Diese Seite ist für die vorige Version. Die entsprechende englische Seite wurde in der aktuellen Version entfernt.
Zeitreihenvorhersage und Modellierung mit flachen neuronalen Netzen
Dynamische neuronale Netze eignen sich gut für die Zeitreihenvorhersage. Beispiele für die Verwendung von NARX-Netzen, die in mehrstufigen Vorhersagen mit offener Schleife, geschlossener Schleife und offener/geschlossener Schleife angewandt werden, finden Sie unter .
Tipp
Informationen zu Deep Learning mithilfe von Zeitreihendaten finden Sie dagegen unter Sequenz-Klassifizierung mithilfe von Deep Learning.
Angenommen, Ihnen liegen Daten aus einem Verfahren zur Neutralisierung des pH-Werts vor. Sie möchten ein Netz entwickeln, das den pH-Wert einer Lösung in einem Tank anhand von Vergangenheitswerten für den pH-Wert und Vergangenheitswerten der Säure- und Basenflussgeschwindigkeit in den Tank vorhersagen kann. Es gibt insgesamt 2001 Zeitschritte, für die Ihnen diese Reihen vorliegen.
Es gibt zwei Möglichkeiten, dieses Problem zu lösen:
Verwendung der App Neural Net Time Series wie in Anpassen von Zeitreihendaten mithilfe der App „Neural Net Time Series“ beschrieben.
Verwendung von Befehlszeilenfunktionen wie in Anpassen von Zeitreihendaten mithilfe von Befehlszeilenfunktionen beschrieben.
Tipp
Zum interaktiven Erstellen und Visualisieren neuronaler Deep-Learning-Netze verwenden Sie die App Deep Network Designer. Weitere Informationen finden Sie unter Erste Schritte mit Deep Network Designer.
Im Allgemeinen ist es am besten, mit der App zu beginnen und diese anschließend zum automatischen Generieren von Befehlszeilenskripten zu verwenden. Bevor Sie eine der beiden Methoden anwenden, definieren Sie zunächst das Problem, indem Sie einen Datensatz auswählen. Jede der Apps zur Entwicklung neuronaler Netze hat Zugang zu verschiedenen Beispieldatensätzen, die Sie zum Experimentieren mit der Toolbox verwenden können (siehe Beispieldatensätze für flache neuronale Netze). Wenn Sie ein bestimmtes Problem lösen möchten, können Sie auch Ihre eigenen Daten in den Workspace laden.
Zeitreihennetze
Sie können ein neuronales Netz für die Lösung dreier Arten von Zeitreihenproblemen trainieren.
Hinweis
Sie können die System Identification Toolbox™ verwenden, um ein flexibleres NARX-Modell zu entwickeln.
NARX-Netz
Bei der ersten Art von Zeitreihenproblem möchten Sie Zukunftswerte einer Zeitreihe y(t) anhand von Vergangenheitswerten dieser Zeitreihe und Vergangenheitswerten einer zweiten Zeitreihe x(t) vorhersagen. Diese Form der Vorhersage wird als nichtlinear autoregressiv mit exogenem (externem) Eingang, kurz NARX (Nonlinear AutoRegressive with eXogenous input), siehe , bezeichnet und kann wie folgt geschrieben werden:
y(t) = f(y(t – 1), ..., y(t – d), x(t – 1), ...,x(t – d))
Verwenden Sie dieses Modell, um Zukunftswerte einer Aktie oder Anleihe basierend auf Wirtschaftsvariablen wie Arbeitslosenquoten, BIP usw. vorherzusagen. Sie können dieses Modell auch für die Systemidentifizierung verwenden, bei der Modelle zur Darstellung dynamischer Systeme entwickelt werden, z. B. chemische Prozesse, Fertigungssysteme, Robotik, Luft- und Raumfahrzeuge usw.
NAR-Netz
Bei der zweiten Art von Zeitreihenproblem wird nur eine Reihe berücksichtigt. Die Zukunftswerte einer Zeitreihe y(t) werden ausschließlich aus Vergangenheitswerten dieser Reihe vorhergesagt. Diese Form der Vorhersage wird als nichtlinear autoregressiv, kurz NAR (Nonlinear AutoRegressive), bezeichnet und kann wie folgt geschrieben werden:
y(t) = f(y(t – 1), ..., y(t – d))
Sie können dieses Modell für die Vorhersage von Finanzinstrumenten verwenden, allerdings ohne Verwendung einer Begleitreihe.
Nichtlineares Eingangs-/Ausgangsnetz
Das dritte Zeitreihenproblem ähnelt der ersten Problemart, da auch hier zwei Reihen berücksichtigt werden: eine Eingangsreihe x(t) und eine Ausgangsreihe y(t). Hier möchten Sie Werte von y(t) aus vorherigen Werten von x(t) vorhersagen, ohne jedoch die vorherigen Werte von y(t) zu kennen. Dieses Eingangs-/Ausgangsmodell kann wie folgt geschrieben werden:
y(t) = f(x(t – 1), ..., x(t – d))
Das NARX-Modell wird bessere Vorhersagen bereitstellen als dieses Eingangs-/Ausgangsmodell, da es die zusätzlichen Informationen verwendet, die in den vorherigen Werten von y(t) enthalten sind. Es gibt jedoch möglicherweise einige Anwendungen, in denen die vorherigen Werte von y(t) nicht verfügbar sind. Dies sind die einzigen Fälle, bei denen Sie das Eingangs-/Ausgangsmodell dem NARX-Modell vorziehen würden.
