Pruning
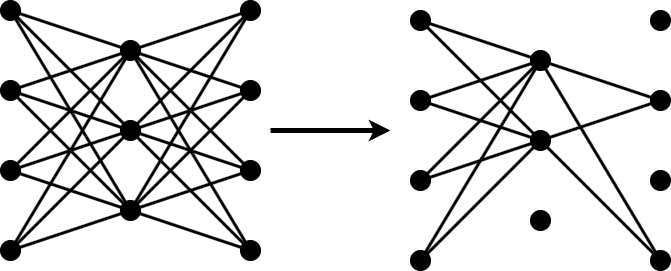
Pruning reduziert die Anzahl lernbarer Parameter in einem neuronalen Netz, indem die am wenigsten wichtigen Filter in Faltungsschichten entfernt werden.
Wenn Sie Ihr Netz mithilfe der Funktion trainnet trainieren können, führen Sie daraufhin über die Funktion compressNetworkUsingTaylorPruning ein Pruning Ihres Netzes durch. Wenn Sie Ihr Netz nicht mithilfe der Funktion trainnet trainieren können, erstellen Sie stattdessen eine benutzerdefinierte Pruning-Schleife mit einem taylorPrunableNetwork-Objekt.
Einen detaillierten Überblick über die in der Deep Learning Toolbox™ Model Compression Library verfügbaren Komprimierungstechniken finden Sie unter Reduce Memory Footprint of Deep Neural Networks.
Funktionen
Themen
- Prune Neural Network with Memory Requirement
This example shows how to compress a neural network to a specific size using Taylor pruning. (Seit R2026a)
- Prune Neural Network with Accuracy Requirement
This example shows how to compress a neural network with a minimum accuracy requirement using Taylor pruning. (Seit R2026a)
- Prune Image Classification Network Using Taylor Scores
Reduce the size of a deep neural network using Taylor pruning.
- Prune Filters in a Detection Network Using Taylor Scores
Reduce network size and increase inference speed by pruning convolutional filters in a you only look once (YOLO) v3 object detection network.
- Prune and Quantize Convolutional Neural Network for Speech Recognition
Compress a convolutional neural network (CNN) to prepare it for deployment on an embedded system.
- Parameter Pruning and Quantization of Image Classification Network
Use parameter pruning and quantization to reduce network size.
Enthaltene Beispiele
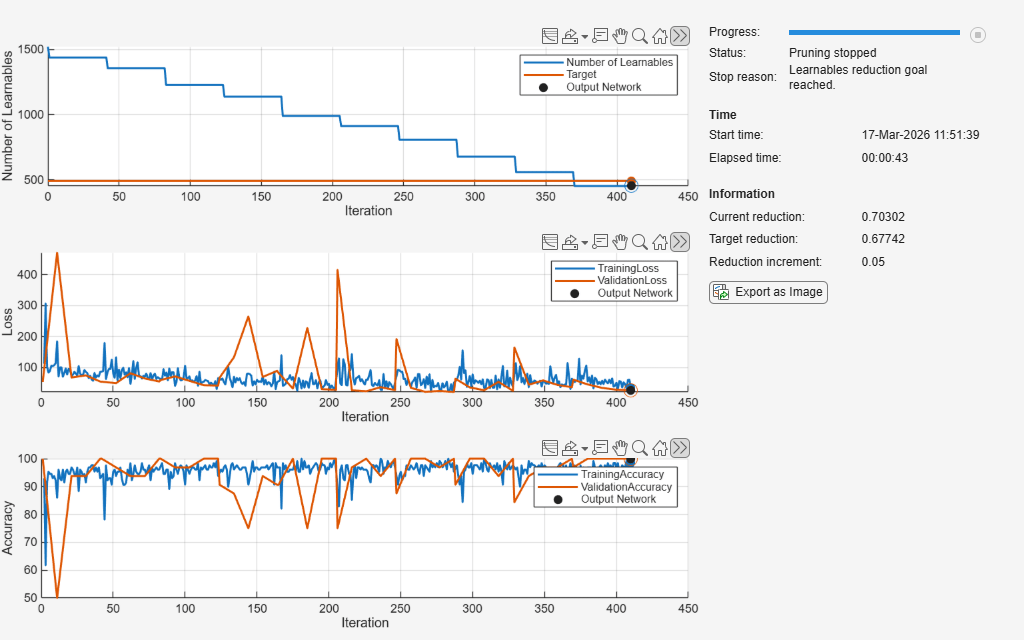
Prune Neural Network with Memory Requirement
Compress a neural network to a specific size using Taylor pruning.

Prune Neural Network with Accuracy Requirement
Compress a neural network with a minimum accuracy requirement using Taylor pruning.

Analyze and Compress 1-D Convolutional Neural Network
Analyze 1-D convolutional network for compression and compress it using Taylor pruning and projection.