Quadruped Robot Locomotion Using DDPG Agent
This example shows how to train a quadruped robot to walk using a deep deterministic policy gradient (DDPG) agent. The robot in this example is modeled using Simscape™ Multibody™. For more information on DDPG agents, see Deep Deterministic Policy Gradient (DDPG) Agent.
Fix Random Number Stream for Reproducibility
The example code might involve computation of random numbers at several stages. Fixing the random number stream at the beginning of some sections in the example code preserves the random number sequence in the section every time you run it, which increases the likelihood of reproducing the results. For more information, see Results Reproducibility.
Fix the random number stream with seed 0 and random number algorithm Mersenne Twister. For more information on controlling the seed used for random number generation, see rng.
previousRngState = rng(0,"twister");The output previousRngState is a structure that contains information about the previous state of the stream. You will restore the state at the end of the example.
Load the necessary parameters into the base workspace in MATLAB® using the Script initializeRobotParameters provided with the example.
initializeRobotParameters;
Quadruped Robot Model
The environment for this example is a quadruped robot, and the training goal is to make the robot walk in a straight line using minimal control effort.
Open the model.
mdl = "rlQuadrupedRobot";
open_system(mdl)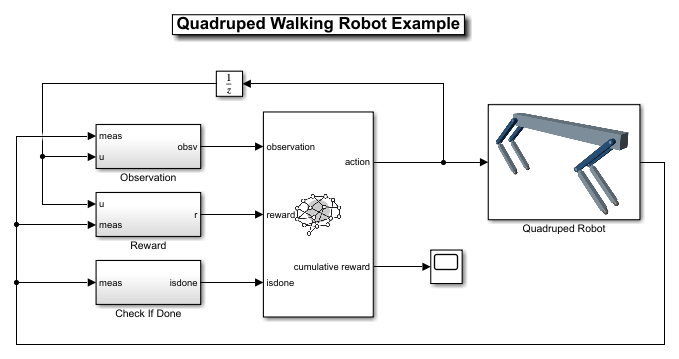
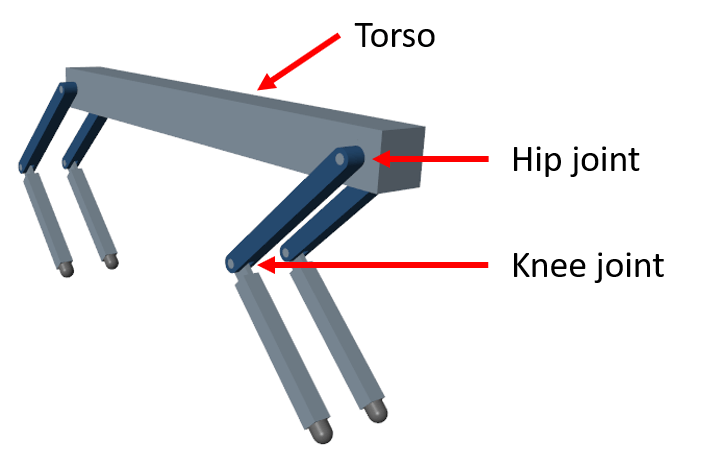
The robot is modeled using Simscape™ Multibody™ with its main structural components consisting of four legs and a torso. The legs are connected to the torso through revolute joints that enable rotation of the legs with respect to the torso. The joints are actuated by torque signals provided by the RL Agent.
Observations
The robot environment provides 44 observations to the agent, each normalized between –1 and 1. These observations are:
Y (vertical) and Y (lateral) position of the torso center of mass
Quaternion representing the orientation of the torso
X (forward), Y (vertical), and Z (lateral) velocities of the torso at the center of mass
Roll, pitch, and yaw rates of the torso
Angular positions and velocities of the hip and knee joints for each leg
Normal and friction force due to ground contact for each leg
Action values (torque for each joint) from the previous time step
For all four legs, the initial values for the hip and knee joint angles are set to –0.8234 and 1.6468 radians, respectively. The neutral positions of the joints are set at 0 radian. The legs are in neutral position when they are stretched to their maximum and are aligned perpendicularly to the ground.
Actions
The agent generates eight actions normalized between –1 and 1. After multiplying with a scaling factor, these correspond to the eight joint torque signals for the revolute joints. The overall joint torque bounds are +/– 10 N·m for each joint.
Reward
The following reward is provided to the agent at each time step during training. This reward function encourages the agent to move forward by providing a positive reward for positive forward velocity. It also encourages the agent to avoid early termination by providing a constant reward () at each time step. The remaining terms in the reward function are penalties that discourage unwanted states, such as large deviations from the desired height and orientation or the use of excessive joint torques.
where
is the velocity of the torso's center of mass in the x-direction.
and are the sample time and final simulation time of the environment, respectively.
is the scaled height error of the torso's center of mass from the desired height of 0.75 m.
is the pitch angle of the torso.
is the action value for joint from the previous time step.