Definieren eines Problems
Zur Definition eines Zeitreihenproblems für die Toolbox ordnen Sie eine Menge von Zeitreihen-Prädiktorvektoren als Spalten in einem Zellenarray an. Stellen Sie anschließend eine weitere Menge von Zeitreihen-Antwortvektoren (die richtigen Antwortvektoren für die jeweiligen Prädiktorvektoren) in einem zweiten Zellenarray zusammen. Darüber hinaus gibt es Fälle, für die nur ein Antwortdatensatz erforderlich ist. Beispielsweise können Sie das folgende Zeitreihenproblem definieren, für das Sie vorherige Werte einer Reihe zur Vorhersage des nächsten Werts verwenden möchten:
responses = {1 2 3 4 5};
Der nächste Abschnitt zeigt, wie ein Netz mithilfe der App Neural Net Time Series für das Anpassen eines Zeitreihen-Datensatzes trainiert wird. In diesem Beispiel werden Beispieldaten verwendet, die mit der Toolbox bereitgestellt werden.
Anpassen von Zeitreihendaten mithilfe der App „Neural Net Time Series“
Dieses Beispiel veranschaulicht, wie ein flaches neuronales Netz mithilfe der App Neural Net Time Series für das Anpassen von Zeitreihendaten trainiert werden kann.
Öffnen Sie die App Neural Net Time Series mithilfe des Befehls ntstool.
ntstool
Auswählen des Netzes
Mithilfe der App Neural Net Time Series können Sie drei verschiedene Arten von Zeitreihenproblemen lösen.
Bei der ersten Art von Zeitreihenproblem möchten Sie Zukunftswerte einer Zeitreihe anhand von Vergangenheitswerten dieser Zeitreihe und Vergangenheitswerten einer zweiten Zeitreihe vorhersagen. Für diese Form der Vorhersage wird ein nichtlineares autoregressives Netz mit exogenem (externem) Eingang, kurz NARX (Nonlinear AutoRegressive with eXogenous input), verwendet.
Bei der zweiten Art von Zeitreihenproblem wird nur eine Reihe berücksichtigt. Die Zukunftswerte einer Zeitreihe werden ausschließlich aus Vergangenheitswerten dieser Reihe vorhergesagt. Diese Form der Vorhersage wird als nichtlinear autoregressiv, kurz NAR (Nonlinear AutoRegressive), bezeichnet.
Das dritte Zeitreihenproblem ähnelt der ersten Problemart, da auch hier zwei Reihen berücksichtigt werden: eine Eingangsreihe (Prädiktoren) und eine Ausgangsreihe (Antworten) . Hier möchten Sie Werte von aus vorherigen Werten von vorhersagen, ohne jedoch die vorherigen Werte von zu kennen.
Für dieses Beispiel verwenden Sie ein NARX-Netz. Klicken Sie auf Select Network > NARX Network.

Auswählen der Daten
Die App Neural Net Time Series enthält Beispieldaten, die Ihnen den Einstieg in das Training eines neuronalen Netzes erleichtern.
Wählen Sie zum Importieren von Beispieldaten eines Prozesses zur Neutralisierung des pH-Werts Import > More Example Data Sets (Weitere Beispieldatensätze) > Import pH Neutralization Data Set (Datensatz pH-Wert-Neutralisierung importieren) aus. Mit diesem Datensatz können Sie ein neuronales Netz trainieren, das anhand der Durchflussrate einer Säure- und Basenlösung den pH-Wert einer Lösung vorhersagt. Wenn Sie Ihre eigenen Daten aus einer Datei oder aus dem Workspace importieren, müssen Sie die Prädiktoren und Antworten angeben.
Informationen über die importierten Daten werden im Fenster Model Summary (Modellzusammenfassung) angezeigt. Dieser Datensatz enthält 2001 Zeitschritte. Die Prädiktoren weisen zwei Merkmale auf (Durchfluss der Säure- und Basenlösungen), die Antworten weisen ein einzelnes Merkmal auf (pH-Wert der Lösung).

Unterteilen Sie die Daten in Trainings-, Validierungs- und Testdatensätze. Behalten Sie die Standardeinstellungen bei. Die Daten sind wie folgt unterteilt:
70 % für das Training.
15 % für die Validierung, um festzustellen, ob das Netz generalisiert, und um das Training zu stoppen, bevor es zu einer Überanpassung kommt.
15 %, um unabhängig zu testen, ob das Netz generalisiert.
Weitere Informationen zur Datenunterteilung finden Sie unter .
