estimate
Fit univariate ARIMA or ARIMAX model to data
Syntax
Description
EstMdl = estimate(Mdl,y)EstMdl. This model stores the
estimated parameter values resulting from fitting the partially specified ARIMA model
Mdl to the observed univariate time series y by
using maximum likelihood. EstMdl and Mdl are the
same model type and have the same structure.
[
also returns the estimated variance-covariance matrix associated with estimated parameters EstMdl,EstParamCov,logL,info] = estimate(___)EstParamCov, the optimized loglikelihood objective function logL, and a data structure of summary information info.
EstMdl = estimate(Mdl,Tbl1)Mdl to the response variable
in the input table or timetable Tbl1, which contains time series
data, and returns the fully specified, estimated ARIMA model EstMdl.
estimate selects the response variable named in
Mdl.SeriesName or the sole variable in Tbl1. To
select a different response variable in Tbl1 to fit the model to, use
the ResponseVariable name-value argument. (since R2023b)
[___] = estimate(___,
specifies options using one or more name-value arguments in
addition to any of the input argument combinations in previous syntaxes.
Name=Value)estimate returns the output argument combination for the
corresponding input arguments. For example, estimate(Mdl,y,Y0=y0,X=Pred) fits the ARIMA
model Mdl to the vector of response data y,
specifies the vector of presample response data y0, and includes a
linear regression term in the model for the exogenous predictor data
Pred.
Supply all input data using the same data type. Specifically:
If you specify the numeric vector
y, optional data sets must be numeric arrays and you must use the appropriate name-value argument. For example, to specify a presample, set theY0name-value argument to a numeric matrix of presample data.If you specify the table or timetable
Tbl1, optional data sets must be tables or timetables, respectively, and you must use the appropriate name-value argument. For example, to specify a presample, set thePresamplename-value argument to a table or timetable of presample data.
Examples
Fit an ARMA(2,1) model to simulated data.
Simulate Data from Known Model
Suppose that the data generating process (DGP) is
where is a series of iid Gaussian random variables with mean 0 and variance 0.1.
Create the ARMA(2,1) model representing the DGP.
DGP = arima(AR={0.5,-0.3},MA=0.2,Constant=0, ...
Variance=0.1)DGP =
arima with properties:
Description: "ARIMA(2,0,1) Model (Gaussian Distribution)"
SeriesName: "Y"
Distribution: Name = "Gaussian"
P: 2
D: 0
Q: 1
Constant: 0
AR: {0.5 -0.3} at lags [1 2]
SAR: {}
MA: {0.2} at lag [1]
SMA: {}
Seasonality: 0
Beta: [1×0]
Variance: 0.1
DGP is a fully specified arima model object.
Simulate a random 500 observation path from the ARMA(2,1) model.
rng(5,"twister"); % For reproducibility T = 500; y = simulate(DGP,T);
y is a 500-by-1 column vector representing a simulated response path from the ARMA(2,1) model DGP.
Estimate Model
Create an ARMA(2,1) model template for estimation.
Mdl = arima(2,0,1)
Mdl =
arima with properties:
Description: "ARIMA(2,0,1) Model (Gaussian Distribution)"
SeriesName: "Y"
Distribution: Name = "Gaussian"
P: 2
D: 0
Q: 1
Constant: NaN
AR: {NaN NaN} at lags [1 2]
SAR: {}
MA: {NaN} at lag [1]
SMA: {}
Seasonality: 0
Beta: [1×0]
Variance: NaN
Mdl is a partially specified arima model object. Only required, nonestimable parameters that determine the model structure are specified. NaN-valued properties, including , , , , and , are unknown model parameters to be estimated.
Fit the ARMA(2,1) model to y.
