predict
Predict labels using classification tree model
Syntax
Description
[ also returns the following, using any of the input
argument combinations in the previous syntaxes:label,score,node,cnum]
= predict(___)
A matrix of classification scores (
score) indicating the likelihood that a label comes from a particular class. For classification trees, scores are posterior probabilities. For each observation inX, the predicted class label corresponds to the minimum expected misclassification cost among all classes.A vector of predicted node numbers for the classification (
node).A vector of predicted class numbers for the classification (
cnum).
Examples
Examine predictions for a few rows in a data set left out of training.
Load Fisher's iris data set.
load fisheririsPartition the data into training (50%) and validation (50%) sets.
n = size(meas,1);
rng(1) % For reproducibility
idxTrn = false(n,1);
idxTrn(randsample(n,round(0.5*n))) = true;
idxVal = idxTrn == false; Grow a classification tree using the training set.
Mdl = fitctree(meas(idxTrn,:),species(idxTrn));
Predict labels for the validation data, and display several predicted labels. Count the number of misclassified observations.
label = predict(Mdl,meas(idxVal,:)); label(randsample(numel(label),5))
ans = 5×1 cell
{'setosa' }
{'setosa' }
{'setosa' }
{'virginica' }
{'versicolor'}
numMisclass = sum(~strcmp(label,species(idxVal)))
numMisclass = 3
The software misclassifies three out-of-sample observations.
Load Fisher's iris data set.
load fisheririsPartition the data into training (50%) and validation (50%) sets.
n = size(meas,1);
rng(1) % For reproducibility
idxTrn = false(n,1);
idxTrn(randsample(n,round(0.5*n))) = true;
idxVal = idxTrn == false;Grow a classification tree using the training set, and then view it.
Mdl = fitctree(meas(idxTrn,:),species(idxTrn)); view(Mdl,"Mode","graph")
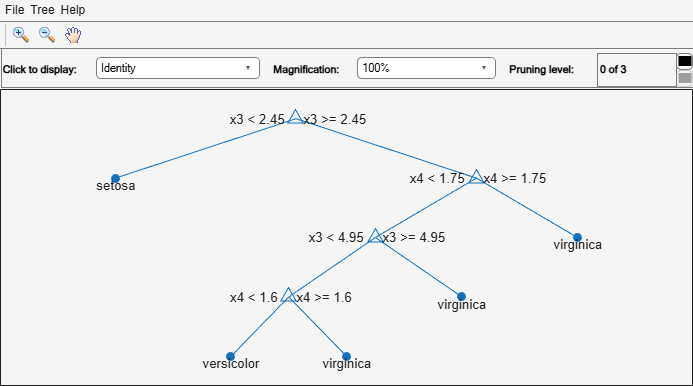
The resulting tree has four levels.
Estimate posterior probabilities for the test set using subtrees pruned to levels 1 and 3. Display several posterior probabilities.
[~,Posterior] = predict(Mdl,meas(idxVal,:), ...
Subtrees=[1 3]);
Mdl.ClassNamesans = 3×1 cell
{'setosa' }
{'versicolor'}
{'virginica' }
Posterior(randsample(size(Posterior,1),5),:,:)
ans =
ans(:,:,1) =
1.0000 0 0
1.0000 0 0
1.0000 0 0
0 0 1.0000
0 0.8571 0.1429
ans(:,:,2) =
0.3733 0.3200 0.3067
0.3733 0.3200 0.3067
0.3733 0.3200 0.3067
0.3733 0.3200 0.3067
0.3733 0.3200 0.3067
The elements of Posterior are class posterior probabilities:
Rows correspond to observations in the validation set.
Columns correspond to the classes as listed in
Mdl.ClassNames.Pages correspond to the subtrees.
The subtree pruned to level 1 is more sure of its predictions than the subtree pruned to level 3 (that is, the root node).
Input Arguments
Output Arguments
More About
Algorithms
predict generates predictions by following the branches
of tree until it reaches a leaf node or a missing value. If predict reaches a leaf node, it returns the classification of that
node.
If predict reaches a node with a missing value for a
predictor, its behavior depends on the setting of the Surrogate name-value
argument when fitctree constructs tree.
Surrogate="off"(default) —predictreturns the label with the largest number of training samples that reach the node.Surrogate="on"—predictuses the best surrogate split at the node. If all surrogate split variables with positive predictive measure of association are missing,predictreturns the label with the largest number of training samples that reach the node. For a definition, see Predictive Measure of Association.
Alternative Functionality
Simulink Block
To integrate the prediction of a classification tree model into Simulink®, you can use the ClassificationTree
Predict block in the Statistics and Machine Learning Toolbox™ library or a MATLAB® Function block with the predict function. For examples,
see Predict Class Labels Using ClassificationTree Predict Block and Predict Class Labels Using MATLAB Function Block.
When deciding which approach to use, consider the following:
If you use the Statistics and Machine Learning Toolbox library block, you can use the Fixed-Point Tool (Fixed-Point Designer) to convert a floating-point model to fixed point.
Support for variable-size arrays must be enabled for a MATLAB Function block with the
predictfunction.If you use a MATLAB Function block, you can use MATLAB functions for preprocessing or post-processing before or after predictions in the same MATLAB Function block.
Extended Capabilities
Version History
Introduced in R2011a