Erstellen des Netzes
Das Standard-NARX-Netz ist ein zweischichtiges vorwärtsgerichtetes Netz (auch: Feedforward-Netz) mit einer Sigmoid-Transferfunktion in der verborgenen Schicht und einer linearen Transferfunktion in der Ausgangsschicht. Dieses Netz verwendet auch gekoppelte Verzögerungslinien, um Vergangenheitswerte der Sequenzen und zu speichern. Beachten Sie, dass der Ausgang des NARX-Netzes, , in den Eingang des Netzes rückgekoppelt wird (durch Verzögerungen), da eine Funktion von ist. Für ein effizientes Training kann diese Rückkopplungsschleife jedoch geöffnet werden.
Da der wahre Ausgang während des Trainings des Netzes zur Verfügung steht, können Sie die unten abgebildete Architektur mit offener Schleife verwenden, bei der anstelle der Rückkopplung des geschätzten Ausgangs der wahre Ausgang verwendet wird. Dies hat zwei Vorteile. Erstens ist der Eingang zum vorwärtsgerichteten Netz wesentlich genauer. Zweitens weist das resultierende Netz eine reine vorwärtsgerichtete Architektur auf, weshalb für das Training ein effizienterer Algorithmus verwendet werden kann. Dieses Netz wird in genauer erläutert.
Der Wert für Layer size (Schichtgröße) definiert die Anzahl der verborgenen Neuronen. Behalten Sie die Standardschichtgröße, 10, bei. Ändern Sie den Wert für Time delay (Zeitverzögerung) in 4. Vielleicht möchten Sie diese Zahlen anpassen, wenn die Leistung des Netztrainings schlecht ist.
Die Netzarchitektur wird im Fensterbereich Network angezeigt.

Trainieren des Netzes
Wählen Sie zum Trainieren des Netzes Train > Train with Levenberg-Marquardt aus. Dies ist der Standard-Trainingsalgorithmus. Er ist identisch mit dem Algorithmus, der beim Klicken auf Train verwendet wird.
Das Training mit „Levenberg-Marquardt“ (trainlm) wird für die meisten Probleme empfohlen. Für rauschbehaftete oder kleine Probleme erzielen Sie mit „Bayesian Regularization“ (trainbr) möglicherweise bessere Ergebnisse, allerdings dauert das Training damit länger. Für große Probleme wird „Scaled Conjugate Gradient“ (trainscg) empfohlen, weil dieser Algorithmus Gradientenberechnungen verwendet, die speichereffizienter sind als die Jacobi-Berechnungen, die von den beiden anderen Algorithmen verwendet werden.
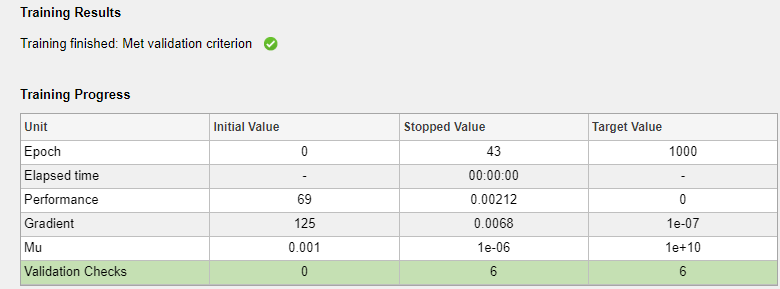
Im Fensterbereich Training wird der Trainingsfortschritt angezeigt. Das Training wird so lange fortgesetzt, bis eines der Stoppkriterien erfüllt ist. In diesem Beispiel wird das Training so lange fortgesetzt, bis der Validierungsfehler größer oder gleich dem zuvor kleinsten Validierungsfehler für sechs aufeinanderfolgende Validierungsiterationen ist („Validierungskriterium erfüllt“).
Analysieren der Ergebnisse
Die Modellzusammenfassung enthält Informationen zum Trainingsalgorithmus und zu den Trainingsergebnissen für die einzelnen Datensätze.

Sie können die Ergebnisse weiter analysieren, indem Sie Diagramme generieren. Zum Darstellen der Autokorrelation der Fehler klicken Sie im Abschnitt Plots (Diagramme) auf Error Autocorrelation (Autokorrelation der Fehler). Das Autokorrelationsdiagramm beschreibt, wie die Vorhersagefehler zeitlich zusammenhängen. Für ein perfektes Vorhersagemodell sollte nur ein Wert der Autokorrelationsfunktion ungleich null vorliegen und er sollte mit Nullverzögerung auftreten (hierbei handelt es sich um die mittlere quadratische Abweichung). Dies würde bedeuten, dass die Vorhersagefehler untereinander völlig unzusammenhängend wären (weißes Rauschen). Läge in den Vorhersagefehlern eine signifikante Korrelation vor, sollte es möglich sein, die Vorhersage zu verbessern – vielleicht durch Erhöhung der Anzahl von Verzögerungen in den gekoppelten Verzögerungslinien. In diesem Fall liegen die Korrelationen, mit Ausnahme derjenigen bei der Nullverzögerung, in etwa innerhalb der 95-%-Konfidenzgrenzen um null, sodass das Modell angemessen zu sein scheint. Wenn noch genauere Ergebnisse benötigt würden, könnten Sie das Netz neu trainieren. Dadurch ändern sich die Anfangsgewichtungen und -verzerrungen des Netzes und möglicherweise entsteht nach einem Neutraining ein verbessertes Netz.

