kfoldMargin
Classification margins for cross-validated ECOC model
Description
margin = kfoldMargin(CVMdl)ClassificationPartitionedECOC)
CVMdl. For every fold, kfoldMargin
computes classification margins for validation-fold observations using an ECOC model
trained on training-fold observations. CVMdl.X contains both sets
of observations.
margin = kfoldMargin(CVMdl,Name,Value)
Examples
Load Fisher's iris data set. Specify the predictor data X, the response data Y, and the order of the classes in Y.
load fisheriris X = meas; Y = categorical(species); classOrder = unique(Y); rng(1); % For reproducibility
Train and cross-validate an ECOC model using support vector machine (SVM) binary classifiers. Standardize the predictor data using an SVM template, and specify the class order.
t = templateSVM('Standardize',1); CVMdl = fitcecoc(X,Y,'CrossVal','on','Learners',t,'ClassNames',classOrder);
CVMdl is a ClassificationPartitionedECOC model. By default, the software implements 10-fold cross-validation. You can specify a different number of folds using the 'KFold' name-value pair argument.
Estimate the margins for validation-fold observations. Display the distribution of the margins using a box plot.
margin = kfoldMargin(CVMdl);
boxplot(margin)
title('Distribution of Margins')
One way to perform feature selection is to compare cross-validation margins from multiple models. Based solely on this criterion, the classifier with the greatest margins is the best classifier.
Load Fisher's iris data set. Specify the predictor data X, the response data Y, and the order of the classes in Y.
load fisheriris X = meas; Y = categorical(species); classOrder = unique(Y); % Class order rng(1); % For reproducibility
Define the following two data sets.
fullXcontains all the predictors.partXcontains the petal dimensions.
fullX = X; partX = X(:,3:4);
For each predictor set, train and cross-validate an ECOC model using SVM binary classifiers. Standardize the predictors using an SVM template, and specify the class order.
t = templateSVM('Standardize',1); CVMdl = fitcecoc(fullX,Y,'CrossVal','on','Learners',t,... 'ClassNames',classOrder); PCVMdl = fitcecoc(partX,Y,'CrossVal','on','Learners',t,... 'ClassNames',classOrder);
CVMdl and PCVMdl are ClassificationPartitionedECOC models. By default, the software implements 10-fold cross-validation.
Estimate the margins for each classifier. Use loss-based decoding for aggregating the binary learner results. For each model, display the distribution of the margins using a boxplot.
fullMargins = kfoldMargin(CVMdl,'Decoding','lossbased'); partMargins = kfoldMargin(PCVMdl,'Decoding','lossbased'); boxplot([fullMargins partMargins],'Labels',{'All Predictors','Two Predictors'}) title('Distributions of Margins')
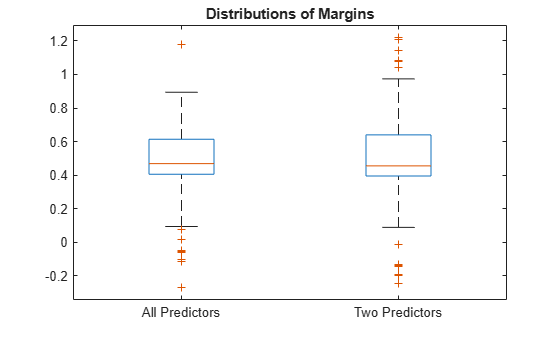
The margin distributions are approximately the same.
Input Arguments
Name-Value Arguments
Output Arguments
More About
References
Extended Capabilities
Version History
Introduced in R2014b
See Also
ClassificationPartitionedECOC | ClassificationECOC | kfoldEdge | margin | kfoldPredict | fitcecoc | statset