rlVectorQValueFunction
Vector Q-value function approximator with hybrid or discrete action space for reinforcement learning agents
Since R2022a
Description
This object implements a vector (also referred to as multi-output) Q-value
function approximator that you can use as a critic with a hybrid or discrete action space for
a reinforcement learning agent. A vector Q-value function (also known as vector action-value
function) is a mapping between a pair consisting of an observation and a continuous action to
a vector in which each element represents the expected discounted cumulative long-term reward
when an agent executes the discrete action corresponding to the specific
output number as well as the continuous action (if present) given as additional input,
starting from the state corresponding to the observation (also given in input), and follows a
given policy afterward. A vector Q-value function critic for discrete action spaces therefore
needs only the observation as input (as there is no continuous action). After you create an
rlVectorQValueFunction critic, use it to create an agent such as rlQAgent, rlDQNAgent, rlSARSAAgent or an
hybrid rlSACAgent. For more
information on creating actors and critics, see Create Actors, Critics, and Policy Objects.
Creation
Syntax
Description
critic = rlVectorQValueFunction(net,observationInfo,actionInfo)critic with a
discrete or hybrid action space. Here,
net is the deep neural network used as an approximation model.
Its input layers must take in all the observation channels as well as and the continuous
action channel (if present). The output layer must have as many elements as the number
of possible discrete actions. When you use this syntax, the network input layers are
automatically associated with the environment observation channels (and, if present, the
continuous action channel) according to the dimensions specified in
observationInfo (and if present, to the second action channel
specified in actionInfo). This function sets the
ObservationInfo and ActionInfo properties of
critic to the observationInfo and
actionInfo input arguments, respectively.
critic = rlVectorQValueFunction({basisFcn,W0},observationInfo,actionInfo)critic with a
discrete or hybrid action space using a
custom basis function as underlying approximation model. The first input argument is a
two-element cell array whose first element is the handle basisFcn
to a custom basis function and whose second element is the initial weight matrix
W0. Here the basis function must take in all the observation
channels as well as and the continuous action channel (if present), and
W0 must have as many columns as the number of possible discrete
actions. The function sets the ObservationInfo and ActionInfo properties of critic to the
input arguments observationInfo and
actionInfo, respectively.
critic = rlVectorQValueFunction(___,Name=Value)UseDevice property using one or more name-value arguments.
Specifying the input layer names (and, for hybrid action spaces, the continuous action
layer name) allows you explicitly associate the layers of your network approximator with
specific environment channels. For all types of approximators, you can specify the
device where computations for critic are executed, for example
UseDevice="gpu".
Input Arguments
Name-Value Arguments
Properties
Object Functions
rlDQNAgent | Deep Q-network (DQN) reinforcement learning agent |
rlQAgent | Q-learning reinforcement learning agent |
rlSARSAAgent | SARSA reinforcement learning agent |
getValue | Obtain estimated value from a critic given environment observations and actions |
getMaxQValue | Obtain maximum estimated value over all possible actions from a Q-value function critic with discrete action space, given environment observations |
evaluate | Evaluate function approximator object given observation (or observation-action) input data |
getLearnableParameters | Obtain learnable parameter values from agent, function approximator, or policy object |
setLearnableParameters | Set learnable parameter values of agent, function approximator, or policy object |
setModel | Set approximation model in function approximator object |
getModel | Get approximation model from function approximator object |
Examples
Create an observation specification object (or alternatively use the getObservationInfo function to extract the specification object from an environment). For this example, define the observation space as a continuous four-dimensional space, so that there is a single observation channel that carries a column vector containing four doubles.
obsInfo = rlNumericSpec([4 1]);
Create a discrete (finite set) action specification object (or alternatively use the getActionInfo function to extract the specification object from an environment with a discrete action space). For this example, define the action space as a finite set consisting of three possible actions (labeled 7, 5, and 3).
actInfo = rlFiniteSetSpec([7 5 3]);
A discrete vector Q-value function takes only the observation as input and returns as output a single vector with as many elements as the number of possible discrete actions. The value of each output element represents the expected discounted cumulative long-term reward for taking the action corresponding to the element number, from the state corresponding to the current observation, and following the policy afterwards.
To model the parameterized vector Q-value function within the critic, use a neural network with one input layer (receiving the content of the observation channel, as specified by obsInfo) and one output layer (returning the vector of values for all the possible actions, as specified by actInfo).
