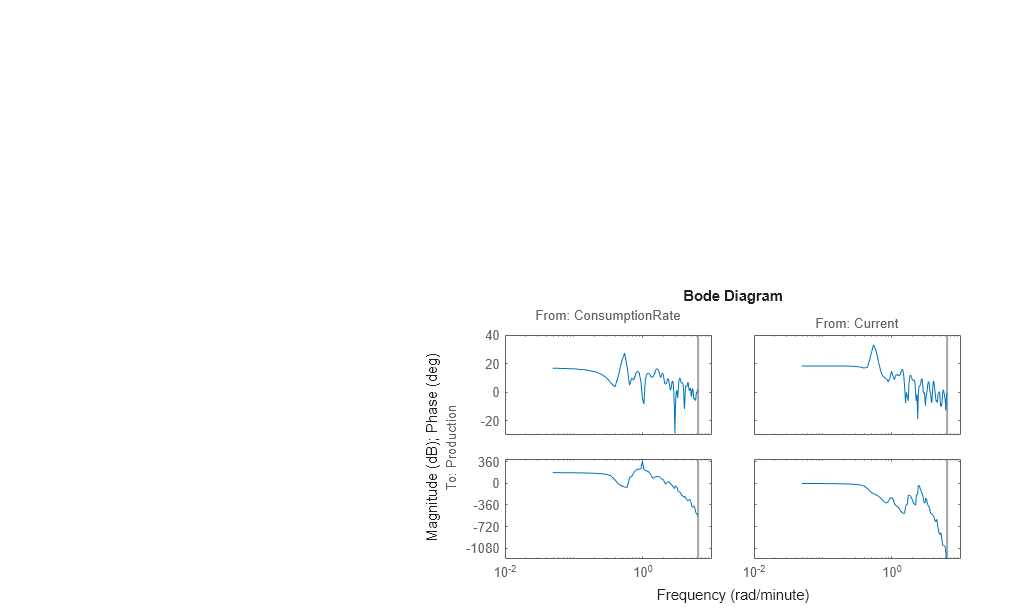
Die Amplitude weist ihren Spitzenwert bei einer Frequenz von 0,54 rad/min auf, was auf ein mögliches Resonanzverhalten (komplexe Polstellen) für die erste Eingang-zu-Ausgang-Kombination – ConsumptionRate zu Production – hinweist.
In beiden Diagrammen sinkt die Phase schnell ab, was auf eine Zeitverzögerung für beide Eingang/Ausgang-Kombinationen hinweist.
Schätzung der empirischen Sprungantwort
Zum Schätzen der Sprungantwort anhand der Daten schätzen Sie zunächst ein nichtparametrisches Impulsantwort-Modell (FIR-Filter) anhand der Daten und plotten dann seine Sprungantwort.
% model estimation Mimp = impulseest(Ze1,60); % step response step(Mimp)
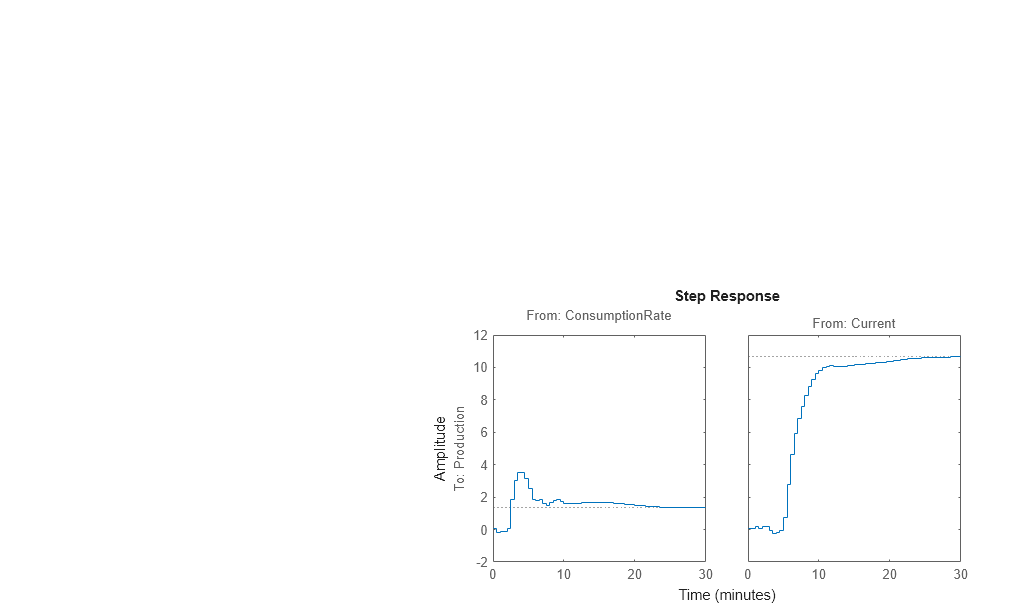
Die Sprungantwort für die erste Eingang/Ausgang-Kombination lässt ein Überschwingen vermuten, was auf das Vorhandensein eines unterdämpften Modus (komplexe Polstellen) im physikalischen System hinweist.
Die Sprungantwort vom zweiten Eingang zum Ausgang weist kein Überschwingen auf, was entweder auf eine Antwort erster Ordnung oder eine Antwort höherer Ordnung mit reellen Polstellen (überdämpfte Antwort) hinweist.
Das Sprungantwortdiagramm weist darauf hin, dass im System eine Verzögerung ungleich null vorliegt, was mit dem schnellen Absinken der Phase im Bode-Diagramm übereinstimmt, das Sie in Schätzung der empirischen Sprungantwort erstellt haben.
Schätzung von Verzögerungen im System mit mehreren Eingängen
Wozu dient die Schätzung von Verzögerungen?
Zum Identifizieren parametrischer Black-Box-Modelle müssen Sie die Eingangs-/Ausgangsverzögerung als Teil der Modellordnung angeben.
Wenn die Eingangs-/Ausgangsverzögerungen für Ihr System aus dem Versuch unbekannt sind, können Sie die Verzögerung mithilfe der Software System Identification Toolbox schätzen.
Schätzung von Verzögerungen mithilfe der ARX-Modellstruktur
Bei Systemen mit einem einzelnen Eingang können Sie die Verzögerung im Impulsantwort-Diagramm ablesen. Bei Systemen mit mehreren Eingängen, wie dem in diesem Tutorial, kann unter Umständen nicht ermittelt werden, welcher Eingang die anfängliche Änderung im Ausgang verursacht hat, und Sie können stattdessen den Befehl delayest verwenden.
Der Befehl schätzt die Zeitverzögerung in einem dynamischen System, indem er ein zeitdiskretes ARX-Modell niedriger Ordnung mit einer Reihe von Verzögerungen schätzt und anschließend die Verzögerung mit der größten Übereinstimmung auswählt.
Die ARX-Modellstruktur ist eine der einfachsten parametrischen Black-Box-Strukturen. Zeitdiskret ist die ARX-Struktur eine Differenzengleichung, die wie folgt aussieht:
y(t) steht dabei für den Ausgang zum Zeitpunkt t, u(t) steht für den Eingang zum Zeitpunkt t, na ist die Anzahl der Polstellen, nb ist die Anzahl der b-Parameter (gleich der Anzahl der Nullstellen plus 1), nk ist die Anzahl der Abtastungen, bevor sich der Eingang auf den Ausgang des Systems auswirkt (die sogenannte Verzögerung oder Totzeit des Modells), und e(t) ist die Störung durch weißes Rauschen.
delayest geht davon aus, dass na=nb=2 und dass das Rauschen e weiß oder insignifikant ist, und schätzt nk.
Geben Sie zum Schätzen der Verzögerung in diesem System Folgendes ein:
delayest(ze)
ans =
5 10
Dieses Ergebnis umfasst zwei Zahlen, weil es zwei Eingänge gibt: Die geschätzte Verzögerung für den ersten Eingang entspricht 5 Datenstichproben und die geschätzte Verzögerung für den zweiten Eingang entspricht 10 Datenstichproben. Da die Abtastzeit für den Versuch 0.5 min ist, entspricht dies einer Verzögerung von 2.5 min, bevor sich der erste Eingang auf den Ausgang auswirkt, und einer Verzögerung von 5.0 min, bevor sich der zweite Eingang auf den Ausgang auswirkt.