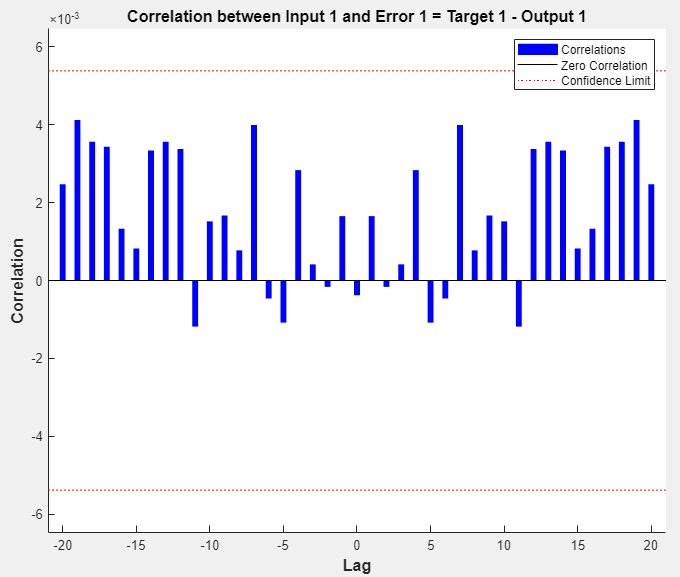
Sehen Sie sich das Kreuzkorrelationsdiagramm der Eingangsfehler an, um die Leistung des Netzes zusätzlich zu überprüfen. Klicken Sie im Abschnitt Plots (Diagramme) auf Input-Error Correlation (Eingangsfehlerkorrelation). Das Diagramm mit der Kreuzkorrelation der Eingangsfehler veranschaulicht, wie die Fehler in der Eingangssequenz korreliert sind. Für ein perfektes Vorhersagemodell sollten alle Korrelationen gleich null sein. Wenn der Eingang mit dem Fehler korreliert, sollte es möglich sein, die Vorhersage zu verbessern – vielleicht durch Erhöhung der Anzahl von Verzögerungen in den gekoppelten Verzögerungslinien. In diesem Fall liegen die meisten Korrelationen innerhalb der Konfidenzgrenzen um null.
Klicken Sie im Abschnitt Plots (Diagramme) auf Response (Antwort). Dadurch werden die Ausgänge, Antworten (Ziele) und Fehler abhängig von der Zeit angezeigt. Außerdem wird angegeben, welche Zeitpunkte für das Training, die Tests und die Validierung ausgewählt wurden.

Wenn Sie mit der Leistung des Netzes nicht zufrieden sind, können Sie eine der folgenden Möglichkeiten nutzen:
Trainieren Sie das Netz neu.
Erhöhen Sie die Anzahl der verborgenen Neuronen.
Verwenden Sie einen größeren Trainingsdatensatz.
Wenn die Trainingsdaten zu einer guten Leistung führt, die Testdaten jedoch nicht, könnte dies auf eine Überanpassung des Modells hinweisen. Durch eine Verringerung der Schichtgröße, und daher auch der Anzahl der Neuronen, kann die Überanpassung reduziert werden.
Sie können die Leistung des Netzes auch anhand eines zusätzlichen Testdatensatzes beurteilen. Um zusätzliche Testdaten zur Beurteilung des Netzes zu laden, klicken Sie im Abschnitt Test auf Test. In der Modellzusammenfassung werden die zusätzlichen Testdatenergebnisse angezeigt. Sie können auch Diagramme generieren, um die zusätzlichen Testdatenergebnisse zu analysieren.
Generieren von Code
Wählen Sie Generate Code > Generate Simple Training Script (Einfaches Trainingsskript generieren) aus, um MATLAB-Programmcode zu erstellen, mit dem die vorherigen Schritte über die Befehlszeile reproduziert werden können. Das Erstellen von MATLAB-Programmcode kann hilfreich sein, wenn Sie lernen möchten, wie die Befehlszeilenfunktionen der Toolbox zum Anpassen des Trainingsprozesses genutzt werden können. In Anpassen von Zeitreihendaten mithilfe von Befehlszeilenfunktionen werden Sie die generierten Skripte näher untersuchen.
Exportieren des Netzes
Sie können Ihr trainiertes Netz in den Workspace oder nach Simulink® exportieren. Sie können das Netz auch mit den Tools von MATLAB Compiler™ und anderen MATLAB-Tools zur Codegenerierung bereitstellen. Wählen Sie zum Exportieren Ihres trainierten Netzes und der Ergebnisse die Optionen Export Model > Export to Workspace (In den Workspace exportieren) aus.
Anpassen von Zeitreihendaten mithilfe von Befehlszeilenfunktionen
Die einfachste Möglichkeit, den Umgang mit den Befehlszeilenfunktionen der Toolbox zu erlernen, besteht darin, mithilfe der Apps Skripte zu generieren und diese anschließend abzuändern, um das Netztraining individuell anzupassen. Sehen Sie sich als Beispiel das einfache Skript an, das im vorherigen Abschnitt mithilfe der App Neural Net Time Series generiert wurde.