Define the network as an array of layer objects, and get the dimension of the observation space and the number of possible actions from the environment specification objects.
net = [
featureInputLayer(obsInfo.Dimension(1))
fullyConnectedLayer(16)
reluLayer
fullyConnectedLayer(16)
reluLayer
fullyConnectedLayer(numel(actInfo.Elements))
];Convert the network to a dlnetwork object, and display the number of weights.
net = dlnetwork(net); summary(net)
Initialized: true
Number of learnables: 403
Inputs:
1 'input' 4 features
Create the critic using the network, as well as the observation and action specification objects.
critic = rlVectorQValueFunction(net,obsInfo,actInfo)
critic =
rlVectorQValueFunction with properties:
ObservationInfo: [1×1 rl.util.rlNumericSpec]
ActionInfo: [1×1 rl.util.rlFiniteSetSpec]
Normalization: "none"
UseDevice: "cpu"
Learnables: {6×1 cell}
State: {0×1 cell}
To check your critic, use the getValue function to return the values of the discrete actions depending on a random observation, using the current network weights. There is one value for each of the three possible actions.
v = getValue(critic,{rand(obsInfo.Dimension)})v = 3×1 single column vector
0.0761
-0.5906
0.2072
You can now use the critic to create an agent for the environment described by the given specification objects. Examples of agents that can use a discrete vector Q-value function critic, are rlQAgent, rlDQNAgent, rlSARSAAgent and discrete rlSACAgent.
For more information on creating approximator objects such as actors and critics, see Create Actors, Critics, and Policy Objects.
Create an observation specification object (or alternatively use the getObservationInfo function to extract the specification object from an environment). For this example, define the observation space as a continuous four-dimensional space, so that there is a single observation channel that carries a column vector containing four doubles.
obsInfo = rlNumericSpec([4 1]);
Create a hybrid action specification object (or alternatively use the getActionInfo function to extract the specification object from an environment with a hybrid action space). For this example, define the action space as having the discrete channel carrying a scalar that can take three values (labeled -1, 0, and 1), and the continuous channel carrying a vector in which each of the three elements can vary between -10 and 10. For a hybrid action space, the discrete channel must always be the first one, and the continuous channel must be the second one.
actInfo = [
rlFiniteSetSpec([-1 0 1])
rlNumericSpec([3 1], ...
UpperLimit= 10*ones(3,1), ...
LowerLimit=-10*ones(3,1) )
];A hybrid vector Q-value function takes the observations and the continuous action as inputs and returns as output a single vector with as many elements as the number of possible discrete actions. The value of each output element represents the expected discounted cumulative long-term reward when an agent executes the discrete action corresponding to the specific output number as well as the continuous action given in input, starting from the state corresponding to the observation (also given in input), and follows the given policy afterwards.
To model the parameterized vector Q-value function within the critic, use a neural network with two input layers (receiving the content of the observation and continuous action channels, as specified by obsInfo and the second element of actInfo), and one output layer (returning the vector of values for the possible discrete actions, as specified by the first element of actInfo).
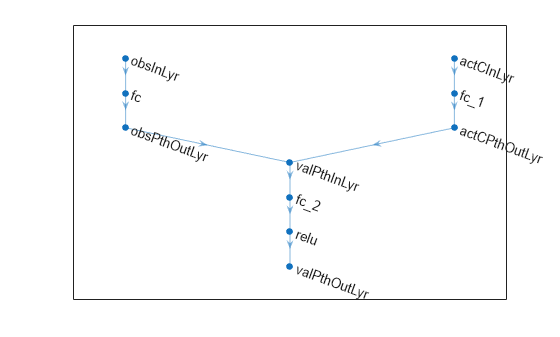
Define each network path as an array of layer objects, and get the dimension of the observation space and the number of possible actions from the environment specification objects.
Create the observation input path.
obsPath = [
featureInputLayer( ...
prod(obsInfo.Dimension), ...
Name="obsInLyr")
fullyConnectedLayer(prod(obsInfo.Dimension))
reluLayer(Name="obsPthOutLyr")
];
Create the continuous action input path.
actCPath = [
featureInputLayer(prod(actInfo(2).Dimension), ...
