ClassificationECOC
Multiclass model for support vector machines (SVMs) and other classifiers
Description
ClassificationECOC is an error-correcting output codes (ECOC)
classifier for multiclass learning, where the classifier consists of multiple binary
learners such as support vector machines (SVMs). Trained ClassificationECOC
classifiers store training data, parameter values, prior probabilities, and coding matrices.
Use these classifiers to perform tasks such as predicting labels or posterior probabilities
for new data (see predict).
Creation
Create a ClassificationECOC object by using fitcecoc.
If you specify linear or kernel binary learners without specifying cross-validation
options, then fitcecoc returns a CompactClassificationECOC object instead.
Properties
Object Functions
compact | Reduce size of machine learning model |
compareHoldout | Compare accuracies of two classification models using new data |
crossval | Cross-validate machine learning model |
discardSupportVectors | Discard support vectors of linear SVM binary learners in ECOC model |
edge | Classification edge for multiclass error-correcting output codes (ECOC) model |
gather | Gather properties of Statistics and Machine Learning Toolbox object from GPU |
incrementalLearner | Convert multiclass error-correcting output codes (ECOC) model to incremental learner |
loss | Classification loss for multiclass error-correcting output codes (ECOC) model |
margin | Classification margins for multiclass error-correcting output codes (ECOC) model |
partialDependence | Compute partial dependence |
plotPartialDependence | Create partial dependence plot (PDP) and individual conditional expectation (ICE) plots |
predict | Classify observations using multiclass error-correcting output codes (ECOC) model |
resubEdge | Resubstitution classification edge for multiclass error-correcting output codes (ECOC) model |
lime | Local interpretable model-agnostic explanations (LIME) |
resubLoss | Resubstitution classification loss for multiclass error-correcting output codes (ECOC) model |
resubMargin | Resubstitution classification margins for multiclass error-correcting output codes (ECOC) model |
resubPredict | Classify observations in multiclass error-correcting output codes (ECOC) model |
shapley | Shapley values |
testckfold | Compare accuracies of two classification models by repeated cross-validation |
Examples
Train a multiclass error-correcting output codes (ECOC) model using support vector machine (SVM) binary learners.
Load Fisher's iris data set. Specify the predictor data X and the response data Y.
load fisheriris
X = meas;
Y = species;Train a multiclass ECOC model using the default options.
Mdl = fitcecoc(X,Y)
Mdl =
ClassificationECOC
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
BinaryLearners: {3×1 cell}
CodingName: 'onevsone'
Properties, Methods
Mdl is a ClassificationECOC model. By default, fitcecoc uses SVM binary learners and a one-versus-one coding design. You can access Mdl properties using dot notation.
Display the class names and the coding design matrix.
Mdl.ClassNames
ans = 3×1 cell
{'setosa' }
{'versicolor'}
{'virginica' }
CodingMat = Mdl.CodingMatrix
CodingMat = 3×3
1 1 0
-1 0 1
0 -1 -1
A one-versus-one coding design for three classes yields three binary learners. The columns of CodingMat correspond to the learners, and the rows correspond to the classes. The class order is the same as the order in Mdl.ClassNames. For example, CodingMat(:,1) is [1; –1; 0] and indicates that the software trains the first SVM binary learner using all observations classified as 'setosa' and 'versicolor'. Because 'setosa' corresponds to 1, it is the positive class; 'versicolor' corresponds to –1, so it is the negative class.
You can access each binary learner using cell indexing and dot notation.
Mdl.BinaryLearners{1} % The first binary learnerans =
CompactClassificationSVM
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: [-1 1]
ScoreTransform: 'none'
Beta: [4×1 double]
Bias: 1.4492
KernelParameters: [1×1 struct]
Properties, Methods
Compute the resubstitution classification error.
error = resubLoss(Mdl)
error = 0.0067
The classification error on the training data is small, but the classifier might be an overfitted model. You can cross-validate the classifier using crossval and compute the cross-validation classification error instead.
