Divide
Divide one input by another
Libraries:
Simulink /
Math Operations
HDL Coder /
HDL Floating Point Operations
HDL Coder /
Math Operations
Description
The Divide block outputs the result of dividing its first input by its second. The inputs can be scalars, a scalar and a nonscalar, or two nonscalars that have the same dimensions. This block supports only complex input values at division ports when all ports have the same single or double data type.
The Divide block is functionally a Product block that has two block parameter values preset:
Multiplication —
Element-wise(.*)Number of Inputs —
*/
Setting nondefault values for either of those parameters can change a Divide block to be functionally equivalent to a Product block or a Product of Elements block.
Examples
This example shows how to perform element-wise (.*) division of two inputs using the Divide block. In this example, the Divide block divides two scalars, a vector by a scalar, a scalar by a vector, and two matrices.
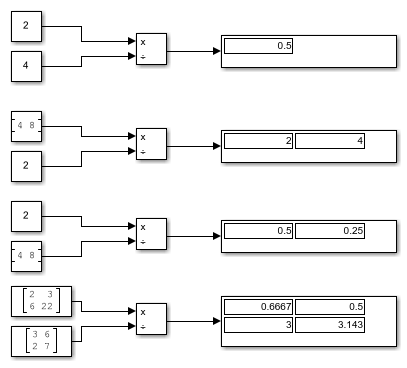
Ports
Input
Output
Parameters
Main
Control two properties of the block:
The number of input ports on the block
Whether each input is multiplied or divided into the output
When you specify:
1or*or/The block has one input port. In element-wise mode, the block processes the input as described for the Product of Elements block. In matrix mode, if the parameter value is
1or*, the block outputs the input value. If the value is/, the input must be a square matrix (including a scalar as a degenerate case) and the block outputs the matrix inverse. See Element-Wise Mode and Matrix Mode for more information.Integer value > 1
The block has the number of inputs given by the integer value. The inputs are multiplied together in element-wise mode or matrix mode, as specified by the Multiplication parameter. See Element-Wise Mode and Matrix Mode for more information.
Unquoted string of two or more
*and/charactersThe block has the number of inputs given by the length of the character vector. Each input that corresponds to a
*character is multiplied into the output. Each input that corresponds to a/character is divided into the output. The operations occur in element-wise mode or matrix mode, as specified by the Multiplication parameter. See Element-Wise Mode and Matrix Mode for more information.
Programmatic Use
Block Parameter:
Inputs |
| Type: character vector |
Values:
'2' | '*' | '**' | '*/' | '*/*' |
... |
Default:
'*/' |
Specify whether the block performs Element-wise(.*) or
Matrix(*) multiplication.
Programmatic Use
Block Parameter:
Multiplication |
| Type: character vector |
Values:
'Element-wise(.*)' | 'Matrix(*)' |
Default:
'Element-wise(.*)' |
Specify how to apply the function along specified dimensions.
All dimensions— Apply function for all input values for all dimensions.Specified dimension— Apply function for all input values for specified dimension.
For example, in this model, Multiplication is set to
Element-wise(.*), and Apply over
is set to All dimensions. The block returns the product of
all values from all dimensions.
![2D matrix with Constant block value [1 2 3;7 6 4] as input to Product block configured for all dimensions](prod_alldim.png)
Dependencies
To enable this parameter, set Number of inputs to
* and Multiplication to
Element-wise (.*).
Programmatic Use
Block Parameter:
CollapseMode |
| Type: character vector |
Values:
'All dimensions' | 'Specified dimension' |
Default:
'All dimensions' |
Specify the dimension along which to multiply, as a
positive integer. For example, for a 2-D matrix, 1
applies the function to each column, and 2 applies
the function to each row.
For example, in this model,
Multiplication is set to
Element-wise(.*),
Apply over is set to
Specified dimension,
and Dimension is set to
2. The block returns the
product of all values from each row.
![2D matrix with Constant block value [1 2 3;7 6 4] as input to Product block configured for dimension 2](prod_2dim.png)
Dependencies
To enable this parameter:
Set Number of inputs to
*Set Multiplication to
Element-wise (.*)Set Apply over to
Specified dimension
Programmatic Use
Block
Parameter:
CollapseDim |
| Type: character vector |
Values:
'1' | '2' | ... |
Default:
'1' |
Specify the time interval between samples. To inherit the sample time, set this
parameter to -1. For more information, see Specify Sample Time.
Dependencies
This parameter is visible only if you set it to a value other than
-1. To learn more, see Blocks for Which Sample Time Is Not Recommended.
Programmatic Use
To set the block parameter value programmatically, use
the set_param function.
| Parameter: | SampleTime |
| Values: | "-1" (default) | scalar or vector in quotes |
Signal Attributes
Specify if input signals must all have the same data type. If you enable this parameter, then an error occurs during simulation if the input signal types are different.
Programmatic Use
Block Parameter:
InputSameDT |
| Type: character vector |
Values:
'off' | 'on' |
Default:
'off' |
Lower value of the output range that the software checks.