Name="actCInLyr")
fullyConnectedLayer( ...
prod(actInfo(2).Dimension))
reluLayer(Name="actCPthOutLyr")
];Create common output path. Concatenate inputs along the first available dimension.
valuesPath = [
concatenationLayer(1,2,Name="valPthInLyr")
fullyConnectedLayer(numel(actInfo(1).Elements))
reluLayer
fullyConnectedLayer( ...
numel(actInfo(1).Elements), ...
Name="valPthOutLyr")
];Assemble dlnetwork object.
net = dlnetwork; net = addLayers(net,obsPath); net = addLayers(net,actCPath); net = addLayers(net,valuesPath);
Connect layers.
net = connectLayers(net,"obsPthOutLyr","valPthInLyr/in1"); net = connectLayers(net,"actCPthOutLyr","valPthInLyr/in2");
Plot network.
plot(net)
Initialize network.
net = initialize(net);
Display the number of learnable parameters.
summary(net)
Initialized: true
Number of learnables: 68
Inputs:
1 'obsInLyr' 4 features
2 'actCInLyr' 3 features
Create the critic using the network, as well as the observation and action specification objects. When you use this syntax, the network input layers are automatically associated with the environment observation channels according to the dimensions specified in obsInfo.
critic = rlVectorQValueFunction(net,obsInfo,actInfo)
critic =
rlVectorQValueFunction with properties:
ObservationInfo: [1×1 rl.util.rlNumericSpec]
ActionInfo: [2×1 rl.util.RLDataSpec]
Normalization: ["none" "none"]
UseDevice: "cpu"
Learnables: {8×1 cell}
State: {0×1 cell}
To check your critic, use the getValue function to return the values of a batch of 10 discrete actions depending on a batch of 10 random observations continuous actions, using the current network weights.
robs = rand([obsInfo.Dimension 10]);
ract2 = rand([actInfo(2).Dimension 10]);
v = getValue(critic,{robs,ract2});Display the seventh element in the batch. There is one value for each of the three possible actions.
v(:,7)
ans = 3×1 single column vector
0.2402
-0.3046
-0.0533
You can now use the critic to create a hybrid rlSACAgent.
For more information on creating approximator objects such as actors and critics, see Create Actors, Critics, and Policy Objects.
Create an observation specification object (or alternatively use the getObservationInfo function to extract the specification object from an environment). For this example, define the observation space as a hybrid (that is, mixed discrete-continuous) space with the discrete channel carrying a scalar that can be either 0 or 1, and the second one being a vector over a continuous two-dimensional space.
obsInfo = [
rlFiniteSetSpec([0 1])
rlNumericSpec([2 1])
];Create a specification object for a hybrid action space (or alternatively use the getActionInfo function to extract the specification object from an environment with a hybrid action space). For this example, define the action space as a hybrid space with the discrete channel carrying a scalar that can only be -1, 0, or 1, and with the continuous channel carrying a two-element vector. Note that when defining hybrid action spaces, you must define the discrete action channel as the first one and the continuous action channel as the second one.
actInfo = [
rlFiniteSetSpec([-1 0 1])
rlNumericSpec([2 1])
];A hybrid vector Q-value function takes the observations and the continuous action as inputs and returns as output a single vector with as many elements as the number of possible discrete actions. The value of each output element represents the expected discounted cumulative long-term reward for taking the discrete action corresponding to the element number and the continuous action given as input, from the state corresponding to the current observations, and following the policy afterwards.
To model the parameterized vector Q-value function within the critic, use a neural network with three input layers and one output layer.
The input layers receive the content of the two observation channels, as specified by
obsInfoas well as the content of the continuous action channel, as specified by the second element ofactInfo. Therefore each input layer must have the same dimensions as the corresponding observation channel and an extra input layer must have the same dimensions of the continuous action channel, as specified by the second element ofactInfo.Each element of the output layer returns the value of the corresponding action. Therefore the output layer must have as many elements as the number of possible discrete actions, as specified by the first element of
actInfo.
