rangesearch
Find all neighbors within specified distance using input data
Description
Examples
Find the X points that are within a Euclidean distance 1.5 of each Y point. Both X and Y are samples of five-dimensional normally distributed variables.
rng('default') % For reproducibility X = randn(100,5); Y = randn(10,5); [Idx,D] = rangesearch(X,Y,1.5)
Idx=10×1 cell array
{[ 25 62 33 99 87 92 16]}
{[ 92 25]}
{[ 93 42 31 73 60 28 78 83 48 89 85]}
{[ 92 41]}
{[44 7 28 78 75 42 69 31 1 26 83 93]}
{[ 15 31 89 41 27 17 29 60 34]}
{[ 89]}
{1×0 double }
{1×0 double }
{1×0 double }
D=10×1 cell array
{[ 0.9546 1.0987 1.2730 1.3981 1.4140 1.4249 1.4822]}
{[ 1.4203 1.4558]}
{[ 0.7114 0.7552 1.0081 1.1324 1.1424 1.1637 1.2108 1.3824 1.3944 1.4116 1.4605]}
{[ 1.1244 1.4672]}
{[0.7863 0.9326 0.9773 1.0508 1.1722 1.1934 1.3218 1.3623 1.3869 1.3919 1.4814 1.4978]}
{[ 1.2824 1.2843 1.3342 1.3469 1.4154 1.4237 1.4625 1.4626 1.4744]}
{[ 1.1739]}
{1×0 double }
{1×0 double }
{1×0 double }
In this case, the last three Y points are more than 1.5 distance away from any X point. X(89,:) is 1.1739 distance away from Y(7,:), and no other X point is within distance 1.5 of Y(7,:). X contains 12 points within distance 1.5 of Y(5,:).
Generate 5000 random points from each of three distinct multivariate normal distributions. Shift the means of the distributions so that the randomly generated points are likely to form three separate clusters.
rng('default') % For reproducibility N = 5000; dist = 10; X = [mvnrnd([0 0],eye(2),N); mvnrnd(dist*[1 1],eye(2),N); mvnrnd(dist*[-1 -1],eye(2),N)];
For each point in X, find the points in X that are within a radius dist away from the point. For faster computation, specify to keep the indices of the nearest neighbors unsorted. Select the first point in X, and find its nearest neighbors.
Idx = rangesearch(X,X,dist,'SortIndices',false);
x = X(1,:);
nearestPoints = X(Idx{1},:);Find the values in X that are not the nearest neighbors of x. Display those points in one color and the nearest neighbors of x in a different color. Label the point x with a black, filled circle.
nonNearestIdx = true(size(X,1),1);
nonNearestIdx(Idx{1}) = false;
scatter(X(nonNearestIdx,1),X(nonNearestIdx,2))
hold on
scatter(nearestPoints(:,1),nearestPoints(:,2))
scatter(x(1),x(2),'black','filled')
hold off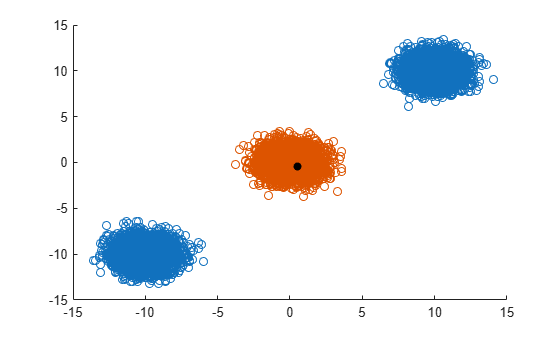
Find the patients in the patients data set that are within a certain age and weight range of the patients in Y.
Load the patients data set. The Age values are in years, and the Weight values are in pounds.
load patients X = [Age Weight]; Y = [20 162; 30 169; 40 168]; % New patients
Create a custom distance function distfun that determines the distance between patients in terms of age and weight. For example, according to distfun, two patients that are one year apart in age and have the same weight are one distance unit apart. Similarly, two patients that have the same age and are five pounds apart in weight are also one distance unit apart.
type distfun.m % Display contents of distfun.m file
function D2 = distfun(ZI,ZJ) ageDifference = abs(ZI(1)-ZJ(:,1)); weightDifference = abs(ZI(2)-ZJ(:,2)); D2 = ageDifference + 0.2*weightDifference; end
Note: If you click the button located in the upper-right section of this example and open the example in MATLAB®, then MATLAB opens the example folder. This folder includes the function file distfun.m.
Find the patients in X that are within the distance 2 of the patients in Y.
[Idx,D] = rangesearch(X,Y,2,'Distance',@distfun)Idx=3×1 cell array
{1×0 double}
{1×0 double}
{[ 41]}
D=3×1 cell array
{1×0 double}
{1×0 double}
{[ 1.8000]}
The third patient in Y is the only one to have a patient in X within a distance of 2.
Display the Age and Weight values for the nearest patient in X to the patient with age 40 and weight 168.
X(Idx{3},:)ans = 1×2
39 164
Input Arguments
Name-Value Arguments
Output Arguments
Tips
For a fixed positive real value
r,rangesearchfinds all theXpoints that are within a distancerof eachYpoint. To find the k points inXthat are nearest to eachYpoint, for a fixed positive integer k, useknnsearch.rangesearchdoes not save a search object. To create a search object, usecreatens.
Algorithms
For an overview of the kd-tree algorithm, see k-Nearest Neighbor Search Using a Kd-Tree.
The exhaustive search algorithm finds the distance from each point in
Xto each point inY.
Alternative Functionality
If you set the rangesearch function 'NSMethod'
name-value pair argument to the appropriate value ('exhaustive' for an
exhaustive search algorithm or 'kdtree' for a Kd-tree
algorithm), then the search results are equivalent to the results obtained by conducting a
distance search using the rangesearch object function. Unlike the
rangesearch function, the rangesearch object function requires an ExhaustiveSearcher or KDTreeSearcher model object.
Extended Capabilities
Version History
Introduced in R2011b