detectSpeech
Detect boundaries of speech in audio signal
Syntax
Description
idx = detectSpeech(audioIn,fs,Name,Value)Name,Value pair arguments.
Example: detectSpeech(audioIn,fs,'Window',hann(512,'periodic'),'OverlapLength',256)
detects speech using a 512-point periodic Hann window with 256-point overlap.
[
also returns the thresholds used to compute the boundaries of speech.idx,thresholds] = detectSpeech(___)
detectSpeech(___) with no output arguments displays a
plot of the detected speech regions in the input signal.
Examples
Read in an audio signal. Clip the audio signal to 20 seconds.
[audioIn,fs] = audioread('Rainbow-16-8-mono-114secs.wav');
audioIn = audioIn(1:20*fs);Call detectSpeech. Specify no output arguments to display a plot of the detected speech regions.
detectSpeech(audioIn,fs);

The detectSpeech function uses a thresholding algorithm based on energy and spectral spread per analysis frame. You can modify the Window, OverlapLength, and MergeDistance to fine-tune the algorithm for your specific needs.
windowDuration =0.074; % seconds numWindowSamples = round(windowDuration*fs); win = hamming(numWindowSamples,'periodic'); percentOverlap =
35; overlap = round(numWindowSamples*percentOverlap/100); mergeDuration =
0.44; mergeDist = round(mergeDuration*fs); detectSpeech(audioIn,fs,"Window",win,"OverlapLength",overlap,"MergeDistance",mergeDist)

Read in an audio file containing speech. Split the audio signal into a first half and a second half.
[audioIn,fs] = audioread('Counting-16-44p1-mono-15secs.wav');
firstHalf = audioIn(1:floor(numel(audioIn)/2));
secondHalf = audioIn(numel(firstHalf):end);Call detectSpeech on the first half of the audio signal. Specify two output arguments to return the indices corresponding to regions of detected speech and the thresholds used for the decision.
[speechIndices,thresholds] = detectSpeech(firstHalf,fs);
Call detectSpeech on the second half with no output arguments to plot the regions of detected speech. Specify the thresholds determined from the previous call to detectSpeech.
detectSpeech(secondHalf,fs,'Thresholds',thresholds)
Working with Large Data Sets
Reusing speech detection thresholds provides significant computational efficiency when you work with large data sets, or when you deploy a deep learning or machine learning pipeline for real-time inference. Download and extract the data set [1].
url = 'https://storage.googleapis.com/download.tensorflow.org/data/speech_commands_v0.01.tar.gz'; downloadFolder = tempdir; datasetFolder = fullfile(downloadFolder,'google_speech'); if ~exist(datasetFolder,'dir') disp('Downloading data set (1.9 GB) ...') untar(url,datasetFolder) end
Create an audio datastore to point to the recordings. Use the folder names as labels.
ads = audioDatastore(datasetFolder,'IncludeSubfolders',true,'LabelSource','foldernames');
Reduce the data set by 95% for the purposes of this example.
ads = splitEachLabel(ads,0.05,'Exclude','_background_noise');
Create two datastores: one for training and one for testing.
[adsTrain,adsTest] = splitEachLabel(ads,0.8);
Compute the average thresholds over the training data set.
thresholds = zeros(numel(adsTrain.Files),2); for ii = 1:numel(adsTrain.Files) [audioIn,adsInfo] = read(adsTrain); [~,thresholds(ii,:)] = detectSpeech(audioIn,adsInfo.SampleRate); end thresholdAverage = mean(thresholds,1);
Use the precomputed thresholds to detect speech regions on files from the test data set. Plot the detected region for three files.
[audioIn,adsInfo] = read(adsTest);
detectSpeech(audioIn,adsInfo.SampleRate,'Thresholds',thresholdAverage);
[audioIn,adsInfo] = read(adsTest);
detectSpeech(audioIn,adsInfo.SampleRate,'Thresholds',thresholdAverage);
[audioIn,adsInfo] = read(adsTest);
detectSpeech(audioIn,adsInfo.SampleRate,'Thresholds',thresholdAverage);
References
[1] Warden, Pete. "Speech Commands: A Public Dataset for Single Word Speech Recognition." Distributed by TensorFlow. Creative Commons Attribution 4.0 License.
Read in an audio file and listen to it. Plot the spectrogram.
[audioIn,fs] = audioread('Counting-16-44p1-mono-15secs.wav'); sound(audioIn,fs) spectrogram(audioIn,hann(1024,'periodic'),512,1024,fs,'yaxis')