EstMdl = estimate(Mdl,y)
ARIMA(2,0,1) Model (Gaussian Distribution):
Value StandardError TStatistic PValue
_________ _____________ __________ __________
Constant 0.0089018 0.018417 0.48334 0.62886
AR{1} 0.49563 0.10323 4.8013 1.5767e-06
AR{2} -0.25495 0.070155 -3.6341 0.00027897
MA{1} 0.27737 0.10732 2.5846 0.0097491
Variance 0.10004 0.0066577 15.027 4.9017e-51
EstMdl =
arima with properties:
Description: "ARIMA(2,0,1) Model (Gaussian Distribution)"
SeriesName: "Y"
Distribution: Name = "Gaussian"
P: 2
D: 0
Q: 1
Constant: 0.00890178
AR: {0.495632 -0.254951} at lags [1 2]
SAR: {}
MA: {0.27737} at lag [1]
SMA: {}
Seasonality: 0
Beta: [1×0]
Variance: 0.100043
MATLAB® displays a table containing an estimation summary, which includes parameter estimates and inferences. For example, the Value column contains corresponding maximum-likelihood estimates, and the PValue column contains -values for the asymptotic -test of the null hypothesis that the corresponding parameter is 0.
EstMdl is a fully specified, estimated arima model object; its estimates resemble the parameter values of the DGP.
Fit an AR(2) model to simulated data while holding the model constant fixed during estimation.
Simulate Data from Known Model
Suppose the DGP is
where is a series of iid Gaussian random variables with mean 0 and variance 0.1.
Create the AR(2) model representing the DGP.
DGP = arima(AR={0.5,-0.3},Constant=0,Variance=0.1);Simulate a random 500 observation path from the model.
rng(5,"twister"); % For reproducibility T = 500; y = simulate(DGP,T);
Create Model Object Specifying Constraint
Assume that the mean of is 0, which implies that is 0.
Create an AR(2) model for estimation. Set to 0.
Mdl = arima(ARLags=1:2,Constant=0)
Mdl =
arima with properties:
Description: "ARIMA(2,0,0) Model (Gaussian Distribution)"
SeriesName: "Y"
Distribution: Name = "Gaussian"
P: 2
D: 0
Q: 0
Constant: 0
AR: {NaN NaN} at lags [1 2]
SAR: {}
MA: {}
SMA: {}
Seasonality: 0
Beta: [1×0]
Variance: NaN
Mdl is a partially specified arima model object. Specified parameters include all required parameters and the model constant. NaN-valued properties, including , , and , are unknown model parameters to be estimated.
Estimate Model
Fit the AR(2) model template containing the constraint to y.
EstMdl = estimate(Mdl,y)
ARIMA(2,0,0) Model (Gaussian Distribution):
Value StandardError TStatistic PValue
________ _____________ __________ __________
Constant 0 0 NaN NaN
AR{1} 0.56342 0.044225 12.74 3.5474e-37
AR{2} -0.29355 0.041786 -7.0252 2.137e-12
Variance 0.10022 0.006644 15.085 2.0476e-51
EstMdl =
arima with properties:
Description: "ARIMA(2,0,0) Model (Gaussian Distribution)"
SeriesName: "Y"
Distribution: Name = "Gaussian"
P: 2
D: 0
Q: 0
Constant: 0
AR: {0.563425 -0.293554} at lags [1 2]
SAR: {}
MA: {}
SMA: {}
Seasonality: 0
Beta: [1×0]
Variance: 0.100222
EstMdl is a fully specified, estimated arima model object; its estimates resemble the parameter values of the AR(2) model DGP. The value of in the estimation summary and object display is 0, and corresponding inferences are trivial or do not apply.
Load the US equity index data set Data_EquityIdx.
load Data_EquityIdxThe table DataTable includes the time series variable NYSE, which contains daily NYSE composite closing prices from January 1990 through December 2001.
Convert the table to a timetable.
dt = datetime(dates,'ConvertFrom','datenum','Format','yyyy-MM-dd'); TT = table2timetable(DataTable,'RowTimes',dt);
Suppose that an ARIMA(1,1,1) model is appropriate to model NYSE composite series during the sample period
Fit an ARIMA(1,1,1) model to the data, and return the estimated parameter covariance matrix.