Schätzung von Verzögerungen mithilfe alternativer Methoden
Für die Schätzung der Zeitverzögerung im System stehen zwei alternative Methoden zur Verfügung:
Erstellen Sie das Zeitdiagramm der Eingangs- und Ausgangsdaten und lesen Sie die Zeitdifferenz zwischen der ersten Änderung im Eingang und der ersten Änderung im Ausgang ab. Diese Methode eignet sich nur für ein System, das jeweils nur einen Eingang und einen Ausgang besitzt. Bei Systemen mit mehreren Eingängen kann möglicherweise nicht ermittelt werden, welcher Eingang die anfängliche Änderung im Ausgang verursacht hat.
Plotten Sie die Impulsantwort der Daten mit einem Konfidenzintervall (Standardabweichung 1). Sie können die Zeitverzögerung mithilfe der Zeit schätzen, wenn die Impulsantwort zunächst außerhalb des Konfidenzintervalls liegt.
Schätzung der Modellordnungen mithilfe einer ARX-Modellstruktur
Wozu dient die Schätzung der Modellordnung?
Die Modellordnung wird durch mindestens eine Ganzzahl angegeben, die die Komplexität des Modells definiert. Im Allgemeinen bezieht sich die Modellordnung auf die Anzahl der Polstellen, die Anzahl der Nullstellen und die Antwortverzögerung (Zeit ausgedrückt als Anzahl der Abtastungen, bevor der Ausgang auf den Eingang reagiert). Die jeweilige Bedeutung der Modellordnung hängt von der Modellstruktur ab.
Zum Berechnen parametrischer Black-Box-Modelle müssen Sie die Modellordnung als Eingang bereitstellen. Wenn die Ordnung Ihres Systems unbekannt ist, können Sie diese schätzen.
Sobald Sie alle Schritte in diesem Abschnitt ausgeführt haben, erhalten Sie die folgenden Ergebnisse:
Für die erste Eingang/Ausgang-Kombination: na=2, nb=2 und die Verzögerung nk=5.
Für die zweite Eingang/Ausgang-Kombination: na=1, nb=1 und die Verzögerung nk=10.
Später untersuchen Sie verschiedene Modellstrukturen, indem Sie Modellordnungswerte angeben, die minimal von dieser ersten Schätzung abweichen.
Befehle zum Schätzen der Modellordnung
In diesem Teil des Tutorials verwenden Sie struc, arxstruc und selstruc, um einfache Polynommodelle (ARX) für einen Bereich von Modellordnungen und -verzögerungen zu schätzen und zu vergleichen und um die besten Ordnungen basierend auf der Qualität des Modells auszuwählen.
In der folgenden Liste sind die Ergebnisse beschrieben, die aus der Verwendung der einzelnen Befehle resultieren:
strucerstellt eine Matrix von Modellordnungs-Kombinationen für einen festgelegten Bereich der Werte na, nb und nk.arxstrucverwendet den Ausgang vonstruc, schätzt systematisch ein ARX-Modell für jede Modellordnung und vergleicht den Modellausgang mit dem gemessenen Ausgang.arxstrucgibt die Verlustfunktion für jedes Modell zurück, also die normalisierte Summe der Vorhersagefehler im Quadrat.selstrucverwendet den Ausgang vonarxstrucund öffnet das Fenster „ARX Model Structure Selection“ (Auswahl der ARX-Modellstruktur), das in etwa wie in der folgenden Abbildung aussieht, damit Sie die Modellordnung auswählen können.Wählen Sie mithilfe dieses Diagramms das am besten geeignete Modell aus.

Entlang der horizontalen Achse wird die Gesamtzahl der Parameter abgebildet: na + nb.
Entlang der vertikalen Achse mit der Beschriftung Unexplained output variance (in %) ist der Teil des Ausgangs abgebildet, der vom Modell nicht erklärt werden kann: der Vorhersagefehler des ARX-Modells für die Anzahl der Parameter, die entlang der horizontalen Achse abgebildet sind.
Der Vorhersagefehler ist die Summe der Quadrate der Differenzen zwischen dem Validierungsdatenausgang und dem Ausgang der Einen-Schritt-voraus-Vorhersage des Modells.
nk ist die Verzögerung.
Im Diagramm sind drei Rechtecke grün, blau und rot hervorgehoben. Jede Farbe weist wie folgt auf einen Typ der am besten geeigneten Kriterien hin:
Rot: beste Übereinstimmung, minimiert die Summe der Quadrate der Differenz zwischen dem Validierungsdatenausgang und dem Modellausgang. Dieses Rechteck gibt die beste Übereinstimmung insgesamt an.
Grün: beste Übereinstimmung, minimiert das Rissanen-MDL-Kriterium.
Blau: beste Übereinstimmung, minimiert das Akaike-AIC-Kriterium.
In diesem Tutorial bleibt der Wert Unexplained output variance (in %) (Unerklärte Ausgangsvarianz (in %)) für die gesamte Anzahl der Parameter von 4 bis 20 in etwa konstant. Eine solche Konstanz weist darauf hin, dass sich die Modellleistung bei höheren Ordnungen nicht verbessert. Daher können Modelle niedriger Ordnungen ebenso gut zu den Daten passen.
Hinweis
Wenn Sie denselben Datensatz für die Schätzung und die Validierung verwenden, wählen Sie die Modellordnungen mithilfe der MDL- und AIC-Kriterien aus. Diese Kriterien kompensieren die Überanpassung, die sich aus der Verwendung zu vieler Parameter ergibt. Weitere Informationen zu diesen Kriterien finden Sie auf der Referenzseite zu
selstruc.
Modellordnung für die erste Eingang/Ausgang-Kombination
In diesem Tutorial weist das System zwei Eingänge und einen Ausgang auf und Sie schätzen Modellordnungen unabhängig für jede Eingang/Ausgang-Kombination. Sie können die Verzögerungen von den beiden Eingängen entweder gleichzeitig oder nacheinander für jeden Eingang schätzen.
Es ist sinnvoll, die folgenden Ordnungskombinationen für die erste Eingang/Ausgang-Kombination auszuprobieren:
na=
2:5nb=
1:5nk=
5
Dies liegt daran, dass die von Ihnen in Schätzung von Impulsantwort-Modellen geschätzten nichtparametrischen Modelle zeigen, dass die Antwort für die erste Eingang/Ausgang-Kombination möglicherweise eine Antwort zweiter Ordnung aufweist. Ähnlich wurde in Schätzung von Verzögerungen im System mit mehreren Eingängen die Verzögerung für diese Eingang/Ausgang-Kombination auf 5 geschätzt.
So schätzen Sie die Modellordnung für die erste Eingang/Ausgang-Kombination:
Erstellen Sie mithilfe von
struceine Matrix möglicher Modellordnungen.NN1 = struc(2:5,1:5,5);
Berechnen Sie mithilfe von
selstrucdie Verlustfunktionen für die ARX-Modelle mit den Ordnungen inNN1.selstruc(arxstruc(ze(:,:,1),zv(:,:,1),NN1))
Hinweis
ze(:,:,1)wählt den ersten Eingang in den Daten aus.Dieser Befehl öffnet das interaktive Fenster „ARX Model Structure Selection“ (Auswahl der ARX-Modellstruktur).

Hinweis
Die Rissanen-MDL- und Akaike-AIC-Kriterien führen zu gleichwertigen Ergebnissen und werden im Diagramm beide durch ein blaues Rechteck dargestellt.
Das rote Rechteck stellt die beste Übereinstimmung insgesamt dar, die für na=2, nb=3 und nk=5 auftritt. Der Höhenunterschied zwischen dem roten und dem blauen Rechteck ist insignifikant. Daher können Sie die Parameterkombination auswählen, die der niedrigsten Modellordnung und dem einfachsten Modell entspricht.
