Getting Started with YOLOX for Object Detection
Detect objects in images using a You Only Look Once X (YOLOX) object detector using the Computer Vision Toolbox™ Automated Visual Inspection Library support package.
To get started with using a pretrained YOLOX network to detect objects in an image, see the Detect Objects in Image Using Pretrained YOLOX Network section.
To get started with training an untrained or pretrained YOLOX network for transfer learning, see the Train YOLOX Network and Perform Transfer Learning section.
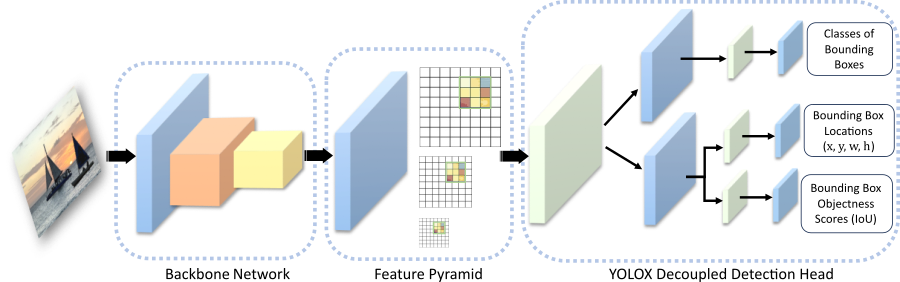
The YOLOX object detection model is a one-stage, anchor-free technique, which significantly reduces the model size and improves computation speed compared to previous YOLO models [1]. Instead of using memory-intensive predefined anchor boxes, YOLOX localizes objects directly by finding object centers. To predict bounding box dimensions, the network splits the input image into a grid of three different scales, and uses the grid points as the top-left offsets of the bounding boxes. Because grids can be recomputed based on image size, you may use YOLOX to perform tile-based training: train the YOLOX network on patches and perform inference on full-size images.
The YOLOX network consists of three parts: the backbone, the neck, and the head:
The backbone of the YOLOX network is a pretrained convolutional neural network CSP-DarkNet-53, trained on the COCO data set. The backbone acts as the feature extraction network that computes feature maps from the input images.
The neck connects the backbone and the head. It is composed of a feature pyramid network (FPN), which generates feature maps and corresponding grids at multiple scales, and a path aggregation network which combines the low-level and high-level features. The neck concatenates the feature maps from the backbone layers and feeds them as inputs to the head at three different scales (1024, 512, and 256 channels).
The decoupled detection head processes the aggregated features into three feature channels, which contain:
Classification scores – Classes of each bounding box
Regression scores – Locations and dimensions of each bounding box
Objectness scores (IoU) – Confidence scores that each bounding box contains an object
The figure shows the basic YOLOX architecture with a decoupled head at only one of the three scales for simplicity.
Install Automated Visual Inspection Support Package
This functionality requires Deep Learning Toolbox™ and the Automated Visual Inspection Library for Computer Vision Toolbox. You can install the Automated Visual Inspection Library for Computer Vision Toolbox from Add-On Explorer. For more information about installing add-ons, see Get and Manage Add-Ons. Processing image data on a GPU requires a supported GPU device and Parallel Computing Toolbox™.
Detect Objects in Image Using Pretrained YOLOX Network
To detect objects in a test image using a pretrained YOLOX network with default settings, follow these steps.
Load a test image from the workspace. The YOLOX model supports RGB or grayscale images.
I = imread("boats.png");Create a
yoloxObjectDetectorobject to configure a pretrained YOLOX network with a CSP-DarkNet-53 backbone as the feature extractor.detector = yoloxObjectDetector("small-coco");To increase inference speed at the possible cost of detecting less objects, alternatively specify the lightweight CSP-DarkNet-53 backbone with a reduced number of features (
"tiny-coco").Perform object detection using the
detectfunction on the pretrained network, specifying that the function return bounding boxes, detection scores, and labels.[bboxes,scores,labels] = detect(detector,I);
Display the results overlaid on the input image using the
insertObjectAnnotationfunction.detectedImg = insertObjectAnnotation(I,"Rectangle",bboxes,labels); figure imshow(detectedImg)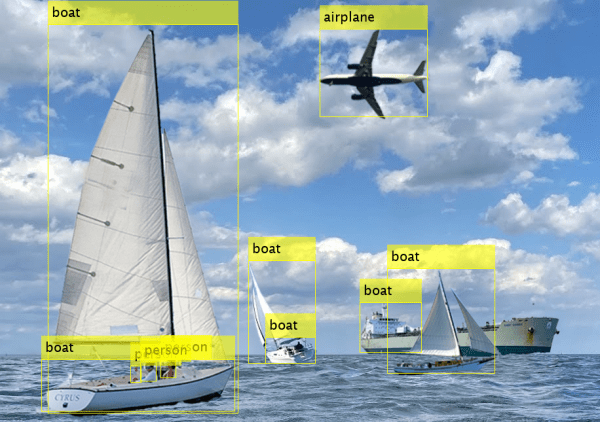
To perform inference on a test image using a trained YOLOX network, use the same
process but specify the trained YOLOX network in the detector
variable.
Train YOLOX Network and Perform Transfer Learning
To train a YOLOX object detection network on a labeled data set, use the trainYOLOXObjectDetector function. You must specify the class names for
the data set you use to train the network. Then, train an untrained or pretrained
network by using the trainYOLOXObjectDetector function. The training function returns the
trained network as a yoloxObjectDetector object.
To learn how to configure and train a YOLOX object detector for transfer learning to detect small objects, see the Detect Defects on Printed Circuit Boards Using YOLOX Network example.
Label Training Data for Deep Learning
To generate ground truth data, you can use the Image
Labeler, Video
Labeler, or Ground Truth Labeler (Automated Driving Toolbox) app to
interactively label pixels and export label data. You can also use the apps to label
rectangular regions of interest (ROIs) for object detection, scene labels for image
classification, and pixels for semantic segmentation. To create training data from a
ground truth object exported by any of the labelers, use the objectDetectorTrainingData or
pixelLabelTrainingData functions. For more details, see Training Data for Object Detection and Semantic Segmentation.
References
[1] Ge, Zheng, Songtao Liu, Feng Wang, Zeming Li, and Jian Sun. “YOLOX: Exceeding YOLO Series in 2021.” arXiv, August 5, 2021. http://arxiv.org/abs/2107.08430.
See Also
Apps
- Image Labeler | Ground Truth Labeler (Automated Driving Toolbox) | Video Labeler | Deep Network Designer (Deep Learning Toolbox)
Objects
Functions
Topics
- Detect Defects on Printed Circuit Boards Using YOLOX Network
- Get Started with Object Detection Using Deep Learning
- Get Started with Image Preprocessing and Augmentation for Deep Learning
- Choose an Object Detector
- Deep Learning in MATLAB (Deep Learning Toolbox)
- Pretrained Deep Neural Networks (Deep Learning Toolbox)
- Data Sets for Deep Learning (Deep Learning Toolbox)