knnsearch
Find k-nearest neighbors using searcher object
Description
Idx = knnsearch(Mdl,Y)Mdl.X to each point (i.e., row or observation) in the query
data Y using an exhaustive search, a Kd-tree,
or a Hierarchical Navigable Small Worlds approximate search.
knnsearch returns Idx, which is a column
vector of the indices in Mdl.X representing the nearest
neighbors.
Idx = knnsearch(Mdl,Y,Name,Value)Mdl.X to
Y with additional options specified by one or more
Name,Value pair arguments. For example, specify the number of
nearest neighbors to search for, or distance metric different from the one stored in
Mdl.Distance. You can also specify which action to take if
the closest distances are tied.
[ additionally returns the matrix
Idx,D]
= knnsearch(___)D using any of the input arguments in the previous syntaxes.
D contains the distances between each observation in
Y that correspond to the closest observations in
Mdl.X. By default, the function arranges the columns of
D in ascending order by closeness, with respect to the
distance metric.
Examples
knnsearch accepts ExhaustiveSearcher or KDTreeSearcher model objects to search the training data for the nearest neighbors to the query data. An ExhaustiveSearcher model invokes the exhaustive searcher algorithm, and a KDTreeSearcher model defines a Kd-tree, which knnsearch uses to search for nearest neighbors.
Load Fisher's iris data set. Randomly reserve five observations from the data for query data.
load fisheriris rng(1); % For reproducibility n = size(meas,1); idx = randsample(n,5); X = meas(~ismember(1:n,idx),:); % Training data Y = meas(idx,:); % Query data
The variable meas contains 4 predictors.
Grow a default four-dimensional Kd-tree.
MdlKDT = KDTreeSearcher(X)
MdlKDT =
KDTreeSearcher with properties:
BucketSize: 50
Distance: 'euclidean'
DistParameter: []
X: [145×4 double]
MdlKDT is a KDTreeSearcher model object. You can alter its writable properties using dot notation.
Prepare an exhaustive nearest neighbor searcher.
MdlES = ExhaustiveSearcher(X)
MdlES =
ExhaustiveSearcher with properties:
Distance: 'euclidean'
DistParameter: []
X: [145×4 double]
MdlKDT is an ExhaustiveSearcher model object. It contains the options, such as the distance metric, to use to find nearest neighbors.
Alternatively, you can grow a Kd-tree or prepare an exhaustive nearest neighbor searcher using createns.
Search the training data for the nearest neighbors indices that correspond to each query observation. Conduct both types of searches using the default settings. By default, the number of neighbors to search for per query observation is 1.
IdxKDT = knnsearch(MdlKDT,Y); IdxES = knnsearch(MdlES,Y); [IdxKDT IdxES]
ans = 5×2
17 17
6 6
1 1
89 89
124 124
In this case, the results of the search are the same.
Grow a Kd-tree nearest neighbor searcher object by using the createns function. Pass the object and query data to the knnsearch function to find k-nearest neighbors.
Load Fisher's iris data set.
load fisheririsRemove five irises randomly from the predictor data to use as a query set.
rng(1) % For reproducibility n = size(meas,1); % Sample size qIdx = randsample(n,5); % Indices of query data tIdx = ~ismember(1:n,qIdx); % Indices of training data Q = meas(qIdx,:); X = meas(tIdx,:);
Grow a four-dimensional Kd-tree using the training data. Specify the Minkowski distance for finding nearest neighbors.
Mdl = createns(X,'Distance','minkowski')
Mdl =
KDTreeSearcher with properties:
BucketSize: 50
Distance: 'minkowski'
DistParameter: 2
X: [145×4 double]
Because X has four columns and the distance metric is Minkowski, createns creates a KDTreeSearcher model object by default. The Minkowski distance exponent is 2 by default.
Find the indices of the training data (Mdl.X) that are the two nearest neighbors of each point in the query data (Q).
IdxNN = knnsearch(Mdl,Q,'K',2)IdxNN = 5×2
17 4
6 2
1 12
89 66
124 100
Each row of IdxNN corresponds to a query data observation, and the column order corresponds to the order of the nearest neighbors, with respect to ascending distance. For example, based on the Minkowski distance, the second nearest neighbor of Q(3,:) is X(12,:).
Load Fisher's iris data set.
load fisheririsRemove five irises randomly from the predictor data to use as a query set.
rng(4); % For reproducibility n = size(meas,1); % Sample size qIdx = randsample(n,5); % Indices of query data X = meas(~ismember(1:n,qIdx),:); Y = meas(qIdx,:);
Grow a four-dimensional Kd-tree using the training data. Specify the Minkowski distance for finding nearest neighbors.