% Solve an Autoregression Problem with External Input with a NARX Neural Network % Script generated by Neural Time Series app % Created 13-May-2021 17:34:27 % % This script assumes these variables are defined: % % phInputs - input time series. % phTargets - feedback time series. X = phInputs; T = phTargets; % Choose a Training Function % For a list of all training functions type: help nntrain % 'trainlm' is usually fastest. % 'trainbr' takes longer but may be better for challenging problems. % 'trainscg' uses less memory. Suitable in low memory situations. trainFcn = 'trainlm'; % Levenberg-Marquardt backpropagation. % Create a Nonlinear Autoregressive Network with External Input inputDelays = 1:4; feedbackDelays = 1:4; hiddenLayerSize = 10; net = narxnet(inputDelays,feedbackDelays,hiddenLayerSize,'open',trainFcn); % Prepare the Data for Training and Simulation % The function PREPARETS prepares timeseries data for a particular network, % shifting time by the minimum amount to fill input states and layer % states. Using PREPARETS allows you to keep your original time series data % unchanged, while easily customizing it for networks with differing % numbers of delays, with open loop or closed loop feedback modes. [x,xi,ai,t] = preparets(net,X,{},T); % Setup Division of Data for Training, Validation, Testing net.divideParam.trainRatio = 70/100; net.divideParam.valRatio = 15/100; net.divideParam.testRatio = 15/100; % Train the Network [net,tr] = train(net,x,t,xi,ai); % Test the Network y = net(x,xi,ai); e = gsubtract(t,y); performance = perform(net,t,y) % View the Network view(net) % Plots % Uncomment these lines to enable various plots. %figure, plotperform(tr) %figure, plottrainstate(tr) %figure, ploterrhist(e) %figure, plotregression(t,y) %figure, plotresponse(t,y) %figure, ploterrcorr(e) %figure, plotinerrcorr(x,e) % Closed Loop Network % Use this network to do multi-step prediction. % The function CLOSELOOP replaces the feedback input with a direct % connection from the output layer. netc = closeloop(net); netc.name = [net.name ' - Closed Loop']; view(netc) [xc,xic,aic,tc] = preparets(netc,X,{},T); yc = netc(xc,xic,aic); closedLoopPerformance = perform(net,tc,yc) % Step-Ahead Prediction Network % For some applications it helps to get the prediction a timestep early. % The original network returns predicted y(t+1) at the same time it is % given y(t+1). For some applications such as decision making, it would % help to have predicted y(t+1) once y(t) is available, but before the % actual y(t+1) occurs. The network can be made to return its output a % timestep early by removing one delay so that its minimal tap delay is now % 0 instead of 1. The new network returns the same outputs as the original % network, but outputs are shifted left one timestep. nets = removedelay(net); nets.name = [net.name ' - Predict One Step Ahead']; view(nets) [xs,xis,ais,ts] = preparets(nets,X,{},T); ys = nets(xs,xis,ais); stepAheadPerformance = perform(nets,ts,ys)
Sie können das Skript speichern und es anschließend über die Befehlszeile ausführen, um die Ergebnisse der vorherigen App-Sitzung zu reproduzieren. Außerdem können Sie das Skript bearbeiten, um den Trainingsprozess individuell anzupassen. In diesem Fall befolgen Sie die einzelnen Schritte im Skript.
Auswählen der Daten
Im Skript wird davon ausgegangen, dass Prädiktor- und Antwortvektoren bereits in den Workspace geladen wurden. Wenn die Daten noch nicht geladen wurden, können Sie sie wie folgt laden:
load ph_datasetpHInputs und die Antworten pHTargets in den Workspace geladen.Bei diesem Datensatz handelt es sich um einen der Beispieldatensätze, die Teil der Toolbox sind. Informationen zu den verfügbaren Datensätzen finden Sie unter Beispieldatensätze für flache neuronale Netze. Zum Aufrufen einer Liste mit allen verfügbaren Datensätzen geben Sie den Befehl help nndatasets ein. Sie können die Variablen aus jedem dieser Datensätze laden und dabei Ihre eigenen Variablennamen verwenden. Beispielsweise werden mit dem Befehl
[X,T] = ph_dataset;
X und die Antworten des pH-Datensatzes in das Zellenarray T geladen.Auswählen des Trainingsalgorithmus
Definieren Sie den Trainingsalgorithmus. Das Netz verwendet für das Training den Standard-Levenberg-Marquardt-Algorithmus (trainlm).
trainFcn = 'trainlm'; % Levenberg-Marquardt backpropagation.