Mdl = arima(1,1,1);
[EstMdl,EstParamCov] = estimate(Mdl,TT{:,"NYSE"});
ARIMA(1,1,1) Model (Gaussian Distribution):
Value StandardError TStatistic PValue
________ _____________ __________ ________
Constant 0.15745 0.097831 1.6094 0.10753
AR{1} -0.21995 0.15642 -1.4062 0.15966
MA{1} 0.2854 0.15382 1.8554 0.063537
Variance 17.159 0.20038 85.632 0
EstParamCov
EstParamCov = 4×4
0.0096 -0.0002 0.0002 0.0023
-0.0002 0.0245 -0.0240 -0.0060
0.0002 -0.0240 0.0237 0.0057
0.0023 -0.0060 0.0057 0.0402
EstMdl is a fully specified, estimated arima model object. Rows and columns of EstParamCov correspond to the rows in the table of estimates and inferences; for example, .
Compute estimated parameter standard errors by taking the square root of the diagonal elements of the covariance matrix.
estParamSE = sqrt(diag(EstParamCov))
estParamSE = 4×1
0.0978
0.1564
0.1538
0.2004
Compute a Wald-based 95% confidence interval on .
T = size(TT,1); % Effective sample size
phihat = EstMdl.AR{1};
sephihat = estParamSE(2);
ciphi = phihat + tinv([0.025 0.975],T - 3)*sephihatciphi = 1×2
-0.5266 0.0867
The interval contains 0, which suggests that is insignificant.
Since R2023b
Fit an ARIMA(1,1,1) model to the weekly average NYSE closing prices. Supply a timetable of data and specify the series for the fit.
Load Data
Load the US equity index data set Data_EquityIdx.
load Data_EquityIdx
T = height(DataTimeTable)T = 3028
The timetable DataTimeTable includes the time series variable NYSE, which contains daily NYSE composite closing prices from January 1990 through December 2001.
Plot the daily NYSE price series.
figure
plot(DataTimeTable.Time,DataTimeTable.NYSE)
title("NYSE Daily Closing Prices: 1990 - 2001")
Prepare Timetable for Estimation
When you plan to supply a timetable, you must ensure it has all the following characteristics:
The selected response variable is numeric and does not contain any missing values.
The timestamps in the
Timevariable are regular, and they are ascending or descending.
Create a new timetable, DTT, by removing all missing values from the timetable, relative to the NYSE price series.
DTT = rmmissing(DataTimeTable,DataVariables="NYSE");
T_DTT = height(DTT)T_DTT = 3028
Because all sample times have observed NYSE prices, rmmissing does not remove any observations.
Determine whether the sampling timestamps have a regular frequency and are sorted.
areTimestampsRegular = isregular(DTT,"days")areTimestampsRegular = logical
0
areTimestampsSorted = issorted(DTT.Time)
areTimestampsSorted = logical
1
areTimestampsRegular = 0 indicates that the timestamps of DTT are irregular, and areTimestampsSorted = 1 indicates that the timestamps are sorted. These measurements are irregular because observations occur only on business days.
Remedy the time irregularity by computing the weekly average closing price series of all timetable variables.
DTTW = convert2weekly(DTT,Aggregation="mean"); areTimestampsRegular = isregular(DTTW,"weeks")
areTimestampsRegular = logical
1
T_DTTW = height(DTTW)
T_DTTW = 627
The timetable DTTW is regular.
figure
plot(DTTW.Time,DTTW.NYSE)
title("NYSE Daily Closing Prices: 1990 - 2001")
Create Model Template for Estimation
Create an ARIMA(1,1,1) model template for estimation.
Mdl = arima(1,1,1)
Mdl =
arima with properties:
Description: "ARIMA(1,1,1) Model (Gaussian Distribution)"
SeriesName: "Y"
Distribution: Name = "Gaussian"
P: 2
D: 1
Q: 1
Constant: NaN
AR: {NaN} at lag [1]
SAR: {}
MA: {NaN} at lag [1]
SMA: {}
Seasonality: 0
Beta: [1×0]
Variance: NaN
Mdl is a partially specified arima model object.