Episode Termination
During training or simulation, the episode terminates if any of the following situations occur.
The height of the torso center of mass from the ground is below 0.5 m (fallen).
The head or tail of the torso is below the ground.
Any knee joint is below the ground.
Roll, pitch, or yaw angles are outside bounds (+/– 0.1745, +/– 0.1745, and +/– 0.3491 radians, respectively).
Create Environment Object
Specify the parameters for the observation set.
numObs = 44;
obsInfo = rlNumericSpec([numObs 1]);
obsInfo.Name = "observations";Specify the parameters for the action set.
numAct = 8;
actInfo = rlNumericSpec([numAct 1],LowerLimit=-1,UpperLimit=1);
actInfo.Name = "torque";Create the environment using the reinforcement learning model.
blk = mdl + "/RL Agent";
env = rlSimulinkEnv(mdl,blk,obsInfo,actInfo);During training, the function quadrupedResetFcn provided at the end of the example introduces random deviations into the initial joint angles and angular velocities.
env.ResetFcn = @quadrupedResetFcn;
Create DDPG Agent Object
DDPG agents use a parameterized Q-value function approximator as a critic, to estimate the value of the policy. They also use a parameterized deterministic policy over continuous action spaces, which is learned by a continuous deterministic actor.
For more information on creating a deep neural network value function, see Create Actors, Critics, and Policy Objects. For an example that creates neural networks for DDPG agents, see Compare DDPG Agent to LQR Controller.
First specify the following options for training the agent. For more information, see rlDDPGAgentOptions.
Specify a capacity of 1e6 for the experience buffer to store a diverse set of experiences.
Specify the
MaxMiniBatchPerEpochvalue to perform a maximum of 200 gradient step updates for each learning iteration.Specify a mini-batch size of 256 for learning. Smaller mini-batches are computationally efficient but might introduce variance in training. Contrarily, larger batch sizes can make the training stable but require higher memory.
Specify a learning rate of 1e-3 for the agent's actor and critic optimizer algorithms. A large learning rate causes drastic updates which might lead to divergent behaviors, while a low value might require many updates before reaching the optimal point.
Specify a gradient threshold value of 1.0 to clip the computed gradients to enhance the stability of the learning algorithm.
Specify a standard deviation of 0.1 and mean attraction coefficient of 1.0 to improve exploration of the agent's action space.
Specify a sample time Ts=0.025s.
% create the agent options object agentOptions = rlDDPGAgentOptions(); % specify the options agentOptions.SampleTime = Ts; agentOptions.MiniBatchSize = 256; agentOptions.ExperienceBufferLength = 1e6; agentOptions.MaxMiniBatchPerEpoch = 200; % optimizer options agentOptions.ActorOptimizerOptions.LearnRate = 1e-3; agentOptions.ActorOptimizerOptions.GradientThreshold = 1; agentOptions.CriticOptimizerOptions.LearnRate = 1e-3; agentOptions.CriticOptimizerOptions.GradientThreshold = 1; % exploration options agentOptions.NoiseOptions.StandardDeviation = 0.1; agentOptions.NoiseOptions.MeanAttractionConstant = 1.0;
When you create the agent, the initial parameters of the actor and critic networks are initialized with random values. Fix the random number stream so that the agent is always initialized with the same parameter values.
rng(0,"twister");Create the rlDDPGAgent object for the agent with 256 hidden units per layer.
initOpts = rlAgentInitializationOptions(NumHiddenUnit=256); agent = rlDDPGAgent(obsInfo,actInfo,initOpts,agentOptions);
Specify Training Options
To train the agent, first specify the following training options:
Run each training episode for a maximum of 10,000 episodes, with each episode lasting a maximum of
maxStepstime steps.Display the training progress in the Reinforcement Learning Training Monitor dialog box (set the
Plotsoption).Stop the training when the greedy policy evaluation exceeds 300.
trainOpts = rlTrainingOptions( ... MaxEpisodes=10000, ... MaxStepsPerEpisode=floor(Tf/Ts), ... ScoreAveragingWindowLength=250, ... Plots="training-progress", ... StopTrainingCriteria="EvaluationStatistic", ... StopTrainingValue=300);
To train the agent in parallel, specify the following training options. Training in parallel requires Parallel Computing Toolbox™ software. If you do not have Parallel Computing Toolbox™ software installed, set UseParallel to false.
Set the
UseParalleloption to true.Train the agent using asynchronous parallel workers.
trainOpts.UseParallel =true; trainOpts.ParallelizationOptions.Mode =
"async";
For more information, see rlTrainingOptions.
