Statistics and Machine Learning Toolbox
Analyse und Modellierung von Daten mithilfe von Statistik und Machine Learning
Haben Sie Fragen? Vertrieb kontaktieren.
Haben Sie Fragen? Vertrieb kontaktieren.
Statistics and Machine Learning Toolbox enthält Funktionen und Apps zur Beschreibung, Analyse und Modellierung von Daten. Für die explorative Datenanalyse stehen beschreibende Statistiken, Visualisierungen und Clustering zur Verfügung. Wahrscheinlichkeitsverteilungen können an Daten angepasst, Zufallszahlen für Monte-Carlo-Simulationen erzeugt und Hypothesentests durchgeführt werden. Regressions- und Klassifizierungsalgorithmen ermöglichen die Ableitung von Schlussfolgerungen aus den Daten und die Erstellung von Vorhersagemodellen. Sie können entweder interaktiv mithilfe der Apps Classification Learner und Regression Learner oder programmgesteuert mit AutoML entwickelt werden.
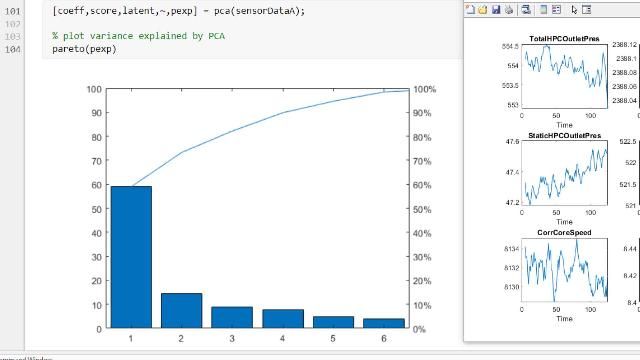
Die Toolbox umfasst die Primärkomponentenanalyse (PCA), Regularisierung, Dimensionalitätsreduktion und Methoden zur Merkmalsauswahl für mehrdimensionale Datenanalysen und Merkmalsextraktionen, mit denen Variablen mit der besten Prognosefähigkeit identifiziert werden können.
Außerdem stehen überwachte, halb überwachte und nicht überwachte Machine-Learning-Algorithmen zur Verfügung, wie z.B. Support Vector Machines (SVMs), verstärkte Entscheidungsbäume, flache neuronale Netze und weitere Clustering-Methoden. Interpretierbarkeitsmethoden wie ein partielles Abhängigkeitsdiagramm, Shapley-Werte und LIME können angewendet werden. C/C++ Code kann für den integrierten Einsatz automatisch generiert werden. Mithilfe nativer Simulink-Blöcke können Sie mit Simulationen und Model-Based Design prädiktive Modelle nutzen. Viele Toolbox-Algorithmen können auf Datensätze angewendet werden, die für den Arbeitsspeicher zu umfangreich sind.

Untersuchen Sie Daten mithilfe statistischer Diagramme mit interaktiven und visuellen Grafiken und beschreibender Statistik. Verstehen und beschreiben Sie potenziell große Datensätze in kurzer Zeit mithilfe beschreibender Statistik, einschließlich Messungen von zentraler Tendenz, Streuung, Form, Korrelation und Kovarianz.

Erkennen Sie Muster und Merkmale durch die Anwendung von k-Mittelwerten, hierarchischen, DBSCAN- und weiteren Clustering-Methoden und die Aufteilung von Daten in Clustergruppen. Bestimmen Sie die optimale Anzahl an Clustern für die Daten mithilfe verschiedener Bewertungskriterien. Ermitteln Sie Anomalien zur Erkennung von Ausreißern und Neuheiten.

Die Mustervarianz kann verschiedenen Quellen zugeordnet werden und Sie können bestimmen, ob die Variation innerhalb oder zwischen verschiedenen Populationsgruppen entsteht. Einsatz von Einweg-, Zweiweg-, Mehrweg-, multivariater und nichtparametrischer Varianzanalyse (ANOVA) sowie Analyse der Kovarianz (ANOCOVA) und wiederholte Analyse der Varianzmessungen (RANOVA).

Nutzen Sie die Regression Learner-App oder trainieren und bewerten Sie Modelle wie lineare Regression, gaußsche Prozesse, Support Vector Machines, neuronale Netze und Ensembles programmgesteuert.

Nutzen Sie die Classification Learner-App oder trainieren und validieren Sie Modelle wie logistische Regression, Support Vector Machines, verstärkte Bäume und flache neuronale Netze programmgesteuert.

Extrahieren Sie Merkmale aus Bildern, Signalen, Text und numerischen Daten. Untersuchen und entwickeln Sie neue Merkmale iterativ und wählen Sie jene Merkmale aus, mit denen die Leistung optimiert wird. Reduzieren Sie die Dimensionalität, indem Sie vorhandene Merkmale in neue Prädiktorvariablen umwandeln und dabei weniger aussagekräftige Merkmale nach der Umwandlung weglassen oder indem Sie eine automatische Merkmalsauswahl vornehmen.

Passen Sie kontinuierliche und diskrete Verteilungen an, verwenden Sie statistische Diagramme zur Evaluierung der Anpassungsgüte und berechnen Sie Wahrscheinlichkeitsdichtefunktionen und kumulative Verteilungsfunktionen für mehr als 40 verschiedene Verteilungen.

Ziehen Sie Schlussfolgerungen über eine Grundgesamtheit auf der Grundlage statistischer Belege aus einer Stichprobe. Führen Sie t-Tests, Verteilungstests und nichtparametrische Tests für einzelne, gepaarte oder selbstständige Stichproben durch. Testen Sie Autokorrektur und Zufälligkeit und vergleichen Sie die Verteilungen.

Auswirkungen und Datentrends können statistisch analysiert werden. Entwerfen Sie Experimente zum Erstellen und Testen praktischer Pläne zur Manipulation der Dateneingaben, mit denen Informationen über ihre Auswirkungen auf Datenausgaben generiert werden können. Visualisieren und analysieren Sie Daten über die Zeit bis zum Ausfall mit und ohne Zensur. Überwachen und bewerten Sie die Qualität industrieller Prozesse.

Verwenden Sie Tall Arrays und Tabellen mit zahlreichen Klassifikations-, Regressions- und Cluster-Algorithmen, um Modelle auf Datensätzen zu trainieren, die ohne Code-Anpassungen nicht in den Arbeitsspeicher passen.

Generieren Sie portablen und lesbaren C/C++ Code zur Inferenz von Klassifizierungs- und Regressionsmodellen, beschreibenden Statistiken und Wahrscheinlichkeitsverteilungen. Generieren Sie C/C++ Prognosecode mit reduzierter Genauigkeit und aktualisieren Sie die Parameter bereitgestellter Modelle ohne erneute Generierung des Prognosecodes.
30 Tage kostenlos ausprobieren.
Angebot anfordern und Erweiterungsprodukte entdecken.
Ihre Hochschule bietet möglicherweise bereits Zugang zu MATLAB, Simulink und Add-on-Produkten über eine Campus-Wide License.

Tutorials und Beispiele

Online-Kurs zum Selbststudium
Sie können auch eine Website aus der folgenden Liste auswählen:
Amerika
Europa
Asien-Pazifik