Mdl = KDTreeSearcher(X);
Mdl is a KDTreeSearcher model object. By default, the distance metric for finding nearest neighbors is the Euclidean metric.
Find the indices of the training data (X) that are the seven nearest neighbors of each point in the query data (Y).
[Idx,D] = knnsearch(Mdl,Y,'K',7,'IncludeTies',true);
Idx and D are five-element cell arrays of vectors, with each vector having at least seven elements.
Display the lengths of the vectors in Idx.
cellfun('length',Idx)ans = 5×1
8
7
7
7
7
Because cell 1 contains a vector with length greater than k = 7, query observation 1 (Y(1,:)) is equally close to at least two observations in X.
Display the indices of the nearest neighbors to Y(1,:) and their distances.
nn5 = Idx{1}nn5 = 1×8
91 98 67 69 71 93 88 95
nn5d = D{1}nn5d = 1×8
0.1414 0.2646 0.2828 0.3000 0.3464 0.3742 0.3873 0.3873
Training observations 88 and 95 are 0.3873 cm away from query observation 1.
Train two KDTreeSearcher models using different distance metrics, and compare k-nearest neighbors of query data for the two models.
Load Fisher's iris data set. Consider the petal measurements as predictors.
load fisheriris X = meas(:,3:4); % Predictors Y = species; % Response
Train a KDTreeSearcher model object by using the predictors. Specify the Minkowski distance with exponent 5.
KDTreeMdl = KDTreeSearcher(X,'Distance','minkowski','P',5)
KDTreeMdl =
KDTreeSearcher with properties:
BucketSize: 50
Distance: 'minkowski'
DistParameter: 5
X: [150×2 double]
Find the 10 nearest neighbors from X to a query point (newpoint), first using Minkowski then Chebychev distance metrics. The query point must have the same column dimension as the data used to train the model.
newpoint = [5 1.45]; [IdxMk,DMk] = knnsearch(KDTreeMdl,newpoint,'k',10); [IdxCb,DCb] = knnsearch(KDTreeMdl,newpoint,'k',10,'Distance','chebychev');
IdxMk and IdxCb are 1-by-10 matrices containing the row indices of X corresponding to the nearest neighbors to newpoint using Minkowski and Chebychev distances, respectively. Element (1,1) is the nearest, element (1,2) is the next nearest, and so on.
Plot the training data, query point, and nearest neighbors.
figure; gscatter(X(:,1),X(:,2),Y); title('Fisher''s Iris Data -- Nearest Neighbors'); xlabel('Petal length (cm)'); ylabel('Petal width (cm)'); hold on plot(newpoint(1),newpoint(2),'kx','MarkerSize',10,'LineWidth',2); % Query point plot(X(IdxMk,1),X(IdxMk,2),'o','Color',[.5 .5 .5],'MarkerSize',10); % Minkowski nearest neighbors plot(X(IdxCb,1),X(IdxCb,2),'p','Color',[.5 .5 .5],'MarkerSize',10); % Chebychev nearest neighbors legend('setosa','versicolor','virginica','query point',... 'minkowski','chebychev','Location','Best');
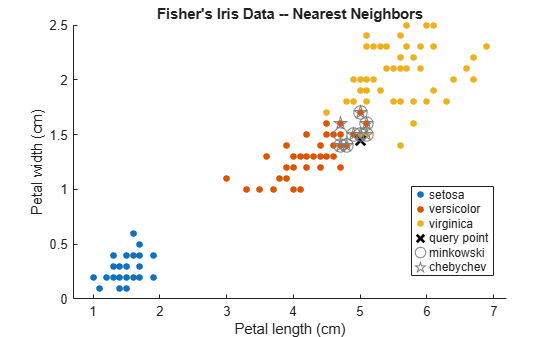
Zoom in on the points of interest.
h = gca; % Get current axis handle. h.XLim = [4.5 5.5]; h.YLim = [1 2]; axis square;
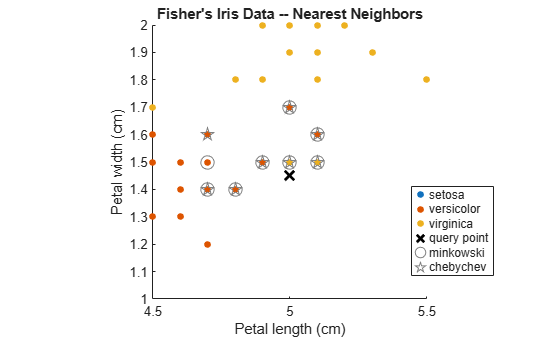
Several observations are equal, which is why only eight nearest neighbors are identified in the plot.