Bei Problemen, für die der Levenberg-Marquardt-Algorithmus nicht die gewünschten genauen Ergebnisse liefert, oder bei Problemen mit großen Datenmengen sollten Sie die Trainingsfunktion für das Netz mit einem der folgenden Befehle auf „Bayesian Regularization“ (trainbr) bzw. auf „Scaled Conjugate Gradient“ (trainscg) festlegen:
net.trainFcn = 'trainbr'; net.trainFcn = 'trainscg';
Erstellen des Netzes
Erstellen Sie ein Netz. Das NARX-Netz, narxnet, ist ein vorwärtsgerichtetes Netz mit der Tan-Sigmoid-Transferfunktion in der verborgenen Schicht und der linearen Transferfunktion in der Ausgangsschicht. Dieses Netz hat zwei Eingänge. Bei dem einen handelt es sich um einen externen Eingang, der andere ist eine Rückkopplungsverbindung vom Netzausgang. Nachdem das Netz trainiert wurde, kann diese Rückkopplungsverbindung geschlossen werden. Dies wird in einem späteren Schritt veranschaulicht. Für jeden dieser Eingänge gibt es eine gekoppelte Verzögerungslinie zur Speicherung der vorherigen Werte. Um einem NARX-Netz die Netzarchitektur zuzuweisen, müssen Sie neben den Verzögerungen, die den einzelnen gekoppelten Verzögerungslinien zugeordnet sind, auch die Anzahl der verborgenen Neuronenschichten auswählen. In den folgenden Schritten weisen Sie den Eingangsverzögerungen und den Rückkopplungsverzögerungen Werte zwischen 1 und 4 zu und legen die Anzahl der verborgenen Neuronen auf 10 fest.
inputDelays = 1:4;
feedbackDelays = 1:4;
hiddenLayerSize = 10;
net = narxnet(inputDelays,feedbackDelays,hiddenLayerSize,'open',trainFcn);Hinweis
Je höher die Anzahl der Neuronen und die Anzahl der Verzögerungen, desto aufwendiger ist die Berechnung und es kann tendenziell zu einer Überanpassung der Daten kommen, wenn die Zahlen zu hoch festgelegt wurden. Doch das Netz kann auf diese Weise auch komplexere Probleme lösen. Mehr Schichten erfordern mehr Berechnungen, aber ihre Verwendung kann dazu führen, dass das Netz komplexe Probleme effizienter löst. Um mehr als eine verborgene Schicht zu verwenden, geben Sie die Größen der verborgenen Schichten als Elemente eines Arrays im Befehl narxnet ein.
Vorbereiten von Daten für das Training
Bereiten Sie die Daten für das Training vor. Beim Trainieren eines Netzes, das gekoppelte Verzögerungslinien enthält, müssen die Verzögerungen mit Anfangswerten der Prädiktoren und Antworten des Netzes aufgefüllt werden. Der Toolbox-Befehl preparets vereinfacht diesen Prozess. Diese Funktion hat drei Eingangsargumente: das Netz, die Prädiktoren und die Antworten. Die Funktion gibt neben den Anfangsbedingungen, die erforderlich sind, um die gekoppelten Verzögerungslinien im Netz aufzufüllen, auch abgeänderte Prädiktor- und Antwortsequenzen zurück, für die die Anfangsbedingungen entfernt wurden. Sie können die Funktion wie folgt aufrufen:
[x,xi,ai,t] = preparets(net,X,{},T);Unterteilen der Daten
Legen Sie die Unterteilung der Daten fest.
net.divideParam.trainRatio = 70/100; net.divideParam.valRatio = 15/100; net.divideParam.testRatio = 15/100;
Mit diesen Einstellungen werden die Daten nach dem Zufallsprinzip unterteilt, wobei 70 % für das Training, 15 % für die Validierung und 15 % für das Testen verwendet werden.
Trainieren des Netzes
Trainieren Sie das Netz.
[net,tr] = train(net,x,t,xi,ai);
Während des Trainings ist das folgende Trainingsfenster geöffnet. In diesem Fenster wird der Trainingsfortschritt angezeigt und Sie können das Training jederzeit unterbrechen, indem Sie auf die Stopp-Schaltfläche ![]() klicken.
klicken.
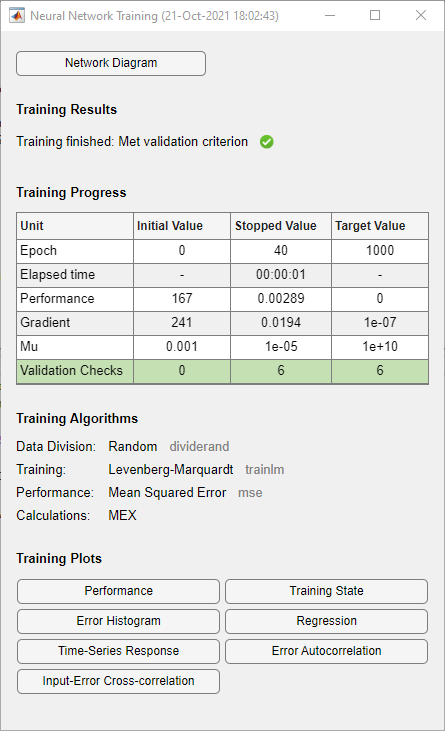
Das Training wurde abgebrochen, wenn der Validierungsfehler größer oder gleich dem zuvor kleinsten Validierungsverlust in sechs aufeinanderfolgenden Validierungsiterationen war.