The software uses the minimum to perform:
Parameter range checking (see Specify Minimum and Maximum Values for Block Parameters) for some blocks.
Simulation range checking (see Specify Signal Ranges and Enable Simulation Range Checking).
Automatic scaling of fixed-point data types.
Optimization of the code that you generate from the model. This optimization can remove algorithmic code and affect the results of some simulation modes such as SIL or external mode. For more information, see Optimize using the specified minimum and maximum values (Embedded Coder).
Tips
Output minimum does not saturate or clip the actual output signal. Use the Saturation block instead.
Programmatic Use
To set the block parameter value programmatically, use
the set_param function.
| Parameter: | OutMin |
| Values: | '[]' (default) | scalar in quotes |
Upper value of the output range that the software checks.
The software uses the maximum value to perform:
Parameter range checking (see Specify Minimum and Maximum Values for Block Parameters) for some blocks.
Simulation range checking (see Specify Signal Ranges and Enable Simulation Range Checking).
Automatic scaling of fixed-point data types.
Optimization of the code that you generate from the model. This optimization can remove algorithmic code and affect the results of some simulation modes such as SIL or external mode. For more information, see Optimize using the specified minimum and maximum values (Embedded Coder).
Tips
Output maximum does not saturate or clip the actual output signal. Use the Saturation block instead.
Programmatic Use
To set the block parameter value programmatically, use
the set_param function.
| Parameter: | OutMax |
| Values: | '[]' (default) | scalar in quotes |
Choose the data type for the output. The type can be inherited, specified
directly, or expressed as a data type object such as
Simulink.NumericType. For more information, see
Control Data Types of Signals.
When you select an inherited option, the block behaves as follows:
Inherit: Inherit via internal rule— Simulink® chooses a data type to balance numerical accuracy, performance, and generated code size, while taking into account the properties of the embedded target hardware. If you change the embedded target settings, the data type selected by the internal rule might change. For example, if the block multiplies an input of typeint8by a gain ofint16andASIC/FPGAis specified as the targeted hardware type, the output data type issfix24. IfUnspecified (assume 32-bit Generic), in other words, a generic 32-bit microprocessor, is specified as the target hardware, the output data type isint32. If none of the word lengths provided by the target microprocessor can accommodate the output range, Simulink software displays an error in the Diagnostic Viewer.It is not always possible for the software to optimize code efficiency and numerical accuracy at the same time. If the internal rule doesn’t meet your specific needs for numerical accuracy or performance, use one of the following options:
Specify the output data type explicitly.
Use the simple choice of
Inherit: Same as input.Explicitly specify a default data type such as
fixdt(1,32,16)and then use the Fixed-Point Tool to propose data types for your model. For more information, seefxptdlg(Fixed-Point Designer).To specify your own inheritance rule, use
Inherit: Inherit via back propagationand then use a Data Type Propagation block. Examples of how to use this block are available in the Signal Attributes library Data Type Propagation Examples block.
Inherit: Inherit via back propagation— Use data type of the driving block.Inherit: Same as first input— Use data type of first input signal.
Dependencies
When input is a floating-point data type smaller than single
precision, the Inherit: Inherit via internal
rule output data type depends on the setting
of the Inherit floating-point output type smaller than single precision configuration parameter. Data types are smaller than single
precision when the number of bits needed to encode the data type is
less than the 32 bits needed to encode the single-precision data
type. For example, half and
int16 are smaller than single
precision.
Programmatic Use
Block Parameter:
OutDataTypeStr |
| Type: character vector |
Values: 'Inherit:
Inherit via internal rule |
'Inherit: Same as first input' |
'Inherit: Inherit via back
propagation' | 'double'
| 'single' | 'int8' |
'uint8' |
'int16' |
'uint16' |
'int32' |
'uint32' |
'int64' |
'uint64' |
'fixdt(1,16)' |
'fixdt(1,16,0)' |
'fixdt(1,16,2^0,0)' |
'<data type
expression>' |
Default: 'Inherit:
Inherit via internal rule' |
Select this parameter to prevent the fixed-point tools from overriding the Output data type you specify on the block. For more information, see Use Lock Output Data Type Setting (Fixed-Point Designer).
Programmatic Use
To set the block parameter value programmatically, use
the set_param function.
| Parameter: | LockScale |
| Values: | 'off' (default) | 'on' |
Select the rounding mode for fixed-point operations. You can select:
CeilingRounds positive and negative numbers toward positive infinity. Equivalent to the MATLAB®
ceilfunction.ConvergentRounds number to the nearest representable value. If a tie occurs, rounds to the nearest even integer. Equivalent to the Fixed-Point Designer™
convergentfunction.FloorRounds positive and negative numbers toward negative infinity. Equivalent to the MATLAB
floorfunction.NearestRounds number to the nearest representable value. If a tie occurs, rounds toward positive infinity. Equivalent to the Fixed-Point Designer
nearestfunction.RoundRounds number to the nearest representable value. If a tie occurs, rounds positive numbers toward positive infinity and rounds negative numbers toward negative infinity. Equivalent to the Fixed-Point Designer
roundfunction.SimplestChooses between rounding toward floor and rounding toward zero to generate rounding code that is as efficient as possible. This rounding mode is affected by these configuration parameters on the Hardware Implementation pane.
