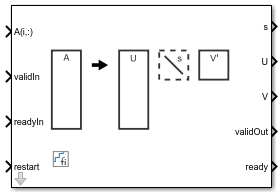
Non-Square Jacobi SVD HDL Optimized
Libraries:
Fixed-Point Designer HDL Support /
Matrices and Linear Algebra /
Matrix Factorizations
Description
Use the Non-Square Jacobi SVD HDL Optimized block to perform singular value
decomposition (SVD) on non-square matrices using QR decomposition and the two-sided Jacobi
algorithm. This block consists of a Real Partial-Systolic QR
Decomposition or Complex Partial-Systolic
QR Decomposition block, depending on your configuration, and a Square Jacobi SVD HDL
Optimized. Given a matrix A with more rows than columns, the
Non-Square Jacobi SVD HDL Optimized block uses QR decomposition to preprocess
the input, then uses the two-sided Jacobi method to produce a vector s of
nonnegative elements and unitary matrices U and V such
that A =
U*diag(s)*V'.
Note
For square matrices, use the Square Jacobi SVD HDL Optimized block.
Examples
This example shows how to use the Non-Square Jacobi SVD HDL Optimized block to compute the singular value decomposition (SVD) of non-square matrices.
Non-Square Two-Sided Jacobi SVD
The Non-Square Jacobi HDL Optimized block uses the QR decomposition and two-sided Jacobi algorithm to perform singular value decomposition. Given an input matrix A with more rows than columns, the block first uses QR decomposition to preprocess the input, then uses the two-sided Jacobi method to perform singular value decomposition. Because the Jacobi algorithm can perform such computations in parallel, it is suitable for FPGA and ASIC applications. For more information, see Non-Square Jacobi SVD HDL Optimized.
Define Simulation Parameters
Specify the dimension of the sample matrices, the number of input sample matrices, and the number of iterations of the Jacobi algorithm.
m = 16; n = 8; rankA = 7; numSamples = 3; nIterations = 10;
Generate Input A Matrices
Use the specified simulation parameters to generate the input matrix A.
rng('default');The Non-Square Jacobi SVD HDL Optimized block supports both real and complex inputs. Set the complexity of the input in the block mask accordingly.
complexity ="real"; A = zeros(m,n,numSamples); for k = 1:numSamples switch complexity case 'complex' A(:,:,k) = fixed.example.complexRandomLowRankMatrix(m,n,rankA); case 'real' A(:,:,k) = fixed.example.realRandomLowRankMatrix(m,n,rankA); otherwise error("Complexity must be either 'real' or 'complex'") end end
Select Fixed-Point Data Types
Define the desired word length.
wordLength = 25;
Use the upper bound on the singular values to define fixed-point types that will never overflow. First, use the fixed.singularValueUpperBound function to determine the upper bound on the singular values.
svdUpperBound = fixed.singularValueUpperBound(m,n,max(abs(A(:))));
Define the integer length based on the value of the upper bound, with one additional bit for the sign, another additional bit for intermediate CORDIC growth, and one more bit for intermediate growth to compute the Jacobi rotations.
additionalBitGrowth = 3; integerLength = ceil(log2(svdUpperBound)) + additionalBitGrowth;
Compute the fraction length based on the integer length and the desired word length.
fractionLength = wordLength - integerLength;
Define the signed fixed-point data type to be 'Fixed' or 'ScaledDouble'. You can also define the type to be 'double' or 'single'.
dataType = 'Fixed'; T.A = fi([],1,wordLength,fractionLength,'DataType',dataType); disp(T.A)
[]
DataTypeMode: Fixed-point: binary point scaling
Signedness: Signed
WordLength: 25
FractionLength: 18
Cast the matrix A to the signed fixed-point type.