Create a large data set and compare the speed of an HNSW searcher to the speed of an exhaustive searcher for 1000 query points.
Create the data.
rng default % For reproducibility A = diag(1:100); B = randn(100,10); K = kron(A,B); ss = size(K)
ss = 1×2
10000 1000
The data K has 1e4 rows and 1e3 columns.
Create an HNSW searcher object h from the data K.
tic; h = hnswSearcher(K); chnsw = toc
chnsw = 10.6544
Create 1000 random query points with 1000 features (columns). Specify to search for five nearest neighbors.
Y = randn(1000, 1000); tic; [idx, D] = knnsearch(h,Y,K=5); thnsw = toc
thnsw = 0.0797
Create an exhaustive searcher object e from the data K.
tic e = ExhaustiveSearcher(K); ces = toc
ces = 0.0021
Creating an exhaustive searcher is much faster than creating an HNSW searcher.
Time the search using e and compare the result to the time using the HNSW searcher h.
tic; [idx0, D0] = knnsearch(e,Y,K=5); tes = toc
tes = 1.4841
In this case, the HNSW searcher computes about 20 times faster than the exhaustive searcher.
Determine how many results of the HNSW search differ in some way from the results of the exhaustive search.
v = abs(idx - idx0); % Count any difference in the five found entries vv = sum(v,2); % vv = 0 means no difference nz = nnz(vv) % Out of 1000 rows how many differ at all?
nz = 118
Here, 118 of 1000 HNSW search results differ from the exhaustive search results.
Try to improve the accuracy of the HNSW searcher by training with nondefault parameters. Specifically, use larger values for MaxNumLinksPerNode and TrainSetSize. These settings affect the speed of training and finding nearest neighbors.
tic; h2 = hnswSearcher(K,MaxNumLinksPerNode=48,TrainSetSize=2000); chnsw2 = toc
chnsw2 = 78.4836
With these parameters, the searcher takes about seven times as long to train.
tic; [idx2, D2] = knnsearch(h2,Y,K=5); thnsw2 = toc
thnsw2 = 0.1049
The speed of finding nearest neighbors using HNSW decreases, but is still more than ten times faster than the exhaustive search.
v = abs(idx2 - idx0); vv = sum(v,2); nz = nnz(vv)
nz = 57
For the slower but more accurate HNSW search, only 57 of 1000 results differ in any way from the exact results. Summarize the timing results in a table.
timet = table([chnsw;ces;chnsw2],[thnsw;tes;thnsw2],'RowNames',["HNSW";"Exhaustive";"HNSW2"],'VariableNames',["Creation" "Search"])
timet=3×2 table
Creation Search
_________ ________
HNSW 10.654 0.079741
Exhaustive 0.0021304 1.4841
HNSW2 78.484 0.10492
Input Arguments
Name-Value Arguments
Output Arguments
Tips
knnsearch finds the k (positive integer)
points in Mdl.X that are k-nearest for each
Y point. In contrast, rangesearch finds all the points in Mdl.X that are
within distance r (positive scalar) of each Y
point.
Algorithms
Alternative Functionality
knnsearchis an object function that requires anExhaustiveSearcher,KDTreeSearcher, orhnswSearchermodel object and query data. Under equivalent conditions for an exhaustive or Kd-tree search, theknnsearchobject function returns the same results as theknnsearchfunction with the specified name-value argumentNSMethod="exhaustive"orNSMethod="kdtree", respectively. Note that theknnsearchfunction does not provide a similar name-value argument for specifying anhnswSearchermodel.For k-nearest neighbors classification, see
fitcknnandClassificationKNN.
References
[1] Albanie, Samuel. Euclidean Distance Matrix Trick. June, 2019. Available at https://samuelalbanie.com/files/Euclidean_distance_trick.pdf.
[2] Friedman, J. H., Bentley, J., and Finkel, R. A. (1977). “An Algorithm for Finding Best Matches in Logarithmic Expected Time.” ACM Transactions on Mathematical Software Vol. 3, Issue 3, Sept. 1977, pp. 209–226.
[3] Malkov, Yu. A., and D. A. Yashunin. Efficient and Robust Approximate Nearest Neighbor Search Using Hierarchical Navigable Small World Graphs. Available at https://arxiv.org/abs/1603.09320.