Fit Model to Data
Fit an ARIMA(1,1,1) model to weekly average NYSE closing prices. Specify the entire series and the response variable name.
EstMdl = estimate(Mdl,DTTW,ResponseVariable="NYSE");
ARIMA(1,1,1) Model (Gaussian Distribution):
Value StandardError TStatistic PValue
________ _____________ __________ ___________
Constant 0.86385 0.46496 1.8579 0.063181
AR{1} -0.37582 0.22719 -1.6542 0.09809
MA{1} 0.47221 0.21741 2.172 0.029859
Variance 55.89 1.832 30.507 2.1201e-204
EstMdl is a fully specified, estimated arima model object. By default, estimate backcasts for the required Mdl.P = 2 presample responses.
Since R2023b
Because an ARIMA model is a function of previous values, estimate requires presample data to initialize the model early in the sampling period. Although estimate backcasts for presample data by default, you can specify required presample data instead. The P property of an arima model object specifies the required number of presample observations.
Fit an ARIMA(1,1,1) model to the weekly average NYSE closing prices. Supply timetables of presample and estimation data sets.
Load Data
Load the US equity index data set Data_EquityIdx.
load Data_EquityIdxPrepare Timetable for Estimation
The daily price series are irregular because observations occur only on business days. Remedy the time irregularity by computing the weekly average closing price series of all timetable variables.
DTTW = convert2weekly(DataTimeTable,Aggregation="mean");Create Model Template for Estimation
Create an ARIMA(1,1,1) model template for estimation.
Mdl = arima(1,1,1)
Mdl =
arima with properties:
Description: "ARIMA(1,1,1) Model (Gaussian Distribution)"
SeriesName: "Y"
Distribution: Name = "Gaussian"
P: 2
D: 1
Q: 1
Constant: NaN
AR: {NaN} at lag [1]
SAR: {}
MA: {NaN} at lag [1]
SMA: {}
Seasonality: 0
Beta: [1×0]
Variance: NaN
Mdl.P is 2. Therefore, estimate requires 2 presample observations to initialize the model for estimation.
Partition Sample
Partition the entire sample DTTW into presample and estimation sample timetables. The presample occurs first and contains two observations, and the estimation sample contains the remaining observations in DTTW.
PS = DTTW(1:Mdl.P,:); ES = DTTW((Mdl.P+1):end,:);
Estimate Model
Fit an ARIMA(1,1,1) model to the estimation sample. Specify the presample sample and response variable names.
EstMdl = estimate(Mdl,ES,ResponseVariable="NYSE", ... Presample=PS,PresampleResponseVariable="NYSE");
ARIMA(1,1,1) Model (Gaussian Distribution):
Value StandardError TStatistic PValue
________ _____________ __________ ___________
Constant 0.83623 0.453 1.846 0.064892
AR{1} -0.32862 0.23526 -1.3968 0.16247
MA{1} 0.42703 0.22613 1.8884 0.058967
Variance 56.065 1.8433 30.416 3.3798e-203
Since R2023b
Fit an ARIMA(1,1,1) model to the weekly average NYSE closing prices. Specify initial parameter values obtained from an analysis of a pilot sample.
Load Data
Load the US equity index data set Data_EquityIdx.
load Data_EquityIdxPrepare Timetable for Estimation
The daily price series are irregular because observations occur only on business days. Remedy the time irregularity by computing the weekly average closing price series of all timetable variables.
DTTW = convert2weekly(DataTimeTable,Aggregation="mean");Create Model Template for Estimation
Create an ARIMA(1,1,1) model template for estimation. Specify the response series name as NYSE.