Klicken Sie auf das blaue Rechteck und anschließend auf Select, um diese Kombination an Ordnungen auszuwählen:
na=
2nb=
2nk=
5Um fortzufahren, drücken Sie eine beliebige Taste, während Sie sich im MATLAB-Befehlsfenster befinden.
Modellordnung für die zweite Eingang/Ausgang-Kombination
Es ist sinnvoll, die folgenden Ordnungskombinationen für die zweite Eingang/Ausgang-Kombination auszuprobieren:
na=
1:3nb=
1:3nk=
10
Dies liegt daran, dass die nichtparametrischen Modelle, die Sie in Schätzung von Impulsantwort-Modellen geschätzt haben, zeigen, dass die Antwort für die zweite Eingang/Ausgang-Kombination möglicherweise eine Antwort erster Ordnung aufweist. Ähnlich wurde in Schätzung von Verzögerungen im System mit mehreren Eingängen die Verzögerung für diese Eingang/Ausgang-Kombination auf 10 geschätzt.
So schätzen Sie die Modellordnung für die zweite Eingang/Ausgang-Kombination:
Erstellen Sie mithilfe von
struceine Matrix möglicher Modellordnungen.NN2 = struc(1:3,1:3,10);
Berechnen Sie mithilfe von
selstrucdie Verlustfunktionen für die ARX-Modelle mit den Ordnungen inNN2.selstruc(arxstruc(ze(:,:,2),zv(:,:,2),NN2))
Dieser Befehl öffnet das interaktive Fenster „ARX Model Structure Selection“ (Auswahl der ARX-Modellstruktur).

Hinweis
Das Akaike-AIC-Kriterium und die Kriterien für die beste Übereinstimmung insgesamt generieren gleichwertige Ergebnisse. Beide werden im Diagramm durch dasselbe rote Rechteck dargestellt.
Der Höhenunterschied zwischen allen Rechtecken ist insignifikant und alle diese Modellordnungen führen zu einer ähnlichen Modellleistung. Daher können Sie die Parameterkombination auswählen, die der niedrigsten Modellordnung und dem einfachsten Modell entspricht.
Klicken Sie auf das gelbe Rechteck ganz links und anschließend auf Select, um die niedrigste Ordnung auszuwählen: na=1, nb=1 und nk=10.
Um fortzufahren, drücken Sie eine beliebige Taste, während Sie sich im MATLAB-Befehlsfenster befinden.
Schätzung von Transferfunktionen
Angeben der Struktur der Transferfunktion
In diesem Teil des Tutorials schätzen Sie eine zeitkontinuierliche Transferfunktion. Sie müssen Ihre Daten bereits vorbereitet haben, wie in Vorbereiten von Daten beschrieben. Sie können zum Angeben der Ordnungen des Modells die folgenden Ergebnisse geschätzter Modellordnungen verwenden:
Verwenden Sie Folgendes für die erste Eingang/Ausgang-Kombination:
Zwei Polstellen, was im ARX-Modell
na=2entspricht.Einen Verzögerungswert von 5, was im ARX-Modell
nk=5Abtastungen (oder 2,5 Minuten) entspricht.
Verwenden Sie Folgendes für die zweite Eingang/Ausgang-Kombination:
Eine Polstelle, was im ARX-Modell
na=1entspricht.Einen Verzögerungswert von 10, was im ARX-Modell
nk=10Abtastungen (oder 5 Minuten) entspricht.
Sie können mithilfe des Befehls tfest eine Transferfunktion dieser Ordnungen schätzen. Für die Schätzung können Sie wahlweise auch einen Fortschrittsbericht anzeigen, indem Sie die Option Display im Optionssatz, der mit dem Befehl tfestOptions erstellt wurde, auf on setzen.
Opt = tfestOptions('Display','on');
Fassen Sie die Modellordnungen und Verzögerungen in Variablen zusammen, die Sie an tfest weiterleiten können.
np = [2 1]; ioDelay = [2.5 5];
Schätzen Sie die Transferfunktion.
mtf = tfest(Ze1,np,[],ioDelay,Opt);
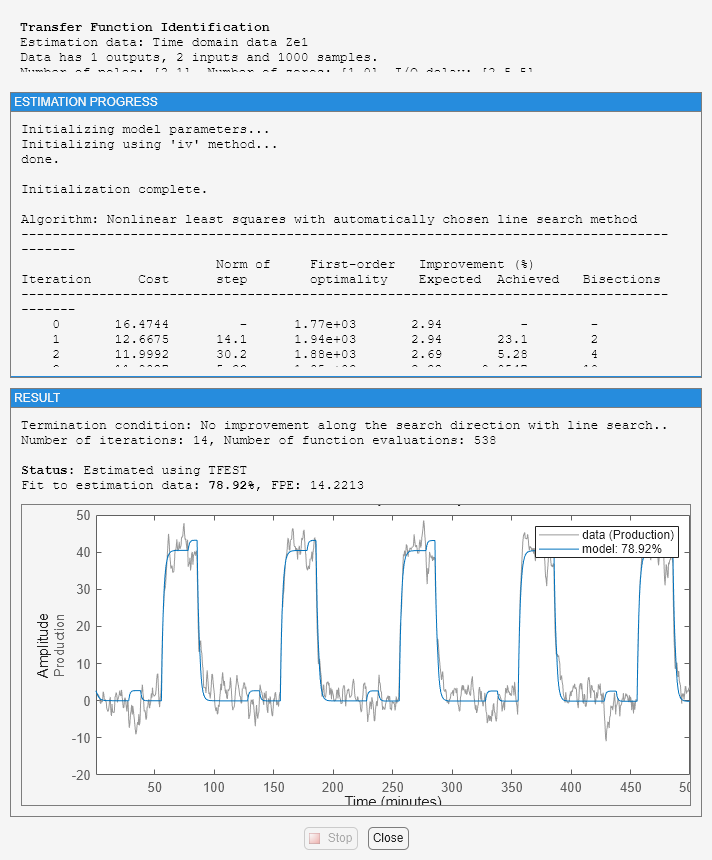
Zeigen Sie die Koeffizienten des Modells an.
mtf
mtf =
From input "ConsumptionRate" to output "Production":
-1.382 s + 0.0008305
exp(-2.5*s) * -------------------------
s^2 + 1.014 s + 5.443e-12
From input "Current" to output "Production":
5.93
exp(-5*s) * ----------
s + 0.5858
Continuous-time identified transfer function.
Parameterization:
Number of poles: [2 1] Number of zeros: [1 0]
Number of free coefficients: 6
Use "tfdata", "getpvec", "getcov" for parameters and their uncertainties.
Status:
Estimated using TFEST on time domain data "Ze1".
Fit to estimation data: 78.92%
FPE: 14.22, MSE: 13.97
Das Modell zeigt eine Übereinstimmung mit den Schätzdaten von über 85 % an.
