cluster
Construct agglomerative clusters from linkages
Description
T = cluster(Z,Cutoff=cutoff)Z.
The input Z is the output of the linkage function for an input data matrix X.
cluster cuts Z into clusters, using
cutoff as a threshold for the inconsistency coefficients (or
inconsistent values) of nodes in the tree. The
output T contains cluster assignments of each observation (row of
X).
T = cluster(___,Name=Value)cluster(Z,MaxClust=5,Depth=3) to find a maximum of five clusters by
evaluating distance values up to a depth of three below each node.
Examples
Perform agglomerative clustering on randomly generated data by evaluating inconsistent values to a depth of four below each node.
Randomly generate the sample data.
rng(0,"twister"); % For reproducibility X = [(randn(20,2)*0.75)+1; (randn(20,2)*0.25)-1];
Create a scatter plot of the data.
scatter(X(:,1),X(:,2));
title("Randomly Generated Data");
Create a hierarchical cluster tree using the ward linkage method.
Z = linkage(X,"ward");Create a dendrogram plot of the data.
dendrogram(Z)

The scatter plot and the dendrogram plot seem to show two clusters in the data.
Cluster the data using a threshold of 3 for the inconsistency coefficient and looking to a depth of 4 below each node. Plot the resulting clusters.
T = cluster(Z,Cutoff=3,Depth=4); gscatter(X(:,1),X(:,2),T)

cluster identifies two clusters in the data.
Perform agglomerative clustering on the fisheriris data set using "distance" as the criterion for defining clusters. Visualize the cluster assignments of the data.
Load the fisheriris data set.
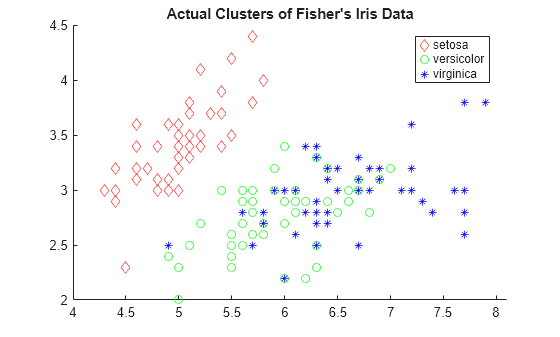
load fisheririsVisualize a 2-D scatter plot of the data using species as the grouping variable. Specify marker colors and marker symbols for the three different species.
gscatter(meas(:,1),meas(:,2),species,"rgb","do*") title("Actual Clusters of Fisher's Iris Data")
Create a hierarchical cluster tree using the "average" method and the "chebychev" metric.
Z = linkage(meas,"average","chebychev");
Cluster the data using a threshold of 1.5 for the "distance" criterion.
T = cluster(Z,Cutoff=1.5,Criterion="distance")T = 150×1
2
2
2
2
2
2
2
2
2
2
2
2
2
2
2
⋮
T contains numbers that correspond to the cluster assignments. Find the number of classes that cluster identifies.
length(unique(T))
ans = 3
cluster identifies three classes for the specified values of cutoff and Criterion.
Visualize a 2-D scatter plot of the clustering results using T as the grouping variable. Specify marker colors and marker symbols for the three different classes.
gscatter(meas(:,1),meas(:,2),T,"rgb","do*") title("Cluster Assignments of Fisher's Iris Data")
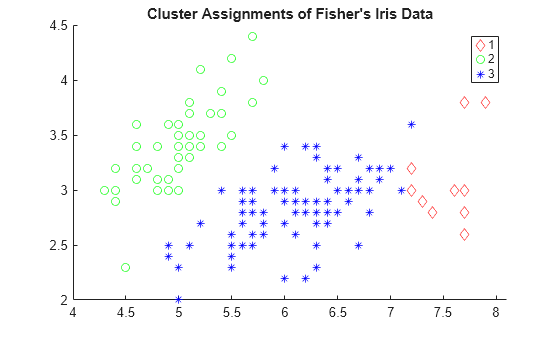
Clustering correctly identifies the setosa class (class 2) as belonging to a distinct cluster, but poorly distinguishes between the versicolor and virginica classes (classes 1 and 3, respectively). Note that the scatter plot labels the classes using the numbers contained in T.
Find a maximum of three clusters in the fisheriris data set and compare cluster assignments of the flowers to their known classification.
Load the sample data.
load fisheririsCreate a hierarchical cluster tree using the "average" method and the "chebychev" metric.
Z = linkage(meas,"average","chebychev");
Find a maximum of three clusters in the data.
T = cluster(Z,MaxClust=3);
Create a dendrogram plot of Z. To see the three clusters, use ColorThreshold with a cutoff halfway between the third-from-last and second-from-last linkages.
cutoff = median([Z(end-2,3) Z(end-1,3)]); dendrogram(Z,ColorThreshold=cutoff,ShowCut=true)
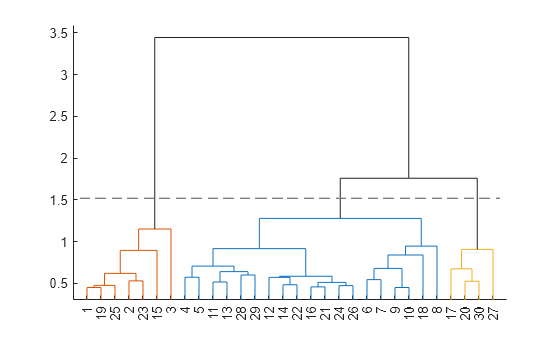
Display the last two rows of Z to see how the three clusters are combined into one. linkage combines the 293rd (orange) cluster with the 297th (blue) cluster to form the 298th cluster with a linkage of 1.7583. linkage then combines the 296th (red) cluster with the 298th cluster.
lastTwo = Z(end-1:end,:)
lastTwo = 2×3
293.0000 297.0000 1.7583
296.0000 298.0000 3.4445
The cluster assignments correspond to the three species. For example, one of the clusters contains 50 flowers of the second species and 40 flowers of the third species.
crosstab(T,species)
ans = 3×3
0 0 10
0 50 40
50 0 0
Randomly generate sample data with 20,000 observations.
rng(0,"twister") % For reproducibility X = rand(20000,3);
Create a hierarchical cluster tree using the ward linkage method. In this case, the SaveMemory option of the clusterdata function is set to "on" by default. In general, specify the best value for SaveMemory based on the dimensions of X and the available memory.
Z = linkage(X,"ward");Cluster the data into a maximum of four groups and plot the result.
c = cluster(Z,MaxClust=4); scatter3(X(:,1),X(:,2),X(:,3),10,c)

cluster identifies four groups in the data.
Input Arguments
Name-Value Arguments
Output Arguments
Alternative Functionality
If you have an input data matrix X, you can use clusterdata to perform agglomerative clustering and return cluster indices for
each observation (row) in X. The clusterdata function
performs all the necessary steps for you, so you do not need to execute the pdist, linkage, and cluster
functions separately.