Mdl = arima(ARLags=1,D=1,MALags=1,SeriesName="NYSE");Fit Model to Pilot Sample
Treat the first two years as a pilot sample for obtaining initial parameter values when fitting the model to the remaining three years of data. Fit the model to the pilot sample. By default, estimate uses the response data in the table variable that matches Mdl.SeriesName.
endPilot = datetime(1991,12,31);
DTTW0 = DTTW(DTTW.Time <= endPilot,:);
EstMdl0 = estimate(Mdl,DTTW0,Display="off");EstMdl0 is a fully specified, estimated arima model object.
Estimate Model
Fit an ARIMA(1,1,1) model to the estimation sample. Specify the estimated parameters from the pilot sample fit as initial values for optimization.
DTTWEst = DTTW(DTTW.Time > endPilot,:);
c0 = EstMdl0.Constant;
ar0 = EstMdl0.AR;
ma0 = EstMdl0.MA;
var0 = EstMdl0.Variance;
EstMdl = estimate(Mdl,DTTWEst,Constant0=c0,AR0=ar0, ...
MA0=ma0,Variance0=var0);
ARIMA(1,1,1) Model (Gaussian Distribution):
Value StandardError TStatistic PValue
________ _____________ __________ ___________
Constant 0.93923 0.55503 1.6922 0.090609
AR{1} -0.38996 0.26259 -1.4851 0.13753
MA{1} 0.48477 0.25108 1.9308 0.053514
Variance 64.661 2.4853 26.018 3.1307e-149
Fit an ARIMAX model to simulated time series data.
Simulate Predictor and Response Data
Create the ARIMAX(2,1,0) model for the DGP, represented by in the equation
where is a series of iid Gaussian random variables with mean 0 and variance 0.1.
DGP = arima(AR={0.5,-0.3},D=1,Constant=2, ...
Variance=0.1,Beta=[1.5 2.6 -0.3]);Assume that the exogenous variables , , and are represented by the AR(1) processes
where follows a Gaussian distribution with mean 0 and variance 0.01 for . Create ARIMA models that represent the exogenous variables.
MdlX1 = arima(AR=0.1,Constant=0,Variance=0.01); MdlX2 = arima(AR=0.2,Constant=0,Variance=0.01); MdlX3 = arima(AR=0.3,Constant=0,Variance=0.01);
Simulate length 1000 exogenous series from the AR models. Store the simulated data in a matrix.
T = 1000; rng(10,"twister"); % For reproducibility x1 = simulate(MdlX1,T); x2 = simulate(MdlX2,T); x3 = simulate(MdlX3,T); X = [x1 x2 x3];
X is a 1000-by-3 matrix of simulated time series data. Each row corresponds to an observation in the time series, and each column corresponds to an exogenous variable.
Simulate a length 1000 series from the DGP. Specify the simulated exogenous data.
y = simulate(DGP,T,X=X);
y is a 1000-by-1 vector of response data.
Estimate Model
Create an ARIMA(2,1,0) model template for estimation.
Mdl = arima(2,1,0)
Mdl =
arima with properties:
Description: "ARIMA(2,1,0) Model (Gaussian Distribution)"
SeriesName: "Y"
Distribution: Name = "Gaussian"
P: 3
D: 1
Q: 0
Constant: NaN
AR: {NaN NaN} at lags [1 2]
SAR: {}
MA: {}
SMA: {}
Seasonality: 0
Beta: [1×0]
Variance: NaN
The model description (Description property) and value of Beta suggest that the partially specified arima model object Mdl is agnostic of the exogenous predictors.
Estimate the ARIMAX(2,1,0) model; specify the exogenous predictor data. Because estimate backcasts for presample responses (a process that requires presample predictor data for ARIMAX models), fit the model to the latest T – Mdl.P responses. (Alternatively, you can specify presample responses by using the Y0 name-value argument.)