If the Signed integer division rounds to parameter is set to
ZeroorUndefined,Simplestresolves to zero.If the Signed integer division rounds to parameter is set to
Floor,Simplestresolves tofloor.
ZeroRounds number toward zero. Equivalent to the MATLAB
fixfunction.
For more information, see Rounding Modes (Fixed-Point Designer).
Block parameters always round to the nearest representable value. To control the rounding of a block parameter, enter an expression using a MATLAB rounding function into the mask field.
Programmatic Use
Block Parameter:
RndMeth |
| Type: character vector |
Values:
'Ceiling' | 'Convergent' | 'Floor' | 'Nearest' |
'Round' | 'Simplest' | 'Zero' |
Default:
'Floor' |
Specify whether overflows saturate or wrap.
on— Overflows saturate to either the minimum or maximum value that the data type can represent.off— Overflows wrap to the appropriate value that the data type can represent.
For example, the maximum value that the signed 8-bit integer int8
can represent is 127. Any block operation result greater than this maximum value causes
overflow of the 8-bit integer.
With this parameter selected, the block output saturates at 127. Similarly, the block output saturates at a minimum output value of -128.
With this parameter cleared, the software interprets the overflow-causing value as
int8, which can produce an unintended result. For example, a block result of 130 (binary 1000 0010) expressed asint8is -126.
Tips
Consider selecting this parameter when your model has a possible overflow and you want explicit saturation protection in the generated code.
Consider clearing this parameter when you want to optimize efficiency of your generated code. Clearing this parameter also helps you to avoid overspecifying how a block handles out-of-range signals. For more information, see Troubleshoot Signal Range Errors.
When you select this parameter, saturation applies to every internal operation on the block, not just the output or result.
In general, the code generation process can detect when overflow is not possible. In this case, the code generator does not produce saturation code.
Programmatic Use
To set the block parameter value programmatically, use
the set_param function.
| Parameter: | SaturateOnIntegerOverflow |
| Values: | 'off' (default) | 'on' |
Select the category of data to specify.
Inherit— Inheritance rules for data types. SelectingInheritenables a second menu/text box to the right where you can select the inheritance mode.Built in— Built-in data types. SelectingBuilt inenables a second menu/text box to the right where you can select a built-in data type.Fixed point— Fixed-point data types. SelectingFixed pointenables additional parameters that you can use to specify a fixed-point data type.Expression— Expressions that evaluate to data types. SelectingExpressionenables a second menu/text box to the right, where you can enter the expression.
For more information, see Specify Data Types Using Data Type Assistant.
Dependencies
To enable this parameter, click the Show data type assistant button.
Select the data type override mode for this signal.
When you select
Inherit, Simulink inherits the data type override setting from its context, that is, from the block,Simulink.Signalobject or Stateflow® chart in Simulink that is using the signal.When you select
Off, Simulink ignores the data type override setting of its context and uses the fixed-point data type specified for the signal.
For more information, see Specify Data Types Using Data Type Assistant in the Simulink documentation.
Dependencies
To enable this parameter, set Mode to Built
in or Fixed point.
Tips
The ability to turn off data type override for an individual data type provides greater control over the data types in your model when you apply data type override. For example, you can use this option to ensure that data types meet the requirements of downstream blocks regardless of the data type override setting.
Specify whether the fixed-point data is signed or unsigned. Signed data can represent positive and negative values, but unsigned data represents positive values only.
Signed, specifies the fixed-point data as signed.Unsigned, specifies the fixed-point data as unsigned.
For more information, see Specify Data Types Using Data Type Assistant.
Dependencies
To enable this parameter, set the Mode to Fixed
point.
Specify the bit size of the word that holds the quantized integer. For more information, see Specifying a Fixed-Point Data Type.
Dependencies
To enable this parameter, set Mode to
Fixed point.
Specify fraction length for fixed-point data type as a positive or negative integer. For more information, see Specifying a Fixed-Point Data Type.
Dependencies
To enable this parameter, set Scaling to
Binary point.
Specify the method for scaling your fixed-point data to avoid overflow conditions and minimize quantization errors. For more information, see Specifying a Fixed-Point Data Type.
Dependencies
To enable this parameter, set Mode to
Fixed point.
Specify slope for the fixed-point data type. For more information, see Specifying a Fixed-Point Data Type.
Dependencies
To enable this parameter, set Scaling to
Slope and bias.
Specify bias for the fixed-point data type as any real number. For more information, see Specifying a Fixed-Point Data Type.
Dependencies
To enable this parameter, set Scaling to
Slope and bias.
Block Characteristics
Data Types |
|
Direct Feedthrough |
|
Multidimensional Signals |
|
Variable-Size Signals |
|
Zero-Crossing Detection |
|