Testen des Netzes
Testen Sie das Netz. Nachdem das Netz trainiert wurde, können Sie es zur Berechnung der Netzausgänge verwenden. Mit dem folgenden Code werden Netzausgänge, Fehler und Gesamtleistung berechnet. Beachten Sie, dass Sie zur Simulation eines Netzes mit gekoppelten Verzögerungslinien die Anfangswerte für diese verzögerten Signale zuweisen müssen. Hierfür werden die Eingangszustände (xi) und die Schichtzustände (ai) verwendet, die von preparets in einer früheren Phase bereitgestellt wurden.
y = net(x,xi,ai); e = gsubtract(t,y); performance = perform(net,t,y)
performance =
0.0042Anzeigen des Netzes
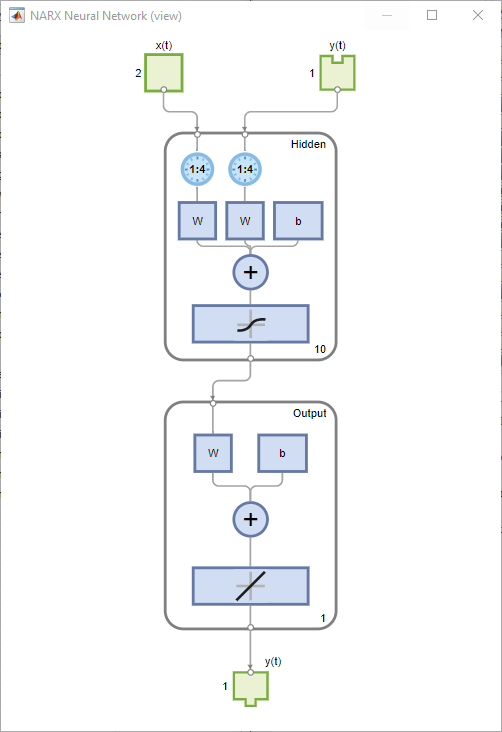
Sehen Sie sich das Netzdiagramm an.
view(net)
Analysieren der Ergebnisse
Erstellen Sie ein Diagramm des Datensatzes mit der Trainingsleistung, um eine potenzielle Überanpassung festzustellen.
figure, plotperform(tr)
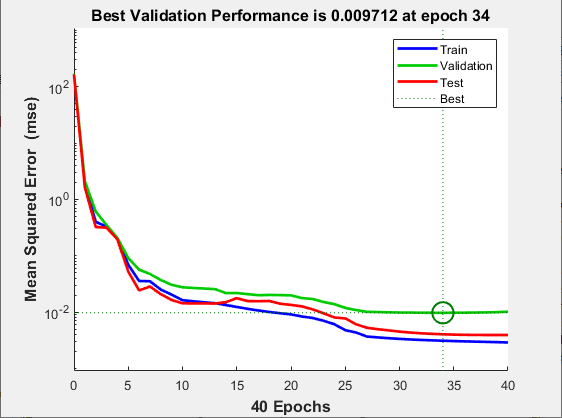
Diese Abbildung veranschaulicht, dass Trainings- und Validierungsfehler bis zur hervorgehobenen Epoche weniger werden. Es scheint keine Überanpassung zu geben, da der Validierungsfehler vor dieser Epoche nicht ansteigt.
Das gesamte Training erfolgt in einer offenen Schleife (auch Reihen-Parallel-Architektur genannt), einschließlich der Validierungs- und Testschritte. In einem typischen Workflow wird das Netz vollständig in einer offenen Schleife erstellt. Erst wenn es trainiert wurde (dies umfasst die Validierungs- und Testschritte), wird es in eine geschlossene Schleife umgewandelt, um eine Vorhersage in mehreren Schritten zu ermöglichen. Ähnlich werden die R-Werte in der App Neural Net Times Series auf der Grundlage der Trainingsergebnisse in der offenen Schleife berechnet.
Netz mit geschlossener Schleife
Schließen Sie die Schleife am NARX-Netz. Wenn die Rückkopplungsschleife am NARX-Netz geöffnet ist, wird eine Ein-Schritt-Vorhersage ausgeführt. Dabei wird der nächste Wert von y(t) aus vorherigen Werten von y(t) und x(t) vorhergesagt. Bei geschlossener Rückkopplungsschleife kann das Netz für Vorhersagen mehrerer Schritte verwendet werden. Dies liegt daran, dass Vorhersagen von y(t) anstelle tatsächlicher Zukunftswerte von y(t) verwendet werden. Die folgenden Befehle können zum Schließen der Schleife und Berechnen der Leistung mit geschlossener Schleife verwendet werden
netc = closeloop(net);
netc.name = [net.name ' - Closed Loop'];
view(netc)
[xc,xic,aic,tc] = preparets(netc,X,{},T);
yc = netc(xc,xic,aic);
closedLoopPerformance = perform(net,tc,yc)closedLoopPerformance =
0.4014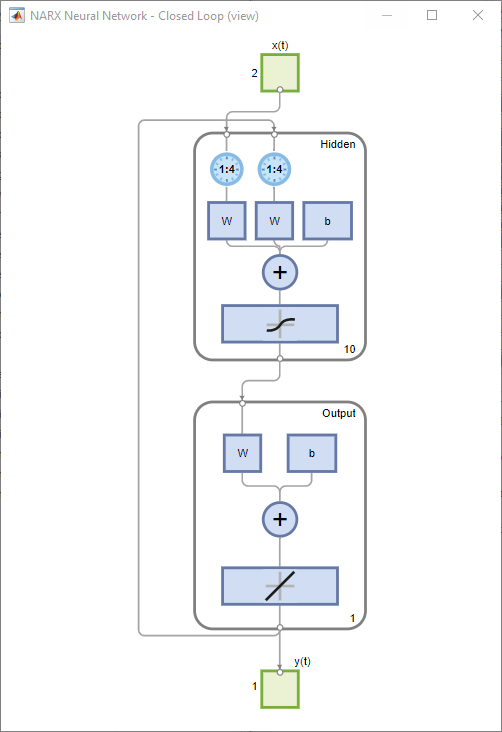
Netz für die Ein-Schritt-Vorhersage
Entfernen Sie eine Verzögerung aus dem Netz, um die Vorhersage einen Zeitschritt früher zu erhalten.