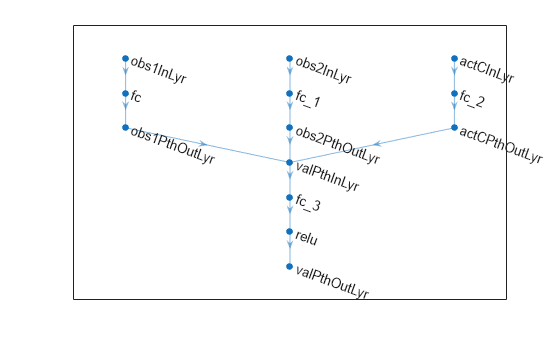
Define each network path as an array of layer objects, and get the dimension of the observation space and the number of possible actions from the environment specification objects. Name the network inputs obs1InLyr , obs2InLyr and actCInLyr (so you can later explicitly associate it with the observation input channel).
Create the first observation input path.
obs1Path = [
featureInputLayer( ...
prod(obsInfo(1).Dimension), ...
Name="obs1InLyr")
fullyConnectedLayer( ...
prod(obsInfo(1).Dimension))
reluLayer(Name="obs1PthOutLyr")
];Create the second observation input path.
obs2Path = [
featureInputLayer( ...
prod(obsInfo(2).Dimension), ...
Name="obs2InLyr")
fullyConnectedLayer( ...
prod(obsInfo(2).Dimension))
reluLayer(Name="obs2PthOutLyr")
];Create the continuous action input path.
actCPath = [
featureInputLayer( ...
prod(actInfo(2).Dimension), ...
Name="actCInLyr")
fullyConnectedLayer( ...
prod(actInfo(2).Dimension))
reluLayer(Name="actCPthOutLyr")
];Create common output path. Concatenate inputs along the first available dimension.
valuePath = [
concatenationLayer(1,3,Name="valPthInLyr")
fullyConnectedLayer(numel(actInfo(1).Elements))
reluLayer
fullyConnectedLayer( ...
numel(actInfo(1).Elements), ...
Name="valPthOutLyr")
];Assemble dlnetwork object.
net = dlnetwork; net = addLayers(net,obs1Path); net = addLayers(net,obs2Path); net = addLayers(net,actCPath); net = addLayers(net,valuePath);
Connect layers.
net = connectLayers(net,"obs1PthOutLyr","valPthInLyr/in1"); net = connectLayers(net,"obs2PthOutLyr","valPthInLyr/in2"); net = connectLayers(net,"actCPthOutLyr","valPthInLyr/in3");
Plot network.
plot(net)
Initialize network.
net = initialize(net);
Display the number of learnable parameters.
summary(net)
Initialized: true
Number of learnables: 44
Inputs:
1 'obs1InLyr' 1 features
2 'obs2InLyr' 2 features
3 'actCInLyr' 2 features
Create the critic using the network, the observations specification object, and the names of the network input layers. In this case, attempting to create a critic without using layer names will result in an error, because the dimension of the action channel is the same as the one of the continuous action channel, so the software is unable to unequivocally associate network layers with environment channels.
The specified network input layer, obsInLyr, is associated with the environment observation, and therefore must have the same data type and dimension as the observation channel specified in obsInfo.
critic = rlVectorQValueFunction(net,obsInfo,actInfo, ... ObservationInputNames={"obs1InLyr","obs2InLyr"}, ... ContinuousActionInputName="actCInLyr")
critic =
rlVectorQValueFunction with properties:
ObservationInfo: [2×1 rl.util.RLDataSpec]
ActionInfo: [2×1 rl.util.RLDataSpec]
Normalization: ["none" "none" "none"]
UseDevice: "cpu"
Learnables: {10×1 cell}
State: {0×1 cell}
To check your critic, use the getValue function to return the values of a batch of 10 discrete actions depending on batches of 5 random observations and continuous actions, using the current network weights.
robs1 = rand([obsInfo(1).Dimension 5]);
robs2 = rand([obsInfo(2).Dimension 5]);
rcact = rand([actInfo(2).Dimension 5]);
val = getValue(critic,{robs1,robs2,rcact})val = 3×5 single matrix
0.4805 0.4270 1.3389 0.8226 0.7614
-0.5405 -0.6970 -0.4360 -0.8698 -0.2068
-0.3309 -0.5041 0.2646 -0.2334 0.1775
Display the second element of the output batch.
val(:,2)
ans = 3×1 single column vector
0.4270
-0.6970
-0.5041
There is one value for each of the three possible discrete actions.
You can now use the critic to create a hybrid rlSACAgent.
