ocsvm
Fit one-class support vector machine (SVM) model for anomaly detection
Since R2022b
Syntax
Description
Use the ocsvm function to fit a one-class support vector
machine (SVM) model for outlier detection and novelty detection.
Outlier detection (detecting anomalies in training data) — Use the output argument
tfofocsvmto identify anomalies in training data.Novelty detection (detecting anomalies in new data with uncontaminated training data) — Create a
OneClassSVMobject by passing uncontaminated training data (data with no outliers) toocsvm. Detect anomalies in new data by passing the object and the new data to the object functionisanomaly.
Mdl = ocsvm(Tbl)OneClassSVM object
(one-class SVM model object) for predictor data in the table
Tbl.
Mdl = ocsvm(___,Name=Value)ContaminationFraction=0.1
Examples
Detect outliers (anomalies in training data) by using the ocsvm function.
Load the sample data set NYCHousing2015.
load NYCHousing2015The data set includes 10 variables with information on the sales of properties in New York City in 2015. Display a summary of the data set.
summary(NYCHousing2015)
double
Values:
Min 1
Median 3
Max 5
NEIGHBORHOOD: 91446×1 cell array of character vectors
BUILDINGCLASSCATEGORY: 91446×1 cell array of character vectors
RESIDENTIALUNITS: 91446×1 double
Values:
Min 0
Median 1
Max 8759
COMMERCIALUNITS: 91446×1 double
Values:
Min 0
Median 0
Max 612
LANDSQUAREFEET: 91446×1 double
Values:
Min 0
Median 1700
Max 2.9306e+07
GROSSSQUAREFEET: 91446×1 double
Values:
Min 0
Median 1056
Max 8.9422e+06
YEARBUILT: 91446×1 double
Values:
Min 0
Median 1939
Max 2016
SALEPRICE: 91446×1 double
Values:
Min 0
Median 3.3333e+05
Max 4.1111e+09
SALEDATE: 91446×1 datetime
Values:
Min 01-Jan-2015
Median 09-Jul-2015
Max 31-Dec-2015
The SALEDATE column is a datetime array, which is not supported by ocsvm. Create columns for the month and day numbers of the datetime values, and delete the SALEDATE column.
[~,NYCHousing2015.MM,NYCHousing2015.DD] = ymd(NYCHousing2015.SALEDATE); NYCHousing2015.SALEDATE = [];
Train a one-class SVM model for NYCHousing2015. Specify the fraction of anomalies in the training observations as 0.1, and specify the first variable (BOROUGH) as a categorical predictor. The first variable is a numeric array, so ocsvm assumes it is a continuous variable unless you specify the variable as a categorical variable. In addition, specify StandardizeData as true to standardize the input data, because the predictors have largely different scales. Set KernelScale to "auto" so that the software selects an appropriate kernel scale parameter using a heuristic procedure.
rng("default") % For reproducibility [Mdl,tf,scores] = ocsvm(NYCHousing2015,ContaminationFraction=0.1, ... CategoricalPredictors=1,StandardizeData=true, ... KernelScale="auto");
Mdl is a OneClassSVM object. ocsvm also returns the anomaly indicators (tf) and anomaly scores (scores) for the training data NYCHousing2015.
Plot a histogram of the score values. Create a vertical line at the score threshold corresponding to the specified fraction.
histogram(scores) xline(Mdl.ScoreThreshold,"r-",["Threshold" Mdl.ScoreThreshold])

If you want to identify anomalies with a different contamination fraction (for example, 0.01), you can train a new one-class SVM model.
rng("default") % For reproducibility [newMdl,newtf,scores] = ocsvm(NYCHousing2015, ... ContaminationFraction=0.01,CategoricalPredictors=1, ... KernelScale="auto");
If you want to identify anomalies with a different score threshold value (for example, -0.7), you can pass the OneClassSVM object, the training data, and a new threshold value to the isanomaly function.
[newtf,scores] = isanomaly(Mdl,NYCHousing2015,ScoreThreshold=-0.7);
Note that changing the contamination fraction or score threshold changes the anomaly indicators only, and does not affect the anomaly scores. Therefore, if you do not want to compute the anomaly scores again by using ocsvm or isanomaly, you can obtain a new anomaly indicator with the existing score values.
Change the fraction of anomalies in the training data to 0.01.
newContaminationFraction = 0.01;
Find a new score threshold by using the quantile function.
newScoreThreshold = quantile(scores,1-newContaminationFraction)
newScoreThreshold = -0.3745
Obtain a new anomaly indicator.
newtf = scores > newScoreThreshold;
Create a OneClassSVM object for uncontaminated training observations by using the ocsvm function. Then detect novelties (anomalies in new data) by passing the object and the new data to the object function isanomaly.
Load the 1994 census data stored in census1994.mat. The data set consists of demographic data from the US Census Bureau to predict whether an individual makes over $50,000 per year.
load census1994census1994 contains the training data set adultdata and the test data set adulttest.
ocsvm does not use observations with missing values. Remove missing values in the data sets to reduce memory consumption and speed up training.
adultdata = rmmissing(adultdata); adulttest = rmmissing(adulttest);
Train a one-class SVM for adultdata. Assume that adultdata does not contain outliers. Specify StandardizeData as true to standardize the input data, and set KernelScale to "auto" to let the function select an appropriate kernel scale parameter using a heuristic procedure.
rng("default") % For reproducibility [Mdl,~,s] = ocsvm(adultdata,StandardizeData=true,KernelScale="auto");
Mdl is a OneClassSVM object. If you do not specify the ContaminationFraction name-value argument as a value greater than 0, then ocsvm treats all training observations as normal observations. The function sets the score threshold to the maximum score value. Display the threshold value.