Train an ECOC classifier using SVM binary learners. Then, access properties of the binary learners, such as estimated parameters, by using dot notation.
Load Fisher's iris data set. Specify the petal dimensions as the predictors and the species names as the response.
load fisheriris
X = meas(:,3:4);
Y = species;Train an ECOC classifier using SVM binary learners and the default coding design (one-versus-one). Standardize the predictors and save the support vectors.
t = templateSVM('Standardize',true,'SaveSupportVectors',true); predictorNames = {'petalLength','petalWidth'}; responseName = 'irisSpecies'; classNames = {'setosa','versicolor','virginica'}; % Specify class order Mdl = fitcecoc(X,Y,'Learners',t,'ResponseName',responseName,... 'PredictorNames',predictorNames,'ClassNames',classNames)
Mdl =
ClassificationECOC
PredictorNames: {'petalLength' 'petalWidth'}
ResponseName: 'irisSpecies'
CategoricalPredictors: []
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
BinaryLearners: {3×1 cell}
CodingName: 'onevsone'
Properties, Methods
t is a template object that contains options for SVM classification. The function fitcecoc uses default values for the empty ([]) properties. Mdl is a ClassificationECOC classifier. You can access properties of Mdl using dot notation.
Display the class names and the coding design matrix.
Mdl.ClassNames
ans = 3×1 cell
{'setosa' }
{'versicolor'}
{'virginica' }
Mdl.CodingMatrix
ans = 3×3
1 1 0
-1 0 1
0 -1 -1
The columns correspond to SVM binary learners, and the rows correspond to the distinct classes. The row order is the same as the order in the ClassNames property of Mdl. For each column:
1indicates thatfitcecoctrains the SVM using observations in the corresponding class as members of the positive group.–1indicates thatfitcecoctrains the SVM using observations in the corresponding class as members of the negative group.0indicates that the SVM does not use observations in the corresponding class.
In the first SVM, for example, fitcecoc assigns all observations to 'setosa' or 'versicolor', but not 'virginica'.
Access properties of the SVMs using cell subscripting and dot notation. Store the standardized support vectors of each SVM. Unstandardize the support vectors.
L = size(Mdl.CodingMatrix,2); % Number of SVMs sv = cell(L,1); % Preallocate for support vector indices for j = 1:L SVM = Mdl.BinaryLearners{j}; sv{j} = SVM.SupportVectors; sv{j} = sv{j}.*SVM.Sigma + SVM.Mu; end
sv is a cell array of matrices containing the unstandardized support vectors for the SVMs.
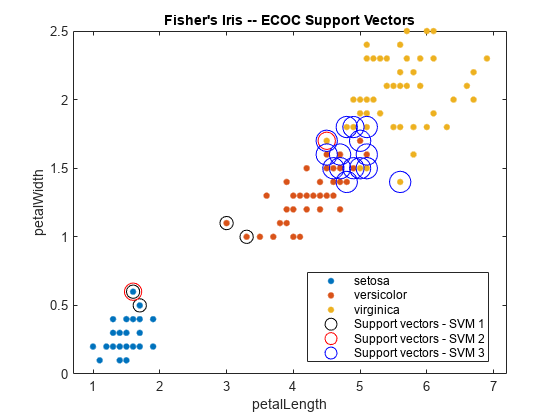
Plot the data, and identify the support vectors.
figure gscatter(X(:,1),X(:,2),Y); hold on markers = {'ko','ro','bo'}; % Should be of length L for j = 1:L svs = sv{j}; plot(svs(:,1),svs(:,2),markers{j},... 'MarkerSize',10 + (j - 1)*3); end title('Fisher''s Iris -- ECOC Support Vectors') xlabel(predictorNames{1}) ylabel(predictorNames{2}) legend([classNames,{'Support vectors - SVM 1',... 'Support vectors - SVM 2','Support vectors - SVM 3'}],... 'Location','Best') hold off
You can pass Mdl to these functions:
predict, to classify new observationsresubLoss, to estimate the classification error on the training datacrossval, to perform 10-fold cross-validation
Cross-validate an ECOC classifier with SVM binary learners, and estimate the generalized classification error.