For more information on creating approximator objects such as actors and critics, see Create Actors, Critics, and Policy Objects.
Create an observation specification object (or alternatively use the getObservationInfo function to extract the specification object from an environment). For this example, define the observation space as consisting of two channels, the first carrying a two-by-two continuous matrix and the second carrying scalar that can assume only two values, 0 and 1.
obsInfo = [
rlNumericSpec([2 2])
rlFiniteSetSpec([0 1])
];Create a hybrid action specification object (or alternatively use the getActionInfo function to extract the specification object from an environment with a hybrid action space). For this example, define a hybrid action space in which the discrete part is a vector that can have three possible values: [1 2], [3 4], and [5 6], while the continuous part is a two-dimensional continuous vector in which each element can very between -5 and 5.
actInfo = [
rlFiniteSetSpec({[1 2],[3 4],[5 6]})
rlNumericSpec([2 1], ...
UpperLimit= 5*ones(2,1), ...
LowerLimit=-5*ones(2,1) )
]; A hybrid vector Q-value function takes observations and the continuous action as inputs and returns as output a single vector with as many elements as the number of possible discrete actions. The value of each element of the output vector represents the expected discounted cumulative long-term reward when an agent executes the discrete action corresponding to the specific output number as well as the continuous action given in input, starting from the state corresponding to the observation (also given in input), and follows the given policy afterward.
To model the parameterized vector Q-value function within the critic, use a custom basis function with three input arguments and one output argument.
The first two input arguments receive the content of the environment observation channels, as specified by
obsInfo(for this example, a matrix and a scalar, respectively).The third input argument receives the content of the continuous action channel, as specified by the second element of
actInfo, (for this example, a vector).The output argument is a vector with four elements (you can have as many elements as needed by your application).
Note that using local functions to implement a custom basis function is not recommended if you want to save an agent and load it later. This is because local functions are available only in the file in which they are defined, and when you load an agent in the workspace the function is no longer available to the agent. Additionally, local functions are not supported for code generation.
Write a simple custom basis function as a string (alternatively, write your own custom basis function in a file).
str = "function out = myBasisFcn(obsA,obsB,actC)" + newline + ... " out = [obsA(1,1,:)+obsB(1,1,:).^2-actC(1,1,:);" + newline + ... " obsA(2,1,:)-obsB(1,1,:).^2-actC(2,1,:);" + newline + ... " obsA(1,2,:).^2+obsB(1,1,:)+actC(1,1,:);" + newline + ... " obsA(2,2,:).^2-obsB(1,1,:)+actC(2,1,:) ];" + newline + ... "end"
str =
"function out = myBasisFcn(obsA,obsB,actC)
out = [obsA(1,1,:)+obsB(1,1,:).^2-actC(1,1,:);
obsA(2,1,:)-obsB(1,1,:).^2-actC(2,1,:);
obsA(1,2,:).^2+obsB(1,1,:)+actC(1,1,:);
obsA(2,2,:).^2-obsB(1,1,:)+actC(2,1,:) ];
end"
Here, the first two dimensions of the observations and action channels are the ones defined in the obsInfo elements, while the third dimension is the batch dimension. Since the training algorithm normally executes on batches of observations and actions at the same time, you have to keep the batch dimension into account when writing your custom basis function. For each element of the batch dimension, the function returns a vector of four elements. Each output element can be any combination of the three inputs, depending on your application.
Write the string to the myBasisFcn.m file and check that the file exists.
fid=fopen("myBasisFcn.m","w"); fwrite(fid,str,"char"); fclose(fid); exist("myBasisFcn.m","file")
ans = 2
For each element of the batch, the output of the critic is the vector c = W'*myBasisFcn(obsA,obsB,actC), where W is a weight matrix which must have as many rows as the length of the basis function output and as many columns as the number of possible discrete actions, as specified by the first element of actInfo.
Each element of c represents the expected cumulative long term reward when an agent executes the discrete action corresponding to number of the element in c, as well as the continuous action given in input, starting from the state corresponding to the observations (also given in input), and follows the given policy afterward.
The elements of W are the learnable parameters.
Define an initial parameter matrix.