A = cast(A,'like',T.A);Configure Model Workspace and Run Simulation
model = 'NonSquareJacobiSVDModel';
load_system(model);
open_system(model);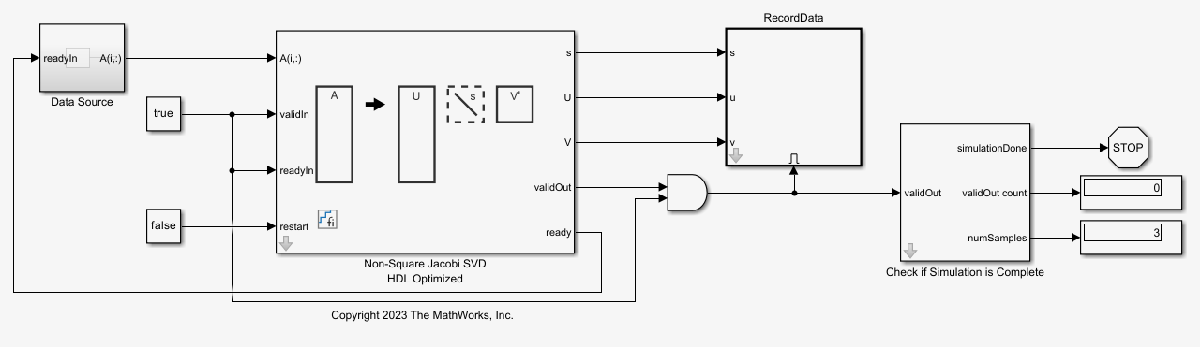
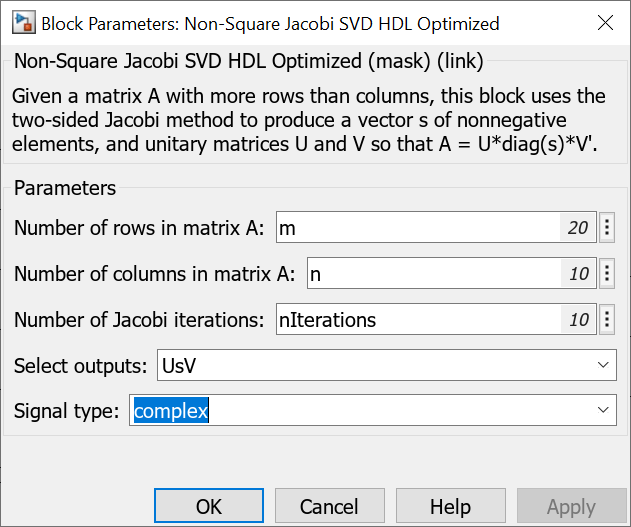
Set the parameter for real or complex either using set_param, or from the dialog.
set_param('NonSquareJacobiSVDModel/Non-Square Jacobi SVD HDL Optimized','complexity',complexity);
Set the variables in the model workspace.
fixed.example.setModelWorkspace(model,'A',A,'m',m,'n',n,... 'nIterations',nIterations,'numSamples',numSamples); out = sim(model);
Verify Output Solutions
Verify the output solutions. In these steps, "identical" means within roundoff error.
Verify that
U*diag(s)*V'is identical toA.relativeErrorUSVrepresents the relative error betweenU*diag(s)*V'andA.Verify that the singular values
sare identical to the floating-point SVD solution.relativeErrorSrepresents the relative error betweensand the singular values calculated by the MATLAB®svdfunction.Verify that
UandVare unitary matrices.relativeErrorUUrepresents the relative error betweenU'*Uand the identity matrix.relativeErrorVVrepresents the relative error betweenV'*Vand the identity matrix.
