Pruning, Projektion und Quantisierung
Verwenden Sie die Deep Learning Toolbox™ zusammen mit dem Supportpaket Deep Learning Toolbox Model Compression Library, um den Speicherbedarf und die Rechenanforderungen eines tiefen neuronalen Netzes zu reduzieren:
Führen Sie ein Pruning der Filter aus Faltungsschichten durch eine Taylor-Approximation erster Ordnung durch.
Projizieren Sie Schichten durch Durchführung einer Hauptkomponentenanalyse (PCA) auf die Schichtaktivierungen.
Quantisieren Sie die Gewichte, Verzerrungen und Aktivierungen von Schichten auf skalierte Ganzzahl-Datentypen mit reduzierter Genauigkeit.
Daraufhin können Sie aus dem komprimierten Netz Code generieren und auf der gewünschten Hardware bereitstellen.
Wichtige Links
Kategorien
- Leitfaden zum Einstieg in die Netzkomprimierung
Erlernen Sie die Grundlagen der Deep Learning Toolbox Model Compression Library
- Pruning
Reduzieren der Anzahl lernbarer Parameter in einem neuronalen Netz durch Pruning der am wenigsten wichtigen Filter in Faltungsschichten
- Projektion
Projizieren von Netzschichten mithilfe von Hauptkomponentenanalyse (PCA); Reduzieren der Anzahl lernbarer Parameter
- Quantisierung
Quantisieren von Netzparametern zu Datentypen mit reduzierter Präzision; Vorbereiten von Deep-Learning-Netzen für Festkomma-Codegenerierung
- Netz-Komprimierungsanwendungen
Erkunden Sie die Deep-Learning-Modellkomprimierung in End-to-End-Workflows
Enthaltene Beispiele

Analyze and Compress 1-D Convolutional Neural Network
Analyze 1-D convolutional network for compression and compress it using Taylor pruning and projection.

Compress Sequence Classification Network for Road Damage Detection
Compress network to meet memory requirement using pruning, projection, and quantization.
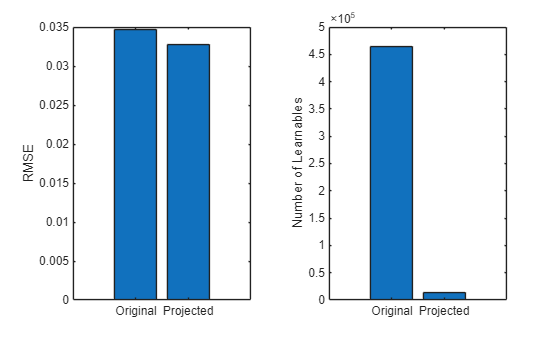
Compress Deep Learning Network for Battery State of Charge Estimation
Compress a neural network for predicting the state of charge of a battery using projection.