W0 = rand(4,3);
Create the critic. The first argument is a two-element cell containing both the handle to the custom function and the initial parameter matrix. The second and third arguments are, respectively, the observation and action specification objects.
critic = rlVectorQValueFunction({@myBasisFcn,W0},obsInfo,actInfo)critic =
rlVectorQValueFunction with properties:
ObservationInfo: [2×1 rl.util.RLDataSpec]
ActionInfo: [2×1 rl.util.RLDataSpec]
Normalization: ["none" "none" "none"]
UseDevice: "cpu"
Learnables: {[3×4 dlarray]}
State: {}
To check your critic, use the getValue function to return the values of a random observation, using the current parameter matrix. The function returns one value for each of the three possible actions.
v = getValue(critic,{rand(2,2),0,rand(2,1)})v = 3×1
1.3972
1.0399
1.5082
Note that the critic does not enforce the set constraint for the discrete set elements.
v = getValue(critic,{rand(2,2),-1,rand(2,1)})v = 3×1
2.2854
1.8893
2.5565
Obtain values for a random batch of 10 observations.
v = getValue(critic,{ ...
rand([obsInfo(1).Dimension 10]), ...
rand([obsInfo(2).Dimension 10]) ...
rand([actInfo(2).Dimension 10]) ...
});Display the values corresponding to the seventh element of the observation batch.
v(:,7)
ans = 3×1
0.8710
0.7387
0.9314
You can now use the critic to create an agent for the environment described by the given specification objects.
You can now use the critic to create a hybrid rlSACAgent.
For more information on creating approximator objects such as actors and critics, see Create Actors, Critics, and Policy Objects.
Create an environment and obtain observation and action specification objects.
env = rlPredefinedEnv("CartPole-Discrete");
obsInfo = getObservationInfo(env);
actInfo = getActionInfo(env);A discrete vector Q-value function takes only the observation as input and returns as output a single vector with as many elements as the number of possible actions. The value of each output element represents the expected discounted cumulative long-term reward for taking the action from the state corresponding to the current observation, and following the policy afterwards.
To model the parameterized vector Q-value function within the critic, use a recurrent neural network with one input layer (receiving the content of the observation channel, as specified by obsInfo) and one output layer (returning the vector of values for all the possible actions, as specified by actInfo).
Define the network as an array of layer objects, and get the dimension of the observation space and the number of possible actions from the environment specification objects. To create a recurrent network, use a sequenceInputLayer as the input layer (with size equal to the number of dimensions of the observation channel) and include at least one lstmLayer.
net = [
sequenceInputLayer(obsInfo.Dimension(1))
fullyConnectedLayer(50)
reluLayer
lstmLayer(20)
fullyConnectedLayer(20)
reluLayer
fullyConnectedLayer(numel(actInfo.Elements))
];Convert the network to a dlnetwork object, and display the number of weights.
net = dlnetwork(net); summary(net)
Initialized: true
Number of learnables: 6.4k
Inputs:
1 'sequenceinput' Sequence input with 4 channels
Create the critic using the network, as well as the observation and action specification objects.
critic = rlVectorQValueFunction(net, ...
obsInfo,actInfo);To check your critic, use the getValue function to return the value of a random observation and action, using the current network weights.
v = getValue(critic,{rand(obsInfo.Dimension)})v = 2×1 single column vector
0.0136
0.0067
You can use dot notation to extract and set the current state of the recurrent neural network in the critic.
critic.State
ans=2×1 cell array
{20×1 dlarray}
{20×1 dlarray}
critic.State = {
-0.1*dlarray(rand(20,1))
0.1*dlarray(rand(20,1))
};To evaluate the critic using sequential observations, use the sequence length (time) dimension. For example, obtain actions for 5 independent sequences each one consisting of 9 sequential observations. Note that the sequence dimension is not supported for stateless approximators.
[value,state] = getValue(critic, ...
{rand([obsInfo.Dimension 5 9])});Display the value corresponding to the seventh element of the observation sequence in the fourth sequence.
value(1,4,7)
ans = single
0.0382
Display the updated state of the recurrent neural network.
state
state=2×1 cell array
{20×5 single}
{20×5 single}
You can now use the critic to create an agent for the environment described by the given specification objects. Examples of agents that can use a vector Q-value function critic, are rlQAgent, rlDQNAgent, rlSARSAAgent, and discrete action space rlSACAgent.
For more information on creating approximator objects such as actors and critics, see Create Actors, Critics, and Policy Objects.
Version History
Introduced in R2022a