EstMdl = estimate(Mdl,y((Mdl.P + 1):T),X=X);
ARIMAX(2,1,0) Model (Gaussian Distribution):
Value StandardError TStatistic PValue
________ _____________ __________ ___________
Constant 1.7519 0.021143 82.859 0
AR{1} 0.56076 0.016511 33.963 7.931e-253
AR{2} -0.26625 0.015966 -16.676 1.9622e-62
Beta(1) 1.4764 0.10157 14.536 7.1227e-48
Beta(2) 2.5638 0.10445 24.547 4.6639e-133
Beta(3) -0.34422 0.098623 -3.4903 0.00048249
Variance 0.10673 0.0047273 22.577 7.3155e-113
EstMdl is a fully specified, estimated arima model object.
When you estimate the model by using estimate and supply the exogenous data by specifying the X name-value argument, MATLAB® recognizes the model as an ARIMAX(2,1,0) model and includes a linear regression component for the exogenous variables.
The estimated model is
which resembles the DGP represented by Mdl0. Because MATLAB returns the AR coefficients of the model expressed in difference-equation notation, their signs are opposite in the equation.
Since R2023b
Fit an ARIMA(1,1,1) model to the weekly average NYSE closing prices. Compute estimated weekly averages closing price within the time range of the data.
Load the US equity index data set Data_EquityIdx.
load Data_EquityIdxThe daily price series are irregular because observations occur only on business days. Remedy the time irregularity by computing the weekly average closing price series of all timetable variables.
DTTW = convert2weekly(DataTimeTable,Aggregation="mean");
numobs = height(DTTW)numobs = 627
Create an ARIMA(1,1,1) model template for estimation. Specify the response series name as NYSE.
Mdl = arima(1,1,1);
Mdl.SeriesName = "NYSE";Fit an ARIMA(1,1,1) model to the entire sample. Suppress the estimation display.
EstMdl = estimate(Mdl,DTTW,Display="off");Infer residuals from the estimated model.
ResidTT = infer(EstMdl,DTTW); tail(ResidTT)
Time NYSE NASDAQ NYSE_Residual NYSE_Variance
___________ ______ ______ _____________ _____________
16-Nov-2001 577.11 1886.9 5.8562 55.89
23-Nov-2001 583 1898.3 5.4409 55.89
30-Nov-2001 581.41 1925.8 -2.8105 55.89
07-Dec-2001 584.96 1998.1 3.4212 55.89
14-Dec-2001 574.03 1981 -12.071 55.89
21-Dec-2001 582.1 1967.9 8.7933 55.89
28-Dec-2001 590.28 1967.2 6.2015 55.89
04-Jan-2002 589.8 1950.4 -1.2004 55.89
ResidTT is a 627-by-4 timetable containing the data passed to esimtate from DTTW, and the residuals NYSE_Residual and estimated conditional variances NYSE_Variance from the fit. Because the model variance is a constant, the conditional variance variable contains a vector completely composed of 55.89, which is the model variance estimate.
Compute the fitted values and store them in ResidTT.
ResidTT.NYSE_YHat = ResidTT.NYSE - ResidTT.NYSE_Residual; tail(ResidTT)
Time NYSE NASDAQ NYSE_Residual NYSE_Variance NYSE_YHat
___________ ______ ______ _____________ _____________ _________
16-Nov-2001 577.11 1886.9 5.8562 55.89 571.25
23-Nov-2001 583 1898.3 5.4409 55.89 577.56
30-Nov-2001 581.41 1925.8 -2.8105 55.89 584.22
07-Dec-2001 584.96 1998.1 3.4212 55.89 581.54
14-Dec-2001 574.03 1981 -12.071 55.89 586.1
21-Dec-2001 582.1 1967.9 8.7933 55.89 573.3
28-Dec-2001 590.28 1967.2 6.2015 55.89 584.08
04-Jan-2002 589.8 1950.4 -1.2004 55.89 591
Plot the last 200 observations with corresponding fitted values on the same graph.