Validierung des Modells
In diesem Teil des Tutorials erstellen Sie ein Diagramm, in dem der tatsächliche Ausgang und der Modellausgang mithilfe des Befehls compare verglichen werden.
compare(Zv1,mtf)
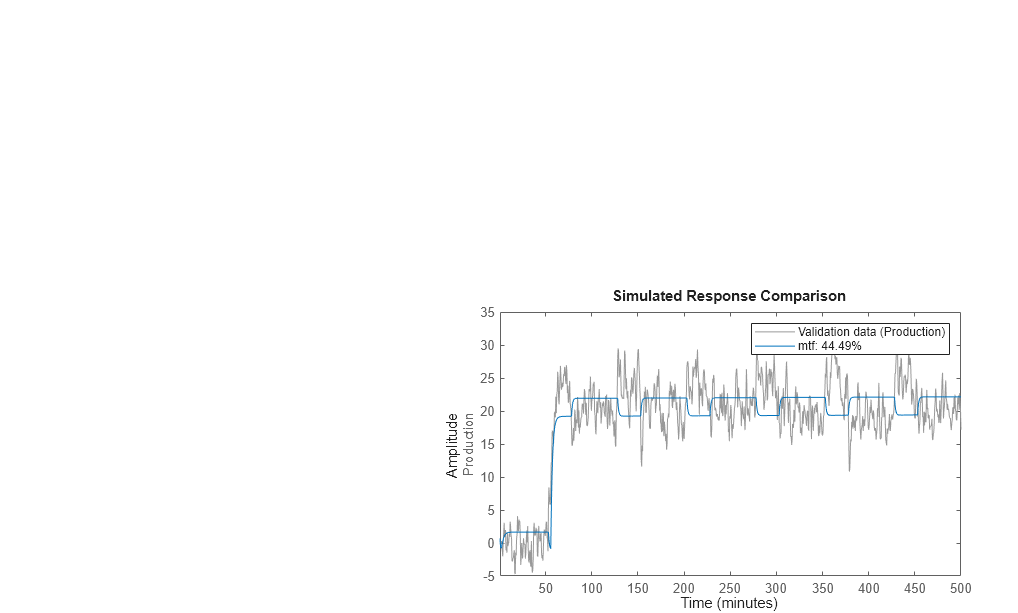
Der Vergleich ergibt eine Übereinstimmung von etwa 60 %.
Residuenanalyse
Mithilfe des Befehls resid können Sie die Merkmale der Residuen auswerten.
resid(Zv1,mtf)
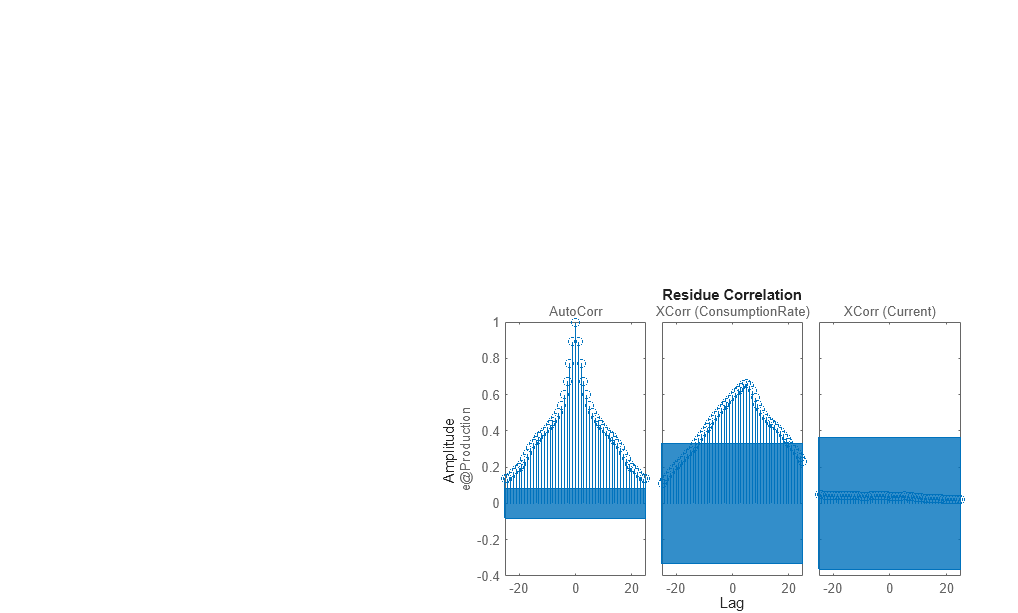
Die Residuen weisen ein höheres Maß an Autokorrelation auf. Dies überrascht nicht, da die Transferfunktion mtf des Modells keine Komponenten aufweist, die die Natur des Rauschens separat beschreiben. Zur Modellierung der gemessenen Eingangs-/Ausgangsdynamik und der Stördynamik müssen Sie eine Modellstruktur verwenden, die Elemente zur Beschreibung des Rauschanteils enthält. Sie können die Befehle bj, ssest und procest verwenden, mit denen Modelle von Polynom-, Zustandsraum- bzw. Prozess-Strukturen erstellt werden. Diese Strukturen enthalten unter anderem Elemente zur Erfassung des Rauschverhaltens.
Schätzung von Prozessmodellen
Angeben der Struktur des Prozessmodells
In diesem Teil des Tutorials schätzen Sie eine zeitkontinuierliche Transferfunktion niedriger Ordnung (Prozessmodell). Das Produkt System Identification Toolbox unterstützt zeitkontinuierliche Modelle mit mindestens drei Polstellen (die möglicherweise unterdämpfte Polstellen enthalten), eine Nullstelle, ein Verzögerungselement und einen Integrator.
Sie müssen Ihre Daten bereits vorbereitet haben, wie in Vorbereiten von Daten beschrieben.
Sie können zum Angeben der Ordnungen des Modells die folgenden Ergebnisse geschätzter Modellordnungen verwenden:
Verwenden Sie Folgendes für die erste Eingang/Ausgang-Kombination:
Zwei Polstellen, was im ARX-Modell na=2 entspricht.
Einen Verzögerungswert von 5, was im ARX-Modell nk=5 Abtastungen (oder 2,5 Minuten) entspricht.
Verwenden Sie Folgendes für die zweite Eingang/Ausgang-Kombination:
Eine Polstelle, was im ARX-Modell na=1 entspricht.
Einen Verzögerungswert von 10, was im ARX-Modell nk=10 Abtastungen (oder 5 Minuten) entspricht.
Hinweis
Da keine Beziehung zwischen der Anzahl von Nullstellen, die durch das zeitdiskrete ARX-Modell geschätzt wurde, und dem zeitkontinuierlichen Pendant besteht, steht kein Schätzwert für die Anzahl der Nullstellen zur Verfügung. In diesem Tutorial können Sie eine Nullstelle für die erste Eingang/Ausgang-Kombination und keine Nullstelle für die zweite Eingang/Ausgang-Kombination angeben.
Erstellen Sie mithilfe des Befehls idproc zwei Modellstrukturen – eine für jede Eingang/Ausgang-Kombination:
Anzeigen der Modellstruktur und Parameterwerte
Zeigen Sie die beiden resultierenden Modelle an.
midproc0
midproc0 =
Process model with 2 inputs: y = G11(s)u1 + G12(s)u2
From input 1 to output 1:
1+Tz*s
G11(s) = Kp * ---------------------- * exp(-Td*s)
1+2*Zeta*Tw*s+(Tw*s)^2
Kp = NaN
Tw = NaN
Zeta = NaN
Td = NaN
Tz = NaN
From input 2 to output 1:
Kp
G12(s) = ---------- * exp(-Td*s)
1+Tp1*s
Kp = NaN
Tp1 = NaN
Td = NaN
Parameterization:
{'P2DUZ'} {'P1D'}
Number of free coefficients: 8
Use "getpvec", "getcov" for parameters and their uncertainties.
Status:
Created by direct construction or transformation. Not estimated.
Die Parameterwerte sind auf NaN gesetzt, weil sie noch nicht geschätzt wurden.
Angeben von Anfangsvermutungen für Zeitverzögerungen
Setzen Sie als Anfangsvermutung die Zeitverzögerungseigenschaft des Modellobjekts für jedes Eingangs-/Ausgangspaar auf 2.5 min und 5 min. Legen Sie außerdem einen oberen Grenzwert für die Verzögerung fest, da gute Anfangsvermutungen verfügbar sind.
midproc0.Structure(1,1).Td.Value = 2.5; midproc0.Structure(1,2).Td.Value = 5; midproc0.Structure(1,1).Td.Maximum = 3; midproc0.Structure(1,2).Td.Maximum = 7;
Hinweis
Beim Festlegen der Verzögerungs-Zwangsbedingungen müssen Sie die Verzögerungen in tatsächlichen Zeiteinheiten (in diesem Fall in Minuten) und nicht als Anzahl der Abtastungen angeben.