Load Fisher's iris data set. Specify the predictor data X and the response data Y.
load fisheriris X = meas; Y = species; rng(1); % For reproducibility
Create an SVM template, and standardize the predictors.
t = templateSVM('Standardize',true)t =
Fit template for SVM.
Standardize: 1
t is an SVM template. Most of the template object properties are empty. When training the ECOC classifier, the software sets the applicable properties to their default values.
Train the ECOC classifier, and specify the class order.
Mdl = fitcecoc(X,Y,'Learners',t,... 'ClassNames',{'setosa','versicolor','virginica'});
Mdl is a ClassificationECOC classifier. You can access its properties using dot notation.
Cross-validate Mdl using 10-fold cross-validation.
CVMdl = crossval(Mdl);
CVMdl is a ClassificationPartitionedECOC cross-validated ECOC classifier.
Estimate the generalized classification error.
genError = kfoldLoss(CVMdl)
genError = 0.0400
The generalized classification error is 4%, which indicates that the ECOC classifier generalizes fairly well.
More About
The coding design is a matrix whose elements direct which classes are trained by each binary learner, that is, how the multiclass problem is reduced to a series of binary problems.
Each row of the coding design corresponds to a distinct class, and each column corresponds to a binary learner. In a ternary coding design, for a particular column (or binary learner):
A row containing 1 directs the binary learner to group all observations in the corresponding class into a positive class.
A row containing –1 directs the binary learner to group all observations in the corresponding class into a negative class.
A row containing 0 directs the binary learner to ignore all observations in the corresponding class.
Coding design matrices with large, minimal, pairwise row distances based on the Hamming measure are optimal. For details on the pairwise row distance, see Random Coding Design Matrices and [2].
This table describes popular coding designs.
| Coding Design | Description | Number of Learners | Minimal Pairwise Row Distance |
|---|---|---|---|
| one-versus-all (OVA) | For each binary learner, one class is positive and the rest are negative. This design exhausts all combinations of positive class assignments. | K | 2 |
| one-versus-one (OVO) | For each binary learner, one class is positive, one class is negative, and the rest are ignored. This design exhausts all combinations of class pair assignments. | K(K – 1)/2 | 1 |
| binary complete | This design partitions the classes into all binary
combinations, and does not ignore any classes. That is, all class
assignments are | 2K – 1 – 1 | 2K – 2 |
| ternary complete | This design partitions the classes into all ternary
combinations. That is, all class assignments are
| (3K – 2K + 1 + 1)/2 | 3K – 2 |
| ordinal | For the first binary learner, the first class is negative and the rest are positive. For the second binary learner, the first two classes are negative and the rest are positive, and so on. | K – 1 | 1 |
| dense random | For each binary learner, the software randomly assigns classes into positive or negative classes, with at least one of each type. For more details, see Random Coding Design Matrices. | Random, but approximately 10 log2K | Variable |
| sparse random | For each binary learner, the software randomly assigns classes as positive or negative with probability 0.25 for each, and ignores classes with probability 0.5. For more details, see Random Coding Design Matrices. | Random, but approximately 15 log2K | Variable |
This plot compares the number of binary learners for the coding designs with an increasing number of classes (K).

Algorithms
Alternative Functionality
You can use these alternative algorithms to train a multiclass model:
Classification ensembles—see
fitcensembleandClassificationEnsembleClassification trees—see
fitctreeandClassificationTreeDiscriminant analysis classifiers—see
fitcdiscrandClassificationDiscriminantk-nearest neighbor classifiers—see
fitcknnandClassificationKNNNaive Bayes classifiers—see
fitcnbandClassificationNaiveBayes