For machine learning applications, you often want to extract features from an audio signal. Call the spectralEntropy function on the audio signal, then plot the histogram to display the distribution of spectral entropy.
entropy = spectralEntropy(audioIn,fs); numBins = 40; histogram(entropy,numBins,'Normalization','probability') title('Spectral Entropy of Audio Signal')

Depending on your application, you might want to extract spectral entropy from only the regions of speech. The resulting statistics are more characteristic of the speaker and less characteristic of the channel. Call detectSpeech on the audio signal and then create a new signal that contains only the regions of detected speech.
speechIndices = detectSpeech(audioIn,fs); speechSignal = []; for ii = 1:size(speechIndices,1) speechSignal = [speechSignal;audioIn(speechIndices(ii,1):speechIndices(ii,2))]; end
Listen to the speech signal and plot the spectrogram.
sound(speechSignal,fs) spectrogram(speechSignal,hann(1024,'periodic'),512,1024,fs,'yaxis')

Call the spectralEntropy function on the speech signal and then plot the histogram to display the distribution of spectral entropy.
entropy = spectralEntropy(speechSignal,fs); histogram(entropy,numBins,'Normalization','probability') title('Spectral Entropy of Speech Signal')

Input Arguments
Name-Value Arguments
Output Arguments
Algorithms
The detectSpeech algorithm is based on [1], although modified so that
the statistics to threshold are short-term energy and spectral spread, instead of short-term
energy and spectral centroid. The diagram and steps provide a high-level overview of the
algorithm. For details, see [1].
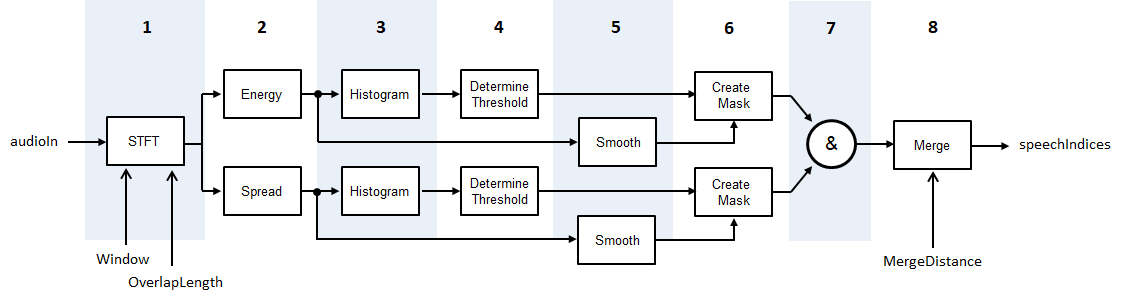
The audio signal is converted to a time-frequency representation using the specified
WindowandOverlapLength.The short-term energy and spectral spread is calculated for each frame. The spectral spread is calculated according to
spectralSpread.Histograms are created for both the short-term energy and spectral spread distributions.
For each histogram, a threshold is determined according to , where M1 and M2 are the first and second local maxima, respectively. W is set to
5.Both the spectral spread and the short-term energy are smoothed across time by passing through successive five-element moving median filters.
Masks are created by comparing the short-term energy and spectral spread with their respective thresholds. To declare a frame as containing speech, a feature must be above its threshold.
The masks are combined. For a frame to be declared as speech, both the short-term energy and the spectral spread must be above their respective thresholds.
Regions declared as speech are merged if the distance between them is less than
MergeDistance.
References
[1] Giannakopoulos, Theodoros. "A Method for Silence Removal and Segmentation of Speech Signals, Implemented in MATLAB", (University of Athens, Athens, 2009).
Extended Capabilities
Version History
Introduced in R2020a