Schätzung von Modellparametern mithilfe von „procest“
procest ist eine iterative Schätzfunktion von Prozessmodellen, d. h. sie verwendet einen iterativen, nichtlinearen Kleinste-Quadrate-Algorithmus, um eine Kostenfunktion zu minimieren. Die Kostenfunktion ist die gewichtete Summe der Fehlerquadrate.
Abhängig von den verwendeten Argumenten schätzt procest verschiedene Black-Box-Polynommodelle. Mithilfe von procest können Sie Parameter für lineare, zeitkontinuierliche Transferfunktion-, Zustandsraum- oder Polynommodellstrukturen schätzen. Um procest verwenden zu können, müssen Sie eine Modellstruktur mit unbekannten Parametern und die Schätzdaten als Eingangsargumente bereitstellen.
Für diesen Teil des Tutorials muss die Modellstruktur bereits definiert sein, wie in Angeben der Struktur des Prozessmodells beschrieben. Verwenden Sie midproc0 als Modellstruktur und Ze1 als Schätzdaten:
midproc = procest(Ze1,midproc0); present(midproc)
midproc =
Process model with 2 inputs: y = G11(s)u1 + G12(s)u2
From input "ConsumptionRate" to output "Production":
1+Tz*s
G11(s) = Kp * ---------------------- * exp(-Td*s)
1+2*Zeta*Tw*s+(Tw*s)^2
Kp = -1.1807 +/- 0.29986
Tw = 1.6437 +/- 714.6
Zeta = 16.036 +/- 6958.9
Td = 2.426 +/- 64.276
Tz = -109.19 +/- 63.736
From input "Current" to output "Production":
Kp
G12(s) = ---------- * exp(-Td*s)
1+Tp1*s
Kp = 10.264 +/- 0.048404
Tp1 = 2.049 +/- 0.054901
Td = 4.9175 +/- 0.034374
Parameterization:
{'P2DUZ'} {'P1D'}
Number of free coefficients: 8
Use "getpvec", "getcov" for parameters and their uncertainties.
Status:
Termination condition: Maximum number of iterations reached..
Number of iterations: 20, Number of function evaluations: 279
Estimated using PROCEST on time domain data "Ze1".
Fit to estimation data: 86.2%
FPE: 6.081, MSE: 5.984
More information in model's "Report" property.
Im Gegensatz zu zeitdiskreten Polynommodellen können Sie mithilfe zeitkontinuierlicher Modelle die Verzögerungen schätzen. In diesem Fall unterscheiden sich die geschätzten Verzögerungswerte von den angegebenen Anfangsvermutungen 2.5 bzw. 5. Die großen Unsicherheiten bei den geschätzten Werten der Parameter von G_1(s) weisen darauf hin, dass die Dynamik vom Eingang 1 zum Ausgang nicht korrekt erfasst wird.
Weitere Informationen zum Schätzen von Modellen finden Sie unter Prozessmodelle.
Validierung des Modells
In diesem Teil des Tutorials erstellen Sie ein Diagramm, in dem der tatsächliche Ausgang und der Modellausgang verglichen werden.
compare(Zv1,midproc)
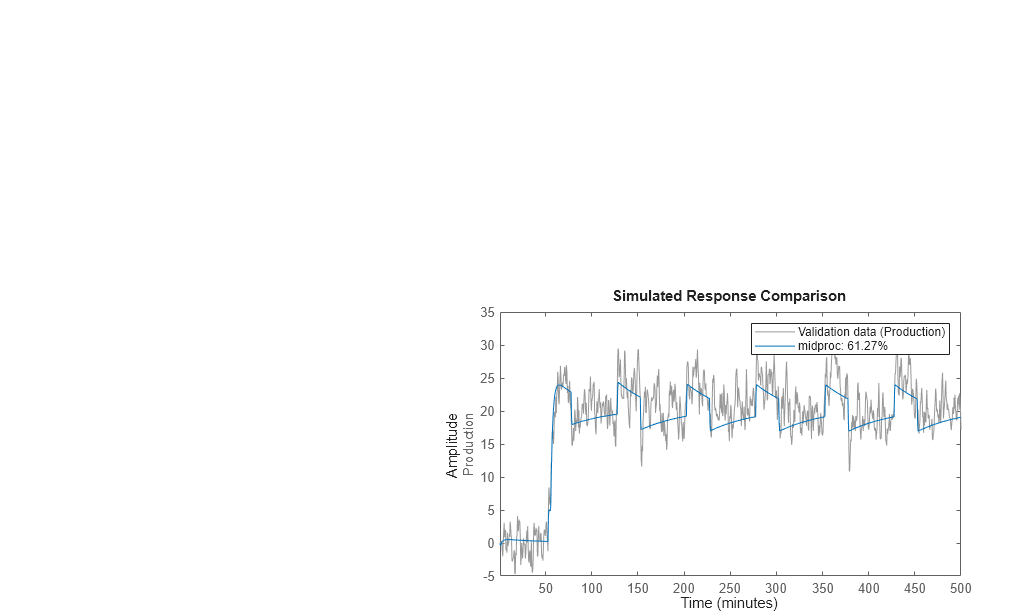
Das Diagramm veranschaulicht, dass der Modellausgang einigermaßen mit dem gemessenen Ausgang übereinstimmt: Die Übereinstimmung zwischen dem Modell und den Validierungsdaten beträgt 60 %.
Schätzung eines Prozessmodells mit einem Rauschmodell
In diesem Teil des Tutorials erfahren Sie, wie Sie ein Prozessmodell schätzen und bei der Schätzung ein Rauschmodell berücksichtigen. Die Einbeziehung eines Rauschmodells verbessert in der Regel zwar die Vorhersageergebnisse, doch nicht unbedingt auch die Simulationsergebnisse.
Verwenden Sie die folgenden Befehle, um ein ARMA-Rauschen erster Ordnung anzugeben:
Opt = procestOptions;
Opt.DisturbanceModel = 'ARMA1';
midproc2 = procest(Ze1,midproc0,Opt);
Sie können 'dist' anstelle von 'DisturbanceModel' angeben. Bei Eigenschaftennamen muss die Groß-/Kleinschreibung nicht beachtet werden und Sie müssen nur den Teil des Namens angeben, der die Eigenschaft eindeutig identifiziert.
Vergleichen Sie das resultierende Modell mit den gemessenen Daten.
compare(Zv1,midproc2)
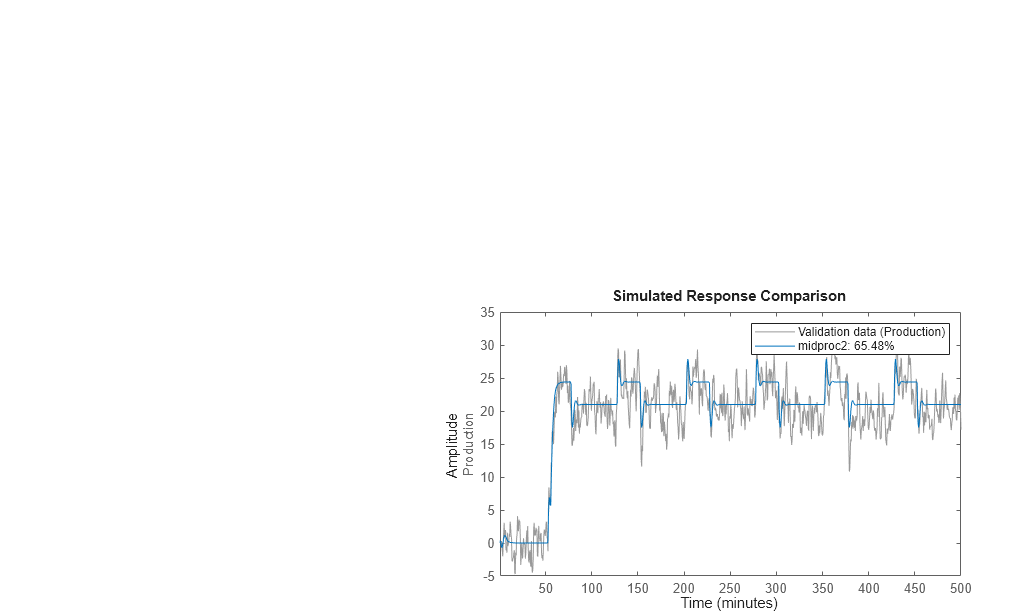
Das Diagramm zeigt, dass der Modellausgang angemessen mit dem Validierungsdatenausgang übereinstimmt.