for i = 1:numSamples disp(['Sample #',num2str(i),':']); a = A(:,:,i); U = out.U(:,:,i); V = out.V(:,:,i); s = out.s(:,:,i); % Verify U*diag(s)*V' if norm(double(a)) > 1 relativeErrorUSV = norm(double(U*diag(s)*V')-double(a))/norm(double(a)); else relativeErrorUSV = norm(double(U*diag(s)*V')-double(a)); end relativeErrorUSV % Verify s s_expected = svd(double(a)); normS = norm(s_expected); relativeErrorS = norm(double(s) - s_expected); if normS > 1 relativeErrorS = relativeErrorS/normS; end relativeErrorS % Verify U'*U % U'*U will only be unitary up to the rank of A U = double(U); UU = U(:,1:rankA)'*U(:,1:rankA); relativeErrorUU = norm(UU - eye(size(UU))) % Verify V'*V V = double(V); VV = V'*V; relativeErrorVV = norm(VV - eye(size(VV))) disp('---------------'); end
Sample #1:
relativeErrorUSV = 2.3251e-04
relativeErrorS = 9.8161e-05
relativeErrorUU = 3.5827e-05
relativeErrorVV = 3.7335e-05
---------------
Sample #2:
relativeErrorUSV = 3.3725e-04
relativeErrorS = 6.5314e-05
relativeErrorUU = 2.4210e-05
relativeErrorVV = 3.5644e-05
---------------
Sample #3:
relativeErrorUSV = 4.5802e-04
relativeErrorS = 1.2924e-04
relativeErrorUU = 4.2547e-05
relativeErrorVV = 3.5511e-05
---------------
Extended Examples
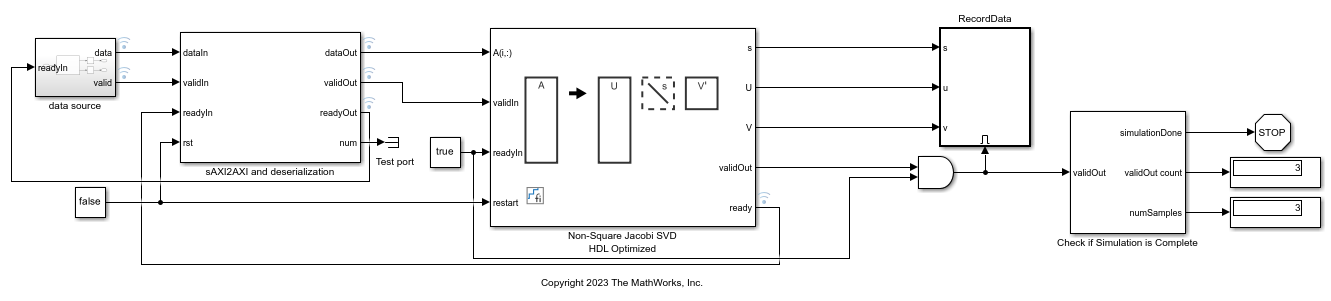
Implement HDL Optimized SVD for Non-Square Matrix with Scalar Input and Simplified AXI4 Protocol
Use the Non-Square Jacobi SVD HDL Optimized block to compute the singular value decomposition (SVD) of non-square matrices. The input data is in scalar format and uses simplified AXI4 protocol. The Non-Square Jacobi SVD HDL Optimized block uses the AMBA AXI handshake protocol for both input and output. The valid/ready handshake process is used to transfer data and control information. For more details about the handshake process, see Non-Square Jacobi SVD HDL Optimized. In certain use cases such as using this block with IP core generation workflow, this block needs to interface with upstream block using the Model Design for AXI4-Stream Interface Generation (HDL Coder). In this example, the sAXI2AXI block serves as an adapter between simplified AXI and AMBA AXI protocols. It also converts the scalar input into row format and feeds into the Non-Square Jacobi SVD HDL Optimized block.
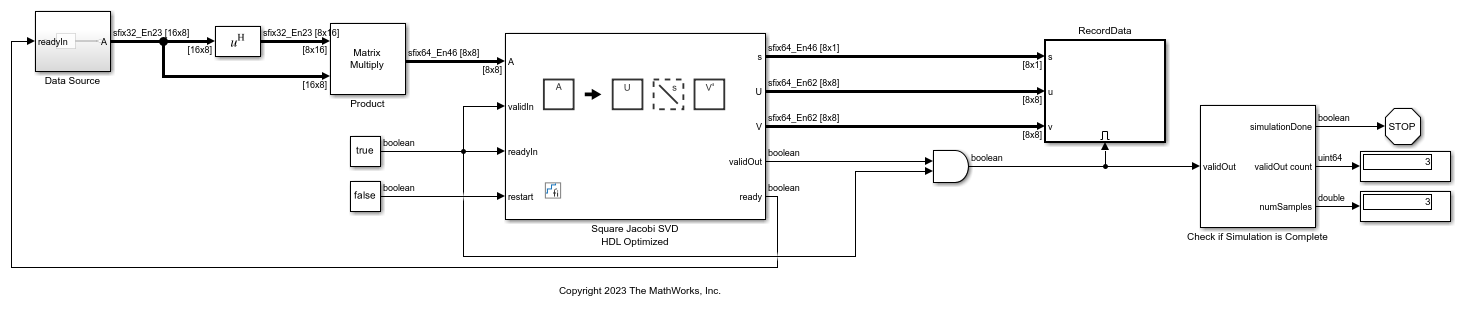
Compute SVD of Non-Square Matrices Using Square Jacobi SVD HDL Optimized Block by Forming Covariance Matrices
Use the Square Jacobi SVD HDL Optimized block to compute the singular value decomposition (SVD) of non-square matrices by forming covariance matrices.
