Estimate Neural State-Space Model
Description
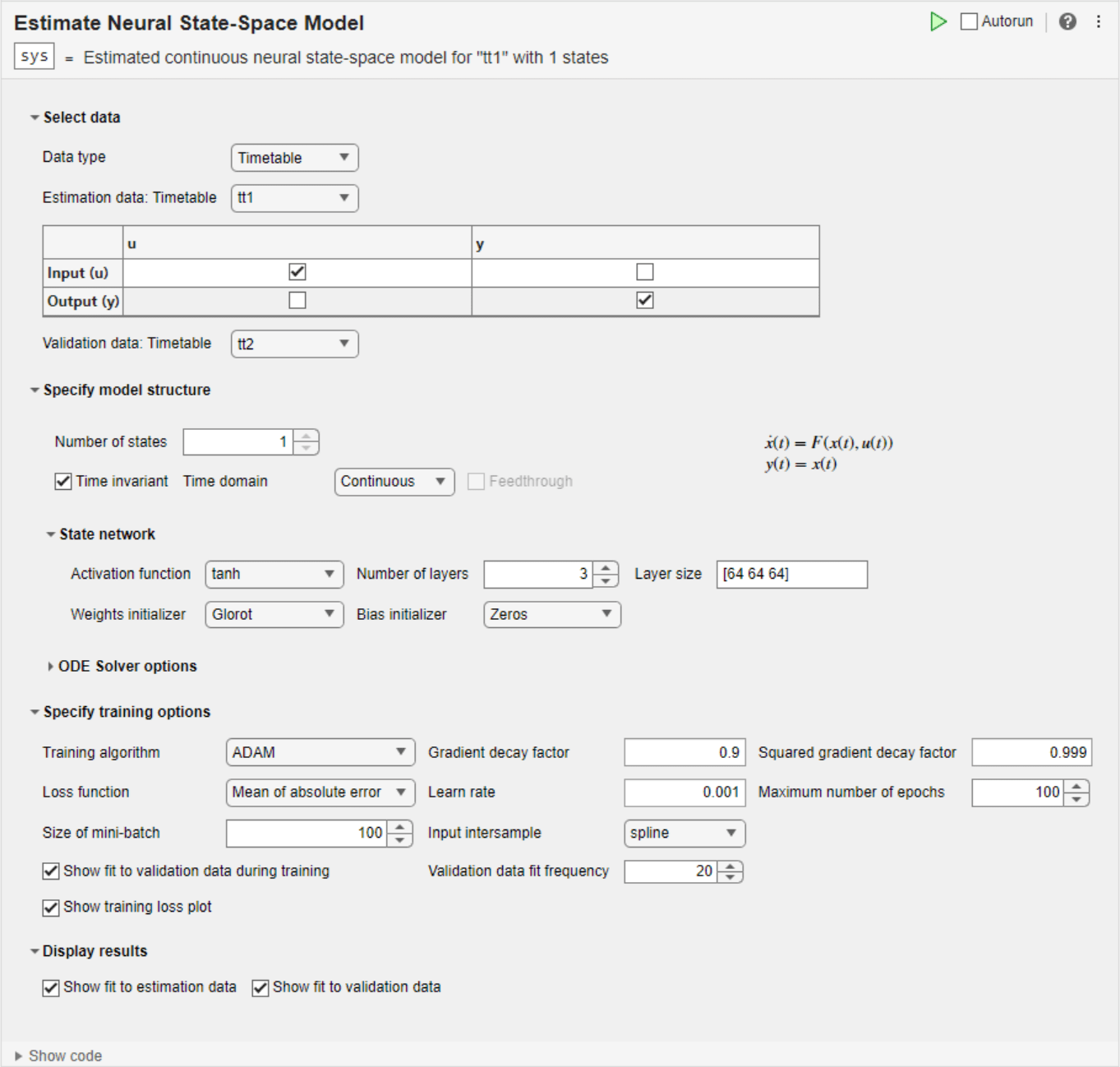
The Estimate Neural State-Space Model task lets you interactively estimate and validate a neural state-space model, using time-domain data. You can define and vary the structure and the parameters of the networks and the solver. The task automatically generates MATLAB® code for your live script. For more information about Live Editor tasks, see Add Interactive Tasks to a Live Script. For more information about state-space estimation, see What Are State-Space Models?
The Estimate Neural State-Space Model task is independent of the more general System Identification app. Use the System Identification app when you want to compute and compare estimates for multiple model structures.
To get started, load experiment data that contains input and output data into your MATLAB workspace and then import that data into the task. Then specify a model structure to estimate. The task gives you controls and plots that help you experiment with different model parameters and compare how well the output of each model fits the measurements.
Related Functions
The code that Estimate Neural State-Space Model generates uses the following functions and objects.
The task estimates an idNeuralStateSpace
state-space model.
Open the Task
To add the Estimate Neural State-Space Model task to a live script in the MATLAB Editor:
On the Live Editor tab, select Task > Estimate Neural State-Space Model.
In a code block in your script, type a relevant keyword, such as
neuralstatespaceornlssest. SelectEstimate State-Space Modelfrom the suggested command completions.
Examples
Use the Estimate Neural State-Space Model Live Editor Task to estimate a neural state-space model and compare the model output with the measurement data.
Open this example to see a pre-configured script containing the task.
Generate Data
For this example, generate data by simulating a first-order linear system. First, fix the random generator seed to guarantee reproducibility.
rng(0)
Create a first-order discrete dynamical system in tf form with one input and one output, convert it to discrete time using a sample time of 0.1 sec, and use ss to obtain a state-space realization.
Ts = 0.1; sys = ss(c2d(tf(1,[1 1]),Ts));
The identification of a neural state-space system requires you to have measurement of the system states. Therefore, transform the state-space coordinates so that the output is equal to the state. Alternatively you can augment the output equation to include the state among the measured signals.
sys.b = sys.b*sys.c; sys.c = 1;
In general, it is good practice to use multiple experiments, each containing a different trajectory, as doing so is more likely to yield a better coverage of the state-input space. Furthermore, using long trajectories tends to reduce both the accuracy and efficiency of the estimation. However, for this example, use a single trajectory for estimation.
Define a time vector and a random input sequence for estimation (training).
te = 0:Ts:10; ue = randn(length(te),size(sys.B,2));
Generate an output response to the random input sequence by simulating the system from a zero initial condition. The first (vertical) dimension in ye must be time and the second (horizontal) dimension must be the specific output in the output vector signal.
ye = lsim(sys,ue,te,zeros(size(sys.B,1),1));
Define a shorter time vector and a random input sequence for validation.
tv = 0:Ts:1; uv = randn(length(tv),size(sys.B,2));
Generate an output response to the random input sequence by simulating the system, from a zero initial condition.
yv = lsim(sys,uv,tv,zeros(size(sys.B,1),1));
Import Data into the Task
In the Select data section, set Data Type to Numeric, Sample Time to 0.1, Estimation Data: Input (u) to ue, Estimation Data: Output (y) to ye, Validation Data: Input (u) to uv, and Validation Data: Output (y) to yv.