Schätzung von Black-Box-Polynommodellen
Modellordnungen für die Schätzung von Polynommodellen
In diesem Teil des Tutorials schätzen Sie verschiedene Typen von Black-Box-, Eingangs-/Ausgangs-Polynommodellen.
Sie müssen Ihre Daten bereits vorbereitet haben, wie in Vorbereiten von Daten beschrieben.
Sie können zum Angeben der Ordnungen des Polynommodells die folgenden bisherigen Ergebnisse geschätzter Modellordnungen verwenden:
Verwenden Sie Folgendes für die erste Eingang/Ausgang-Kombination:
Zwei Polstellen, was im ARX-Modell na=2 entspricht.
Eine Nullstelle, was im ARX-Modell nb=2 entspricht.
Einen Verzögerungswert von 5, was im ARX-Modell nk=5 Abtastungen (oder 2,5 Minuten) entspricht.
Verwenden Sie Folgendes für die zweite Eingang/Ausgang-Kombination:
Eine Polstelle, was im ARX-Modell na=1 entspricht.
Keine Nullstellen, was im ARX-Modell nb=1 entspricht.
Einen Verzögerungswert von 10, was im ARX-Modell nk=10 Abtastungen (oder 5 Minuten) entspricht.
Schätzung eines linearen ARX-Modells
Infos zu ARX-Modellen. Für ein Single-Input/Single-Output-(SISO-)System lautet die Struktur des ARX-Modells wie folgt:
y(t) steht dabei für den Ausgang zum Zeitpunkt t, u(t) steht für den Eingang zum Zeitpunkt t, na ist die Anzahl der Polstellen, nb ist die Anzahl der Nullstellen plus 1, nk ist die Anzahl der Abtastungen, bevor sich der Eingang auf den Ausgang des Systems auswirkt (die sogenannte Verzögerung oder Totzeit des Modells), und e(t) ist die Störung durch weißes Rauschen.
Die Struktur des ARX-Modells unterscheidet nicht zwischen den Polstellen für einzelne Eingangs-/Ausgangspfade: Wenn Sie die ARX-Gleichung durch A dividieren, was die Polstellen einschließt, wird deutlich, dass A im Nenner für beide Eingänge vorkommt. Daher können Sie na auf die Summe der Polstellen für jedes Eingangs-/Ausgangspaar setzen, also in diesem Fall auf 3.
Das Produkt System Identification Toolbox schätzt die Parameter und mithilfe der von Ihnen angegebenen Daten und Modellordnungen.
Schätzung von ARX-Modellen mithilfe von „arx“. Berechnen Sie mithilfe von arx die Polynomkoeffizienten und verwenden Sie dabei die schnelle, nichtiterative Methode arx:
marx = arx(Ze1,'na',3,'nb',[2 1],'nk',[5 10]); present(marx) % Displays model parameters % with uncertainty information
marx =
Discrete-time ARX model: A(z)y(t) = B(z)u(t) + e(t)
A(z) = 1 - 1.027 (+/- 0.02907) z^-1 + 0.1678 (+/- 0.042) z^-2 + 0.01289 (
+/- 0.02583) z^-3
B1(z) = 1.86 (+/- 0.189) z^-5 - 1.608 (+/- 0.1888) z^-6
B2(z) = 1.612 (+/- 0.07392) z^-10
Sample time: 0.5 minutes
Parameterization:
Polynomial orders: na=3 nb=[2 1] nk=[5 10]
Number of free coefficients: 6
Use "polydata", "getpvec", "getcov" for parameters and their uncertainties.
Status:
Estimated using ARX on time domain data "Ze1".
Fit to estimation data: 90.7% (prediction focus)
FPE: 2.768, MSE: 2.719
More information in model's "Report" property.
MATLAB schätzt die Polynome A, B1 und B2. Die Unsicherheit für jeden der Modellparameter wird bis auf 1 Standardabweichung berechnet und in Klammern neben jedem Parameterwert angegeben.
Alternativ können Sie die folgende Syntax in Kurzschreibweise verwenden, mit der die Modellordnungen als einzelner Vektor angegeben werden:
marx = arx(Ze1,[3 2 1 5 10]);
Zugreifen auf Modelldaten. Das von Ihnen geschätzte Modell, marx, ist ein zeitdiskretes idpoly-Objekt. Sie können die Eigenschaften dieses Modellobjekts mithilfe der Funktion get abrufen:
get(marx)
A: [1 -1.0267 0.1678 0.0129]
B: {[0 0 0 0 0 1.8599 -1.6084] [0 0 0 0 0 0 0 0 0 0 1.6118]}
C: 1
D: 1
F: {[1] [1]}
IntegrateNoise: 0
Variable: 'z^-1'
IODelay: [0 0]
Structure: [1×1 pmodel.polynomial]
NoiseVariance: 2.7436
InputDelay: [2×1 double]
OutputDelay: 0
InputName: {2×1 cell}
InputUnit: {2×1 cell}
InputGroup: [1×1 struct]
OutputName: {'Production'}
OutputUnit: {'mg/min'}
OutputGroup: [1×1 struct]
Notes: [0×1 string]
UserData: []
Name: ''
Ts: 0.5000
TimeUnit: 'minutes'
SamplingGrid: [1×1 struct]
Report: [1×1 idresults.arx]
Sie können auf die in diesen Eigenschaften gespeicherten Informationen mithilfe der Punktschreibweise zugreifen. Beispielsweise können Sie die diskreten Polstellen des Modells durch Suchen nach den Wurzeln des Polynoms A berechnen.
marx_poles = roots(marx.a)
marx_poles =
0.7953
0.2877
-0.0564
In diesem Fall greifen Sie auf das Polynom A mithilfe von marx.a zu.
Das Modell marx beschreibt die Systemdynamiken mit drei diskreten Polstellen.
Tipp
Sie können auch pole verwenden, um die Polstellen eines Modells direkt zu berechnen.
Weitere Informationen. Ausführliche Informationen zur Schätzung von Polynommodellen finden Sie unter Eingangs-/Ausgangs-Polynommodelle.
Weitere Informationen zum Zugreifen auf Modelldaten finden Sie unter Datenextraktion.
Schätzung von Zustandsraummodellen
Infos zu Zustandsraummodellen. Die allgemeine Struktur eines Zustandsraummodells sieht wie folgt aus:
y(t) steht dabei für den Ausgang zum Zeitpunkt t, u(t) steht für den Eingang zum Zeitpunkt t, x(t) ist der Zustandsvektor zum Zeitpunkt t und e(t) ist die Störung durch weißes Rauschen.
Sie müssen zur Schätzung eines Zustandsraummodells eine einzelne Ganzzahl als Modellordnung (Dimension des Zustandsvektors) angeben. Standardmäßig ist die Verzögerung gleich 1.
Das Produkt System Identification Toolbox schätzt die Zustandsraummatrizen A, B, C, D und K mithilfe der von Ihnen angegebenen Modellordnung und Daten.
Die Struktur des Zustandsraummodells eignet sich gut für schnelle Schätzungen, weil sie nur zwei Parameter umfasst: n ist die Anzahl der Polstellen (die Größe der Matrix A) und nk ist die Verzögerung.
Schätzung von Zustandsraummodellen mithilfe von „n4sid“. Verwenden Sie den Befehl n4sid, um einen Bereich von Modellordnungen anzugeben und die Leistung verschiedener Zustandsraummodelle (Ordnungen 2 bis 8) auszuwerten:
mn4sid = n4sid(Ze1,2:8,'InputDelay',[4 9]);Dieser Befehl verwendet die schnelle, nichtiterative (Unterraum-)Methode und öffnet das folgende Diagramm. Sie verwenden dieses Diagramm, um festzulegen, welche Zustände einen signifikanten relativen Beitrag zum Eingang/Ausgang-Verhältnis leisten und welche Zustände den kleinsten Beitrag leisten.