Limitations
To optimize HDL efficiency, if the input matrix A is not full rank, then the output U matrix is orthonormal up to the rank of A. is still valid. V is always orthonormal regardless of the rank of A.
For example, if , then A has rank 2 and .
If the input matrix is full rank, then , where I = eye(n).
Ports
Input
Output
Parameters
Tips
The behavior of the Non-Square Jacobi SVD HDL Optimized block is equivalent to
[U,s,V] = fixed.jacobiSVD(A)whenAis a non-square matrix. If the input data type is fixed point with binary-point scaling, the function and the block provide bit-exact results. However, if the input data type is floating point, small numerical differences may exist between the function and the block.The Number of Jacobi iterations block parameter is equivalent to the
numberOfSweepsinput argument for thefixed.jacobiSVDfunction.
Algorithms
The Non-Square Jacobi SVD HDL Optimized block accepts the matrix A row by row. After accepting m rows, the block outputs U, s, and V.
For example, assume that validIn asserts before
ready, meaning that the upstream data source is faster than the
Non-Square Jacobi SVD HDL Optimized block. Additionally, assume that
readyIn is always asserted, meaning that the downstream consumer of the
data is faster than the Square Jacobi SVD HDL Optimized.
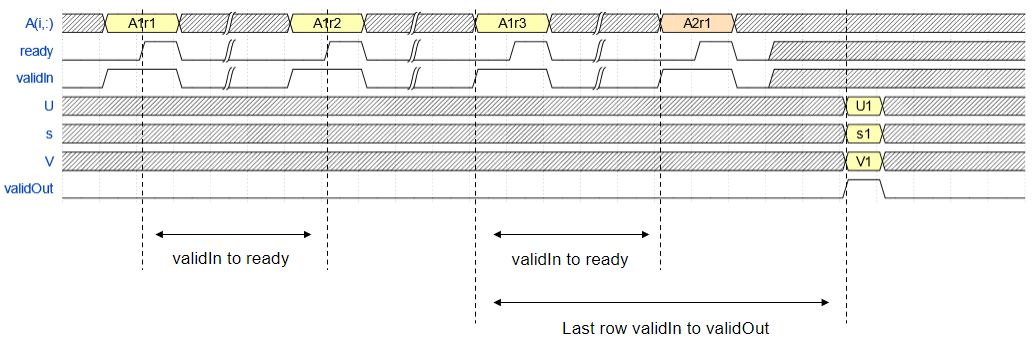
In the figure:
A1r1is the first row of the first A matrix,s1is the first s vector, and so on.validIntoready— From a successful row input to the block being ready to accept the next row.Last row
validIntovalidOut— From the last row input to the block starting to output the solution.
The latency of the Non-Square Jacobi SVD HDL Optimized block depends on
the size (m, n), complexity, and word length
(wl) of the input matrix A, the number of iterations
(nIterations) of the two-sided Jacobi algorithm, and whether the output
U is selected, as summarized in the tables.
If the data type of A is fixed point, then
wlis the word length.If the data type of A is double precision, then
wlis53.If the data type of A is single precision, then
wlis24.
