Automated Machine Learning (AutoML) with MATLAB
Automated machine learning (AutoML) automates and eliminates manual steps required to go from a data set to a predictive model. AutoML also lowers the level of expertise required to build accurate models, so you can use it whether you are an expert or have limited machine learning experience.
You’ll learn how to perform AutoML in MATLAB® for feature selection and building a classification model. More specifically, see how to automatically select classification features from your data using univariate feature ranking with chi-square tests. Then, watch how to use ASHA optimization to automatically select and tune the best classification model for the given data set.
Published: 11 Aug 2020
AutoML in MATLAB delivers optimized models in just three steps. First, you convert raw sensor data to the features machine learning needs as input using wavelength scattering. Next, automated feature selection allows you to reduce large feature sets and thus ultimate model size. And finally, automated model selection picks the best model for you and optimizes its hyperparameters in the same step. You can apply these steps without machine learning expertise. However, this video uses some technical terms to explain what's happening behind the scenes.
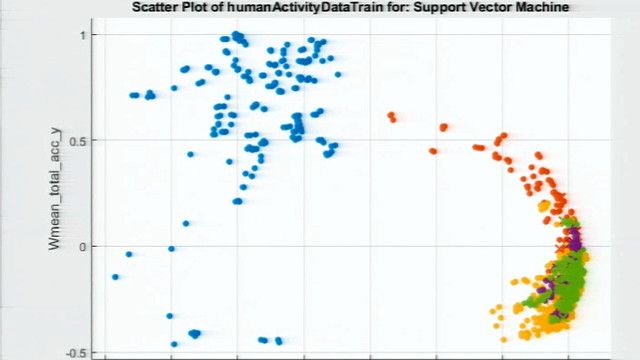
We demonstrate autoML building a model to classify activities, such as standing or sitting, using accelerometer meta data from a mobile phone. The remainder of the video walks you through the steps of autoML in MATLAB. First, to obtain relevant features from signal or image data, you can decompose signals with wavelengths using predefined wavelet and scaling filters that feature a Matrix function, applies wavelet scattering to buffers of signal.
Next, we could proceed to train a model on the over 400 feature we obtained, but that may result in a large model that does not fit on an embedded device. So a second step in auoML, we apply feature selection to reduce the number of features. The table here helps you choose the appropriate method based on the characteristics of your data.
Here we apply the minimum redundancy maximum relevance algorithm, which works really well on continuous and categorical features for classification. The feature ranking charts suggest that as few as a dozen features capture the majority of the variability in the signal.
After selecting a small performance set of features, we can proceed to the third step-- identifying the best performing model. Use fitcauto for classification and fit [? R ?] auto for regression. We train on just the dozen features we selected in the previous step. The algorithm evaluates many combinations of models and hyperparameters seeking to minimize the error. In practice, this may take hundreds of iterations to fully converge. Though for data of moderate size, we see good results in much less time, around 100 iterations. You can speed up execution using parallelization on multiple cores, on your local computer, or using cloud instances.
Applying autoML to this data set, we obtain a model with 96.6% accuracy on held-out test data. In summary, autoML obtained a highly accurate model in a few steps, effectively allowing engineers to build the models themselves without having to rely on data scientists. If you are knowledgeable in machine learning, autoML saves you time on routine steps, allowing you to focus on advanced optimization techniques such as stacking models and engineering even better features. For more information, visit our autoML discovery page or the links below.