Mdl.ScoreThreshold
ans = 0.0322
Find anomalies in adulttest by using the trained one-class SVM model. Because you specified StandardizeData=true when you trained the model, the isanomaly function standardizes the input data by using the predictor means and standard deviations of the training data stored in the Mu and Sigma properties, respectively.
[tf_test,s_test] = isanomaly(Mdl,adulttest);
The isanomaly function returns the anomaly indicators tf_test and scores s_test for adulttest. By default, isanomaly identifies observations with scores above the threshold (Mdl.ScoreThreshold) as anomalies.
Create histograms for the anomaly scores s and s_test. Create a vertical line at the threshold of the anomaly scores.
h1 = histogram(s,NumBins=50,Normalization="probability"); hold on h2 = histogram(s_test,h1.BinEdges,Normalization="probability"); xline(Mdl.ScoreThreshold,"r-",join(["Threshold" Mdl.ScoreThreshold])) h1.Parent.YScale = 'log'; h2.Parent.YScale = 'log'; legend("Training Data","Test Data",Location="north") hold off
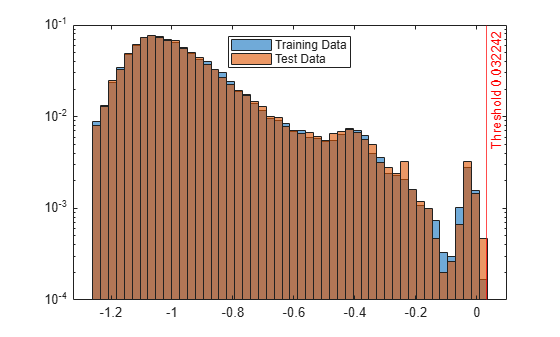
Display the observation index of the anomalies in the test data.
find(tf_test)
ans = 0×1 empty double column vector
The anomaly score distribution of the test data is similar to that of the training data, so isanomaly does not detect any anomalies in the test data with the default threshold value. You can specify a different threshold value by using the ScoreThreshold name-value argument. For an example, see Specify Anomaly Score Threshold.
Input Arguments
Name-Value Arguments
Output Arguments
More About
Tips
After training a model, you can generate C/C++ code that finds anomalies for new data. Generating C/C++ code requires MATLAB® Coder™. For details, see Code Generation of the
isanomalyfunction and Introduction to Code Generation for Statistics and Machine Learning Functions.
Algorithms
ocsvmconsidersNaN,''(empty character vector),""(empty string),<missing>, and<undefined>values inTblandNaNvalues inXto be missing values.ocsvmdoes not use observations with some missing values. The function assigns the anomaly score ofNaNand anomaly indicator offalse(logical0) to the observations.ocsvmminimizes the regularized objective function using a Limited-memory Broyden-Fletcher-Goldfarb-Shanno (LBFGS) solver with ridge (L2) regularization. Ifocsvmrequires more memory than the value ofBlockSizeto hold the transformed predictor data, then the function uses a block-wise strategy.When
ocsvmuses a block-wise strategy, it implements LBFGS by distributing the calculation of the loss and gradient among different parts of the data at each iteration. Also,ocsvmrefines the initial estimates of the linear coefficients and the bias term by fitting the model locally to parts of the data and combining the coefficients by averaging. If you specifyVerbose=1, thenocsvmdisplays diagnostic information for each data pass.When
ocsvmdoes not use a block-wise strategy, the initial estimates are zeros. If you specifyVerbose=1, thenocsvmdisplays diagnostic information for each iteration.
Alternative Functionality
You can also use the fitcsvm function to train a one-class SVM model for
anomaly detection.
The
ocsvmfunction provides a simpler and preferred workflow for anomaly detection than thefitcsvmfunction.The
ocsvmfunction returns aOneClassSVMobject, anomaly indicators, and anomaly scores. You can use the outputs to identify anomalies in training data. To find anomalies in new data, you can use theisanomalyobject function ofOneClassSVM. Theisanomalyfunction returns anomaly indicators and scores for the new data.The
fitcsvmfunction supports both one-class and binary classification. If the class label variable contains only one class (for example, a vector of ones),fitcsvmtrains a model for one-class classification and returns aClassificationSVMobject. To identify anomalies, you must first compute anomaly scores by using theresubPredictorpredictobject function ofClassificationSVM, and then identify anomalies by finding observations that have negative scores.Note that a large positive anomaly score indicates an anomaly in
ocsvm, whereas a negative score indicates an anomaly inpredictofClassificationSVM.
The
ocsvmfunction finds the decision boundary based on the primal form of SVM, whereas thefitcsvmfunction finds the decision boundary based on the dual form of SVM.The solver in
ocsvmis computationally less expensive than the solver infitcsvmfor a large data set (large n). Unlike solvers infitcsvm, which require computation of the n-by-n Gram matrix, the solver inocsvmonly needs to form a matrix of size n-by-m. Here, m is the number of dimensions of expanded space, which is typically much less than n for big data.