nets = removedelay(net);
nets.name = [net.name ' - Predict One Step Ahead'];
view(nets)
[xs,xis,ais,ts] = preparets(nets,X,{},T);
ys = nets(xs,xis,ais);
stepAheadPerformance = perform(nets,ts,ys)stepAheadPerformance =
0.0042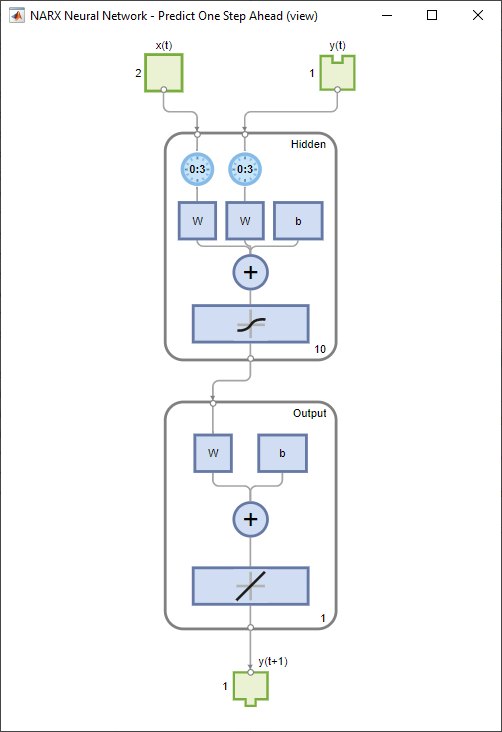
Diese Abbildung zeigt, dass das Netz mit dem vorherigen Netz mit offener Schleife identisch ist, außer dass eine Verzögerung von jeder der gekoppelten Verzögerungslinien entfernt wurde. Der Ausgang des Netzes ist also y(t + 1) und nicht y(t). Dies kann manchmal hilfreich sein, wenn ein Netz für bestimmte Anwendungen bereitgestellt wird.
Weitere Schritte
Wenn die Netzleistung nicht zufriedenstellend ist, können Sie einen der folgenden Ansätze ausprobieren:
Setzen Sie die ursprünglichen Netzgewichtungen und -verzerrungen mithilfe von
initauf neue Werte und trainieren Sie erneut.Erhöhen Sie die Anzahl der verborgenen Neuronen oder die Anzahl der Verzögerungen.
Verwenden Sie einen größeren Trainingsdatensatz.
Erhöhen Sie die Anzahl der Eingangswerte, wenn relevantere Daten verfügbar sind.
Probieren Sie einen anderen Trainingsalgorithmus aus (siehe ).
Wenn Sie mehr Erfahrung mit Befehlszeilenoperationen sammeln möchten, können Sie die folgenden Aufgaben ausprobieren:
Öffnen Sie während des Trainings ein Diagrammfenster (z. B. das Fehlerkorrelationsdiagramm) und beobachten Sie seine Entwicklung.
Erstellen Sie ein Diagramm über die Befehlszeile mit Funktionen wie
plotresponse,ploterrcorrundplotperform.
Beim Trainieren eines neuronalen Netzes kann sich jedes Mal eine andere Lösung ergeben, da die anfänglichen Gewichtungs- und Verzerrungswerte zufällig sind und die Daten unterschiedlich in Trainings-, Validierungs- und Testmengen unterteilt werden. Daher können verschiedene neuronale Netze, die für das gleiche Problem trainiert wurden, mit ein und demselben Eingang zu unterschiedlichen Ergebnissen führen. Um sicherzustellen, dass ein neuronales Netz mit guter Genauigkeit gefunden wurde, müssen Sie das Netz mehrmals neu trainieren.
Es gibt verschiedene weitere Techniken zur Verbesserung der ursprünglichen Lösungen, wenn eine höhere Genauigkeit erwünscht ist. Weitere Informationen finden Sie unter .
Siehe auch
Neural Net Fitting | Neural Net Time Series | Neural Net Pattern Recognition | Neural Net Clustering | train | preparets | narxnet | closeloop | perform | removedelay