Die vertikale Achse ist ein relatives Maß dafür, wie viel jeder Zustand zum Eingang/Ausgang-Verhältnis des Modells beiträgt (Logarithmus der Singulärwerte der Kovarianzmatrix). Die horizontale Achse entspricht der Modellordnung n. Dieses Diagramm empfiehlt n=3, angegeben durch ein rotes Rechteck.
Das Ordnungsfeld Chosen Order (Ausgewählte Ordnung) zeigt standardmäßig die empfohlene Modellordnung, in diesem Fall 3. Sie können die Ordnungsauswahl über die Dropdown-Liste Chosen Order ändern. Wenden Sie den Wert im Feld Chosen Order an und schließen Sie das Fenster für die Ordnungsauswahl, indem Sie auf Apply (Anwenden) klicken.
Standardmäßig verwendet n4sid eine freie Parametrierung der Zustandsraumform. Soll stattdessen eine kanonische Form geschätzt werden, setzen Sie den Wert der Eigenschaft SSParameterization auf 'Canonical'. Mithilfe der Eigenschaft 'InputDelay' können Sie auch die Eingang-zu- Ausgang-Verzögerung (in Abtastungen) angeben.
mCanonical = n4sid(Ze1,3,'SSParameterization','canonical','InputDelay',[4 9]); present(mCanonical); % Display model properties
mCanonical =
Discrete-time identified state-space model:
x(t+Ts) = A x(t) + B u(t) + K e(t)
y(t) = C x(t) + D u(t) + e(t)
A =
x1 x2 x3
x1 0 1 0
x2 0 0 1
x3 0.0737 +/- 0.05919 -0.6093 +/- 0.1626 1.446 +/- 0.1287
B =
ConsumptionR Current
x1 1.844 +/- 0.175 0.5633 +/- 0.122
x2 1.063 +/- 0.1673 2.308 +/- 0.1222
x3 0.2779 +/- 0.09615 1.878 +/- 0.1058
C =
x1 x2 x3
Production 1 0 0
D =
ConsumptionR Current
Production 0 0
K =
Production
x1 0.8674 +/- 0.03169
x2 0.6849 +/- 0.04145
x3 0.5105 +/- 0.04352
Input delays (sampling periods): 4 9
Sample time: 0.5 minutes
Parameterization:
CANONICAL form with indices: 3.
Feedthrough: none
Disturbance component: estimate
Number of free coefficients: 12
Use "idssdata", "getpvec", "getcov" for parameters and their uncertainties.
Status:
Estimated using N4SID on time domain data "Ze1".
Fit to estimation data: 91.39% (prediction focus)
FPE: 2.402, MSE: 2.331
More information in model's "Report" property.
Hinweis
mn4sid und mCanonical sind zeitdiskrete Modelle. Zum Schätzen eines zeitkontinuierlichen Modells setzen Sie die Eigenschaft 'Ts' im Schätzbefehl auf 0 oder verwenden Sie den Befehl ssest:
mCT1 = n4sid(Ze1, 3, 'Ts', 0, 'InputDelay', [2.5 5]) mCT2 = ssest(Ze1, 3,'InputDelay', [2.5 5])
Weitere Informationen. Weitere Informationen zum Schätzen von Zustandsraummodellen finden Sie unter Zustandsraummodelle.
Schätzung eines Box-Jenkins-Modells
Infos zu Box-Jenkins-Modellen. Die allgemeine Box-Jenkins-(BJ-)Struktur sieht wie folgt aus:
Zum Schätzen eines BJ-Modells müssen Sie die Parameter nb, nf, nc, nd und nk angeben.
Während die Struktur des ARX-Modells nicht zwischen den Polstellen für einzelne Eingangs-/Ausgangspfade unterscheidet, ist das BJ-Modell flexibler, da es die Polstellen und Nullstellen der Störung unabhängig von den Polstellen und Nullstellen der Systemdynamiken modelliert.
Schätzung eines BJ-Modells mithilfe von polyest. Sie können das BJ-Modell mithilfe von polyest schätzen. polyest ist eine iterative Methode und weist die folgende allgemeine Syntax auf:
polyest(data,[na nb nc nd nf nk]);
Geben Sie zum Schätzen des BJ-Modells Folgendes ein:
na = 0; nb = [ 2 1 ]; nc = 1; nd = 1; nf = [ 2 1 ]; nk = [ 5 10]; mbj = polyest(Ze1,[na nb nc nd nf nk]);
Dieser Befehl gibt nf=2, nb=2, nk=5 für den ersten Eingang und nf=nb=1 sowie nk=10 für den zweiten Eingang an.
Zeigen Sie die Modellinformationen an.
present(mbj)
mbj =
Discrete-time BJ model: y(t) = [B(z)/F(z)]u(t) + [C(z)/D(z)]e(t)
B1(z) = 1.823 (+/- 0.1792) z^-5 - 1.315 (+/- 0.2367) z^-6
B2(z) = 1.791 (+/- 0.06431) z^-10
C(z) = 1 + 0.1068 (+/- 0.04009) z^-1
D(z) = 1 - 0.7452 (+/- 0.02694) z^-1
F1(z) = 1 - 1.321 (+/- 0.06936) z^-1 + 0.5911 (+/- 0.05514) z^-2
F2(z) = 1 - 0.8314 (+/- 0.006441) z^-1
Sample time: 0.5 minutes
Parameterization:
Polynomial orders: nb=[2 1] nc=1 nd=1 nf=[2 1]
nk=[5 10]
Number of free coefficients: 8
Use "polydata", "getpvec", "getcov" for parameters and their uncertainties.
Status:
Termination condition: Near (local) minimum, (norm(g) < tol)..
Number of iterations: 6, Number of function evaluations: 13
Estimated using POLYEST on time domain data "Ze1".
Fit to estimation data: 90.75% (prediction focus)
FPE: 2.733, MSE: 2.689
More information in model's "Report" property.
Die Unsicherheit für jeden der Modellparameter wird bis auf 1 Standardabweichung berechnet und in Klammern neben jedem Parameterwert angegeben.
Die Polynome C und D geben Zähler bzw. Nenner des Rauschmodells an.
Tipp
Alternativ können Sie die folgende Syntax in Kurzschreibweise verwenden, mit der die Ordnungen als einzelner Vektor angegeben werden:
mbj = bj(Ze1,[2 1 1 1 2 1 5 10]);
bj ist eine Version von polyest, die eigens für die Schätzung der BJ-Modellstruktur vorgesehen ist.
Weitere Informationen. Ausführliche Informationen zum Identifizieren von Eingangs-/Ausgangs-Polynommodellen wie BJ finden Sie unter Eingangs-/Ausgangs-Polynommodelle.