Signal type ( | Select outputs ( | validIn to ready |
|---|---|---|
| UsV or Us |
max([wl+7,ceil(((wl*2+31)*(n-1+rem(n,2))... *nIterations+2+nextpow2(n)... *(nextpow2(n)+1)/2+3+2)/m),... ceil((m*n+1)/m)]) |
| sV or s |
max([wl+7,ceil(((wl*2+31)*(n-1+rem(n,2))... *nIterations+2+nextpow2(n)... *(nextpow2(n)+1)/2+3+2)/m)]) |
| UsV or Us |
max([wl+9,ceil(((wl*6+48)*(n-1+rem(n,2))... *nIterations+2+nextpow2(n)... *(nextpow2(n)+1)/2+3+2)/m),... ceil((m*n+1)/m)]) |
| sV or s |
max([wl+9,ceil(((wl*6+48)*(n-1+rem(n,2))... *nIterations+2+nextpow2(n)... *(nextpow2(n)+1)/2+3+2)/m]) |
Signal type ( | Select outputs ( | Last row validIn to validOut |
|---|---|---|
| UsV or Us |
((wl+6)*n)+6+2+(wl*2+31)*(n-1+rem(n,2))... *nIterations+2+nextpow2(n)... *(nextpow2(n)+1)/2+3+m*n+1 |
| sV or s |
((wl+6)*n)+6+2+(wl*2+31)... *(n-1+rem(n,2))*nIterations... +2+nextpow2(n)*(nextpow2(n)+1)/2+3 |
| UsV or Us |
((wl+7.5)*2*n)+6+2+(wl*6+48)*(n-1+rem(n,2))... *nIterations+2+nextpow2(n)... *(nextpow2(n)+1)/2+3+m*n+1 |
| sV or s |
((wl+7.5)*2*n)+6+2+(wl*6+48)*(n-1+rem(n,2))... *nIterations+2+nextpow2(n)... *(nextpow2(n)+1)/2+3 |
References
[1] Arm Developer. "AMBA AXI and ACE Protocol Specification Version E." https://developer.arm.com/documentation/ihi0022/e/.
[2] Jacobi, Carl G. J., "Über ein leichtes Verfahren die in der Theorie der Säcularstörungen vorkommenden Gleichungen numerisch aufzulösen." Journal fur die reine und angewandte Mathematik 30 (1846): 51–94.
[3] Forsythe, George E. and Peter Henrici. "The Cyclic Jacobi Method for Computing the Principal Values of a Complex Matrix." Transactions of the American Mathematical Society 94, no. 1 (January 1960): 1-23.
[4] Shiri, Aidin and Ghader Khosroshahi. "An FPGA Implementation of Singular Value Decomposition", ICEE 2019: 27th Iranian Conference on Electrical Engineering, Yazd, Iran, April 30–May 2, 2019, 416-22, IEEE.
[5] Golub, Gene H. and Charles F. Van Loan. Matrix Computations, 4th ed. Baltimore, MD: Johns Hopkins University Press, 2013.
[6] Athi, Mrudula V., Seyed R. Zekavat, and Alan A. Struthers. "Real-Time Signal Processing of Massive Sensor Arrays via a Parallel Fast Converging SVD Algorithm: Latency, Throughput, and Resource Analysis." IEEE Sensors Journal 16, no. 18 (January 2016): 2519-26. https://doi.org/10.1109/JSEN.2016.2517040.
[7] Brent, Richard P., Franklin T. Luk, and Charles Van Loan. "Computation of the Singular Value Decomposition Using Mesh-Connected Processors." Journal of VLSI and Computer Systems 1, 3 (1985): 242–70.
[8] Hemkumar, Nariankadu D. A Systolic VLSI Architecture for Complex SVD. Master’s thesis, Rice University, 1991.
[9] Duryea, R. A. Finite Precision Arithmetic in Singular Value Decomposition Architectures. Ph.D. thesis, Cornell University, 1987.
[10] Cavallaro, Joseph R. and Franklin T. Luk. 1987. "CORDIC Arithmetic for an SVD Processor." 1987 IEEE 8th Symposium on Computer Arithmetic (ARITH), Como, Italy, May 18-21, 1987, 113-20. IEEE. https://doi.org/10.1109/ARITH.1987.6158686.
Extended Capabilities
Version History
Introduced in R2023b