In parallel training, workers simulate the agent's policy with the environment and store experiences in the replay memory. When workers operate asynchronously the order of stored experiences might not be deterministic and can ultimately make the training results different. To maximize the reproducibility likelihood:
Initialize the parallel pool with the same number of parallel workers every time you run the code. For information on specifying the pool size see Discover Clusters and Use Cluster Profiles (Parallel Computing Toolbox).
Use synchronous parallel training by setting
trainOpts.ParallelizationOptions.Modeto"sync".Assign a random seed to each parallel worker using
trainOpts.ParallelizationOptions.WorkerRandomSeeds. The default value of -1 assigns a unique random seed to each parallel worker.
Train Agent
Fix the random stream for reproducibility.
rng(0,"twister");Train the agent using the train function. Due to the complexity of the robot model, this process is computationally intensive and takes several hours to complete. To save time while running this example, load a pretrained agent by setting doTraining to false. To train the agent yourself, set doTraining to true.
doTraining =false; if doTraining % Evaluate the greedy policy performance by taking the cumulative % reward mean over 5 simulations every 25 training episodes. evaluator = rlEvaluator(NumEpisodes=5, EvaluationFrequency=25); % Train the agent. result = train(agent, env, trainOpts, Evaluator=evaluator); else % Load pretrained agent parameters for the example. load("rlQuadrupedAgentParams.mat","params") setLearnableParameters(agent, params); end

Simulate Trained Agent
Fix the random stream for reproducibility.
rng(0,"twister");To validate the performance of the trained agent, simulate it within the robot environment. For more information on agent simulation, see rlSimulationOptions and sim.
simOptions = rlSimulationOptions(MaxSteps=floor(Tf/Ts)); experience = sim(env,agent,simOptions);

Restore the random number stream using the information stored in previousRngState.
rng(previousRngState);
Reset Function
The sim function calls the reset function at the start of each simulation episode, and the train function calls it at the start of each training episode. The reset function takes as input, and returns as output, a Simulink.SimulationInput (Simulink) object. The output object specifies temporary changes applied to model, which are then discarded when the simulation or training completes. For this example, the reset function uses the setVariable (Simulink) function to specify values in the model workspace. For more information, see Reset Function for Simulink Environments.
function in = quadrupedResetFcn(in) % Randomize initial conditions. l1 = evalin('base','l1'); l2 = evalin('base','l2'); max_foot_disp_x = 0.1; min_body_height = 0.7; max_body_height = 0.8; max_speed_x = 0.05; max_speed_y = 0.025; if rand < 0.5 % Start from random initial conditions % Randomize height b = min_body_height + (max_body_height - min_body_height) * rand; % Randomize x-displacement of foot from hip joint a = -max_foot_disp_x + 2 * max_foot_disp_x * rand(1,4); % Calculate joint angles d2r = pi/180; th_FL = d2r * quadrupedInverseKinematics(a(1),-b,l1,l2); th_FR = d2r * quadrupedInverseKinematics(a(2),-b,l1,l2); th_RL = d2r * quadrupedInverseKinematics(a(3),-b,l1,l2); th_RR = d2r * quadrupedInverseKinematics(a(4),-b,l1,l2); % Adjust for foot height foot_height = ... 0.05*l2*(1-sin(2*pi-(3*pi/2+sum([th_FL;th_FR;th_RL;th_RR],2)))); y_body = max(b) + max(foot_height); % Randomize body velocities vx = 2 * max_speed_x * (rand-0.5); vy = 2 * max_speed_y * (rand-0.5); else % Start from fixed initial conditions y_body = 0.7588; th_FL = [-0.8234 1.6468]; th_FR = th_FL; th_RL = th_FL; th_RR = th_FL; vx = 0; vy = 0; end in = setVariable(in,'y_init',y_body); in = setVariable(in,'init_ang_FL',th_FL); in = setVariable(in,'init_ang_FR',th_FR); in = setVariable(in,'init_ang_RL',th_RL); in = setVariable(in,'init_ang_RR',th_RR); in = setVariable(in,'vx_init',vx); in = setVariable(in,'vy_init',vy); end
References
[1] Heess, Nicolas, Dhruva TB, Srinivasan Sriram, Jay Lemmon, Josh Merel, Greg Wayne, Yuval Tassa, et al. ‘Emergence of Locomotion Behaviours in Rich Environments’. ArXiv:1707.02286 [Cs], 10 July 2017. https://arxiv.org/abs/1707.02286.
See Also
Functions
train|sim|rlSimulinkEnv
Objects
rlDDPGAgent|rlDDPGAgentOptions|rlQValueFunction|rlContinuousDeterministicActor|rlTrainingOptions|rlSimulationOptions|rlOptimizerOptions