Vergleichen des Modellausgangs mit dem gemessenen Ausgang
Vergleichen Sie den Ausgang der ARX-, Zustandsraum- und Box-Jenkins-Modelle mit dem gemessenen Ausgang.
compare(Zv1,marx,mn4sid,mbj)
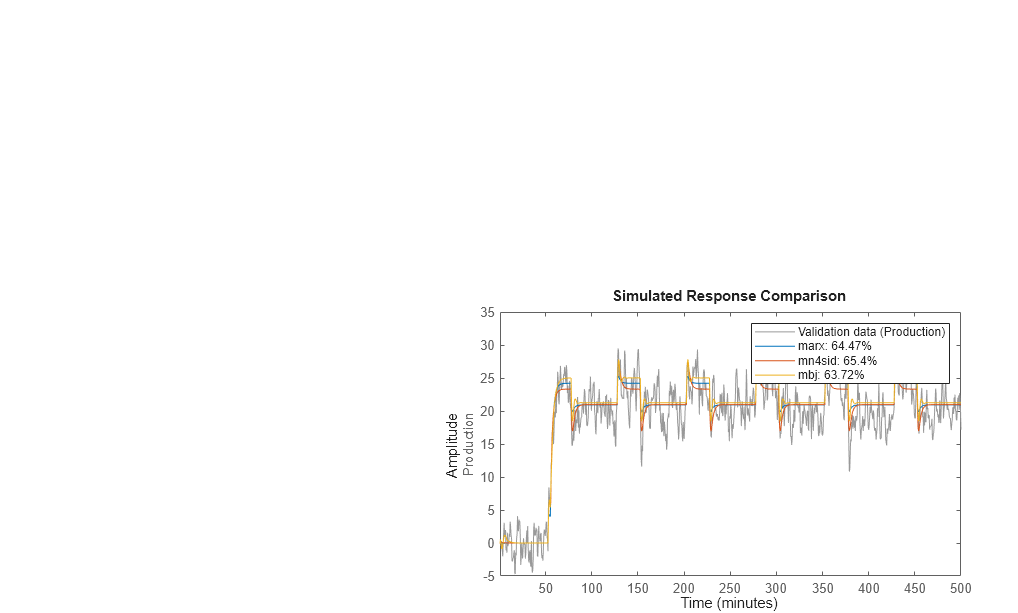
Mit compare wird der gemessene Ausgang im Validierungsdatensatz im Vergleich zum simulierten Ausgang der Modelle geplottet. Die Eingangsdaten der Validierungsdatensätze dienen als Eingänge für die Modelle.
Führen Sie eine Residuenanalyse für die ARX-, Zustandsraum- und Box-Jenkins-Modelle aus.
resid(Zv1,marx,mn4sid,mbj)
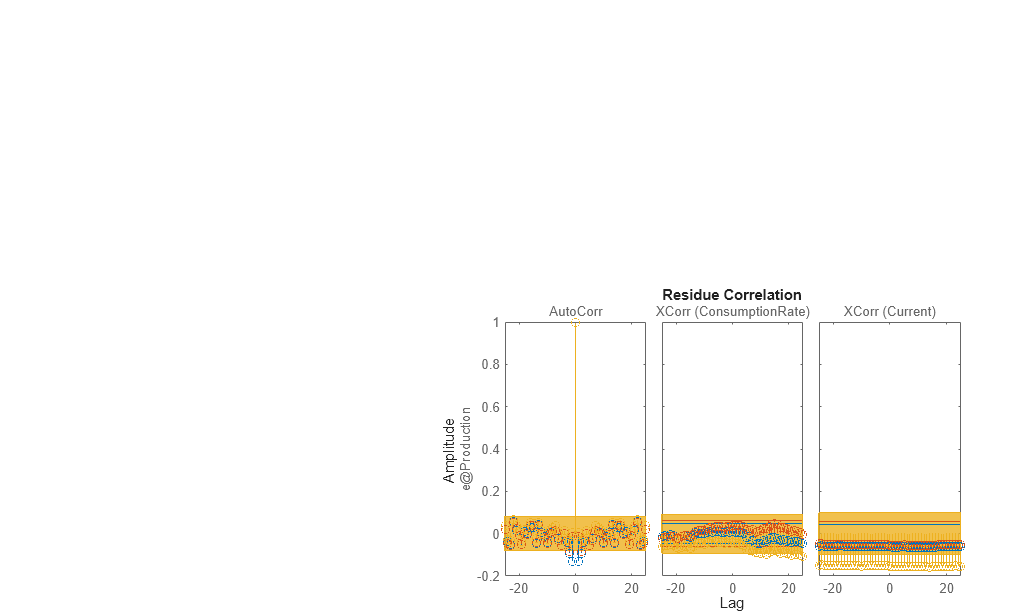
Alle drei Modelle simulieren den Ausgang gleich gut und weisen unkorrelierte Residuen auf. Wählen Sie daher das ARX-Modell aus, weil es das einfachste der drei Eingangs-/Ausgangs-Polynommodelle ist und die Prozessdynamik angemessen erfasst.
Simulieren und Vorhersagen des Modellausgangs
Simulation des Modellausgangs
In diesem Teil des Tutorials simulieren Sie den Modellausgang. Sie müssen das zeitkontinuierliche Modell midproc2 bereits erstellt haben, wie in Schätzung von Prozessmodellen beschrieben.
Für die Simulation des Modellausgangs sind folgende Informationen erforderlich:
Eingangswerte für das Modell
Anfangsbedingungen für die Simulation (auch Anfangszustände genannt)
Die folgenden Befehle verwenden beispielsweise die Befehle iddata und idinput, um einen Eingangsdatensatz zu erstellen, und sim, um den Modellausgang zu simulieren:
% Create input for simulation U = iddata([],idinput([200 2]),'Ts',0.5,'TimeUnit','min'); % Simulate the response setting initial conditions equal to zero ysim_1 = sim(midproc2,U);
Zur Maximierung der Übereinstimmung zwischen der simulierten Antwort eines Modells mit dem gemessenen Ausgang für denselben Eingang können Sie die Anfangsbedingungen berechnen, die den gemessenen Daten entsprechen. Die am besten passenden Anfangsbedingungen können abgerufen werden, indem Sie den Befehl findstates für die Zustandsraumversion des geschätzten Modells ausführen. Mit den folgenden Befehlen werden die Anfangszustände X0est anhand des Datensatzes Zv1 geschätzt:
Vorhersagen des zukünftigen Ausgangs
Viele Anwendungen zur Steuerungsentwicklung erfordern die Vorhersage zukünftiger Ausgänge eines dynamischen Systems anhand der zuvor erfassten Eingangs-/Ausgangsdaten.
Verwenden Sie beispielsweise predict, um die Modellantwort für fünf Schritte im Voraus vorherzusagen:
predict(midproc2,Ze1,5)
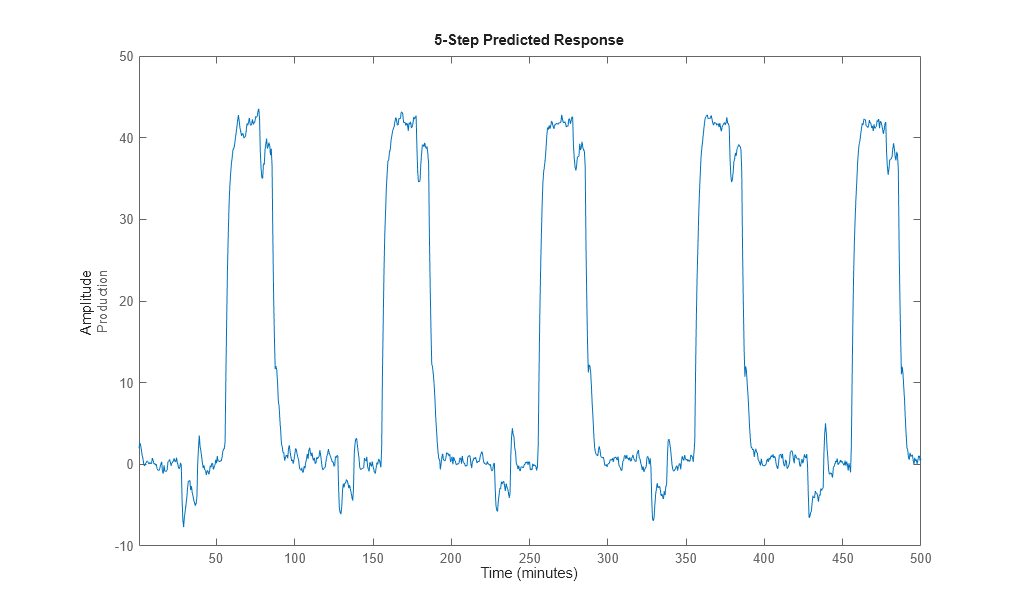
Verwenden Sie pe, um den Vorhersagefehler Err zwischen dem vorhergesagten Ausgang von midproc2 und dem gemessenen Ausgang zu berechnen. Anschließend plotten Sie das Fehlerspektrum mithilfe des Befehls spectrum.