Specify Model Structure and State Network
In the Specify model structure section, set the Number of states to 1 and select the discrete-time domain. In the State network section, set the Number of layers to 1 and specify Layer size as 16. Leave the other options unchanged.

Note that since for this example the output is equal to the state, there is no Output network section. Since the latent dimension is not specified, there are no Encoder network and Decoder network sections.
Examine Training and Display Options
In the Specify training options section, the Training algorithm is set to ADAM, with a Learn rate of 0.005. The maximum number of epochs is set to 150. For more information on these options, see nssTrainingOptions.
In the Display results section, both the Show fit to estimation data and (since you have specified validation data) the Show fit to validation data are selected.

Execute Live Task
Set the random generator seed again to guarantee reproducibility.
rng(0)
Execute the task from the Live Editor tab using Run. During training, a plot displays the training losses of the state and output networks.

Generating estimation report...done.


After training, two plots displays the model fit on the estimation and validation data.
Generate Code
To display the code that the task generates, click ![]() (Show code) at the bottom of the parameter section. The code that you see reflects the current parameter configuration of the task.
(Show code) at the bottom of the parameter section. The code that you see reflects the current parameter configuration of the task.



Related Examples
Parameters
Version History
Introduced in R2023bSee Also
Objects
idNeuralStateSpace|nssTrainingADAM|nssTrainingSGDM|nssTrainingRMSProp|nssTrainingLBFGS|idss|idnlgrey
Functions
createMLPNetwork|setNetwork|nssTrainingOptions|nlssest|generateMATLABFunction|idNeuralStateSpace/evaluate|idNeuralStateSpace/linearize|sim