figure
h = plot(ResidTT.Time((end-199):end),ResidTT{(end-199):end,["NYSE" "NYSE_YHat"]});
h(2).LineStyle = "--";
legend(["Observations" "Fitted values"])
title("Model of NYSE Weekly Average Closing Prices")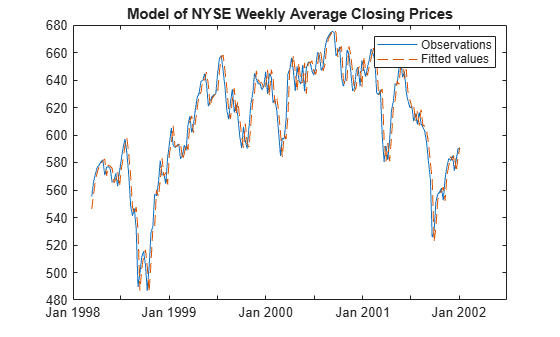
The fitted values closely track the observations.
Plot the residuals versus the fitted values.
figure plot(ResidTT.NYSE_YHat,ResidTT.NYSE_Residual,".",MarkerSize=15) ylabel("Residuals") xlabel("Fitted Values") title("Residual Plot")
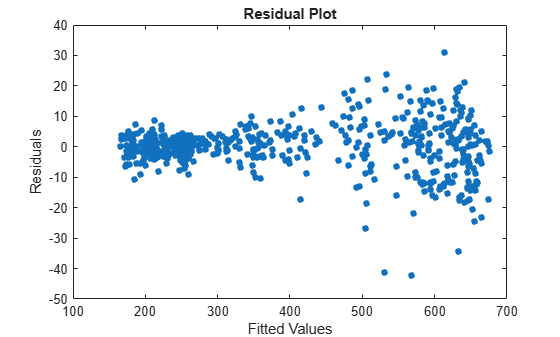
The residual variance appears larger for larger fitted values. One remedy for this behavior is to apply the log transform to the data.
Input Arguments
Name-Value Arguments
Output Arguments
Tips
Algorithms
estimateinfers innovations and conditional variances (when present) of the underlying response series, and then uses constrained maximum likelihood to fit the modelMdlto the response datay.Because you can specify numeric presample data inputs
Y0,E0, andV0of differing lengths,estimateassumes that all specified sets have these characteristics:The final observation (row) in each set occurs simultaneously.
The first observation in the estimation sample immediately follows the last observation in the presample, with respect to the sampling frequency.
If you specify the
Displayname-value argument, the value overrides theDiagnosticsandDisplaysettings of theOptionsname-value argument. Otherwise,estimatedisplays optimization information usingOptionssettings.estimateuses the outer product of gradients (OPG) method to perform covariance matrix estimation.If you supply data in the table or timetable
Tbl1to estimate an ARIMAX model,estimatecannot backcast for presample responses. Therefore, if you specifyPredictorVariables, you must also specify presample response data by using thePresampleandPresampleResponseVariablename-value arguments.
References
[1] Box, George E. P., Gwilym M. Jenkins, and Gregory C. Reinsel. Time Series Analysis: Forecasting and Control. 3rd ed. Englewood Cliffs, NJ: Prentice Hall, 1994.
[2] Enders, Walter. Applied Econometric Time Series. Hoboken, NJ: John Wiley & Sons, Inc., 1995.
[3] Greene, William. H. Econometric Analysis. 6th ed. Upper Saddle River, NJ: Prentice Hall, 2008.
[4] Hamilton, James D. Time Series Analysis. Princeton, NJ: Princeton University Press, 1994.
Version History
Introduced in R2012aSee Also
Objects
Functions
Topics
- Time Base Partitions for ARIMA Model Estimation
- Estimate Seasonal ARIMA (SARIMA) Model
- Estimate Conditional Mean and Variance Model
- Model Seasonal Lag Effects Using Indicator Variables
- Maximum Likelihood Estimation for Conditional Mean Models
- Conditional Mean Model Estimation with Equality Constraints
- Presample Data for Conditional Mean Model Estimation
- Initial Values for Conditional Mean Model Estimation
- Optimization Settings for Conditional Mean Model Estimation