estimateMAP
Class: HamiltonianSampler
Estimate maximum of log probability density
Syntax
xhat = estimateMAP(smp)
[xhat,fitinfo]
= estimateMAP(smp)
[xhat,fitinfo]
= estimateMAP(___,Name,Value)
Description
xhat = estimateMAP(smp)smp.
[ returns additional
fitting information in xhat,fitinfo]
= estimateMAP(smp)fitinfo.
[ specifies
additional options using one or more name-value pair arguments. Specify
name-value pair arguments after all other input arguments.xhat,fitinfo]
= estimateMAP(___,Name,Value)
Input Arguments
Name-Value Arguments
Output Arguments
Examples
Create a Hamiltonian Monte Carlo sampler for a normal distribution and estimate the maximum-a-posteriori (MAP) point of the log probability density.
First, save a function normalDistGrad on the MATLAB® path that returns the multivariate normal log probability density and its gradient (normalDistGrad is defined at the end of this example). Then, call the function with arguments to define the logpdf input argument to the hmcSampler function.
means = [1;-1]; standevs = [1;0.3]; logpdf = @(theta)normalDistGrad(theta,means,standevs);
Choose a starting point and create the HMC sampler.
startpoint = zeros(2,1); smp = hmcSampler(logpdf,startpoint);
Estimate the MAP point (the point where the probability density has its maximum). Show more information during optimization by setting the 'VerbosityLevel' value to 1.
[xhat,fitinfo] = estimateMAP(smp,'VerbosityLevel',1); o Solver = LBFGS, HessianHistorySize = 15, LineSearchMethod = weakwolfe
|====================================================================================================|
| ITER | FUN VALUE | NORM GRAD | NORM STEP | CURV | GAMMA | ALPHA | ACCEPT |
|====================================================================================================|
| 0 | 6.689460e+00 | 1.111e+01 | 0.000e+00 | | 9.000e-03 | 0.000e+00 | YES |
| 1 | 4.671622e+00 | 8.889e+00 | 2.008e-01 | OK | 9.006e-02 | 2.000e+00 | YES |
| 2 | 9.759850e-01 | 8.268e-01 | 8.215e-01 | OK | 9.027e-02 | 1.000e+00 | YES |
| 3 | 9.158025e-01 | 7.496e-01 | 7.748e-02 | OK | 5.910e-01 | 1.000e+00 | YES |
| 4 | 6.339508e-01 | 3.104e-02 | 7.472e-01 | OK | 9.796e-01 | 1.000e+00 | YES |
| 5 | 6.339043e-01 | 3.668e-05 | 3.762e-03 | OK | 9.599e-02 | 1.000e+00 | YES |
| 6 | 6.339043e-01 | 2.488e-08 | 3.333e-06 | OK | 9.015e-02 | 1.000e+00 | YES |
Infinity norm of the final gradient = 2.488e-08
Two norm of the final step = 3.333e-06, TolX = 1.000e-06
Relative infinity norm of the final gradient = 2.488e-08, TolFun = 1.000e-06
EXIT: Local minimum found.
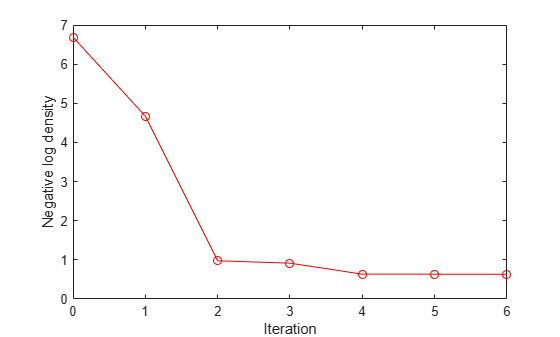
To further check that the optimization has converged to a local minimum, plot the fitinfo.Objective field. This field contains the values of the negative log density at each iteration of the function optimization. The final values are all very similar, so the optimization has converged.
fitinfo
fitinfo = struct with fields:
Iteration: [7×1 double]
Objective: [7×1 double]
Gradient: [2×1 double]
plot(fitinfo.Iteration,fitinfo.Objective,'ro-'); xlabel('Iteration'); ylabel('Negative log density');
Display the MAP estimate. It is indeed equal to the means variable, which is the exact maximum.
xhat
xhat = 2×1
1.0000
-1.0000
means
means = 2×1
1
-1
The normalDistGrad function returns the logarithm of the multivariate normal probability density with means in Mu and standard deviations in Sigma, specified as scalars or columns vectors the same length as startpoint. The second output argument is the corresponding gradient.
function [lpdf,glpdf] = normalDistGrad(X,Mu,Sigma) Z = (X - Mu)./Sigma; lpdf = sum(-log(Sigma) - .5*log(2*pi) - .5*(Z.^2)); glpdf = -Z./Sigma; end
Tips
First create a Hamiltonian Monte Carlo sampler using the
hmcSamplerfunction, and then useestimateMAPto estimate the MAP point.After creating an HMC sampler, you can tune the sampler, draw samples, and check convergence diagnostics using the other methods of the
HamiltonianSamplerclass. Using the MAP estimate as a starting point in thetuneSampleranddrawSamplesmethods can lead to more efficient tuning and sampling. For an example of this workflow, see Bayesian Linear Regression Using Hamiltonian Monte Carlo.
Algorithms
estimateMAPuses a limited memory Broyden-Fletcher-Goldfarb-Shanno (LBFGS) quasi-Newton optimizer to search for the maximum of the log probability density. See Nocedal and Wright [1].
References
[1] Nocedal, J. and S. J. Wright. Numerical Optimization, Second Edition. Springer Series in Operations Research, Springer Verlag, 2006.
Version History
Introduced in R2017a