One-Factor Model Calibration
This example demonstrates techniques to calibrate a one-factor model for estimating portfolio credit losses using the creditDefaultCopula or creditMigrationCopula classes.
This example uses equity return data as a proxy for credit fluctuations. With equity data, sensitivity to a single factor is estimated as a correlation between a stock and an index. The data set contains daily return data for a series of equities, but the one-factor model requires calibration on a year-over-year basis. Assuming that there is no autocorrelation, then the daily cross-correlation between a stock and the market index is equal to the annual cross-correlation. For stocks exhibiting autocorrelation, this example shows how to compute implied annual correlations incorporating the effect of autocorrelation.
Fitting a One-Factor Model
Since corporate defaults are rare, it is common to use a proxy for creditworthiness when calibrating default models. The one-factor copula models the credit worthiness of a company using a latent variable, A:
where X is the systemic credit factor, w is the weight that defines the sensitivity of a company to the one factor, and is the idiosyncratic factor. w and have mean of 0 and variance of 1 and typically are assumed to be either Gaussian or else t distributions.
Compute the correlation between X and A:
Since X and A have a variance of 1 by construction and is uncorrelated with X, then:
If you use stock returns as a proxy for A and the market index returns are a proxy for X, then the weight parameter, w, is the correlation between the stock and the index.
Prepare the Data
Use the returns of the Dow Jones Industrial Average (DJIA) as a signal for the overall credit movement of the market. The returns for the 30 component companies are used to calibrate the sensitivity of each company to the systemic credit movement. Weights for other companies in the stock market are estimated in the same way.
% Read one year of DJIA price data. t = readtable('dowPortfolio.xlsx'); % The table contains dates and the prices for each company at market close % as well as the DJIA. disp(head(t(:,1:7)))
Dates DJI AA AIG AXP BA C
___________ _____ _____ _____ _____ _____ _____
03-Jan-2006 10847 28.72 68.41 51.53 68.63 45.26
04-Jan-2006 10880 28.89 68.51 51.03 69.34 44.42
05-Jan-2006 10882 29.12 68.6 51.57 68.53 44.65
06-Jan-2006 10959 29.02 68.89 51.75 67.57 44.65
09-Jan-2006 11012 29.37 68.57 53.04 67.01 44.43
10-Jan-2006 11012 28.44 69.18 52.88 67.33 44.57
11-Jan-2006 11043 28.05 69.6 52.59 68.3 44.98
12-Jan-2006 10962 27.68 69.04 52.6 67.9 45.02
% We separate the dates and the index from the table and compute daily returns using % tick2ret. dates = t{2:end,1}; index_adj_close = t{:,2}; stocks_adj_close = t{:,3:end}; index_returns = tick2ret(index_adj_close); stocks_returns = tick2ret(stocks_adj_close);
Compute Single Factor Weights
Compute the single-factor weights from the correlation coefficients between the index returns and the stock returns for each company.
[C,daily_pval] = corr([index_returns stocks_returns]); w_daily = C(2:end,1);
These values can be used directly when using a one-factor creditDefaultCopula or creditMigrationCopula.
Linear regression is often used in the context of factor models. For a one-factor model, a linear regression of the stock returns on the market returns is used by exploiting the fact that the correlation coefficient matches the square root of the coefficient of determination (R-squared) of a linear regression.
w_daily_regress = zeros(30,1); for i = 1:30 lm = fitlm(index_returns,stocks_returns(:,i)); w_daily_regress(i) = sqrt(lm.Rsquared.Ordinary); end % The regressed R values are equal to the index cross correlations. fprintf('Max Abs Diff : %e\n',max(abs(w_daily_regress(:) - w_daily(:))))
Max Abs Diff : 8.326673e-16
This linear regression fits a model of the form , which in general does not match the one-factor model specifications. For example, and do not have a zero mean and a standard deviation of 1. In general, there is no relationship between the coefficient and the standard deviation of the error term . Linear regression is used above only as a tool to get the correlation coefficient between the variables given by the square root of the R-squared value.
For one-factor model calibration, a useful alternative is to fit a linear regression using the standardized stock and market return data and . "Standardize" here means to subtract the mean and divide by the standard deviation. The model is . However, because both and have a zero mean, the intercept is always zero, and because both and have standard deviation of 1, the standard deviation of the error term satisfies . This exactly matches the specifications of the coefficients of a one-factor model. The one-factor parameter is set to the coefficient , and is the same as the value found directly through correlation earlier.
w_regress_std = zeros(30,1); index_returns_std = zscore(index_returns); stocks_returns_std = zscore(stocks_returns); for i = 1:30 lm = fitlm(index_returns_std,stocks_returns_std(:,i)); w_regress_std(i) = lm.Coefficients{'x1','Estimate'}; end % The regressed R values are equal to the index cross correlations. fprintf('Max Abs Diff : %e\n',max(abs(w_regress_std(:) - w_daily(:))))
Max Abs Diff : 5.551115e-16
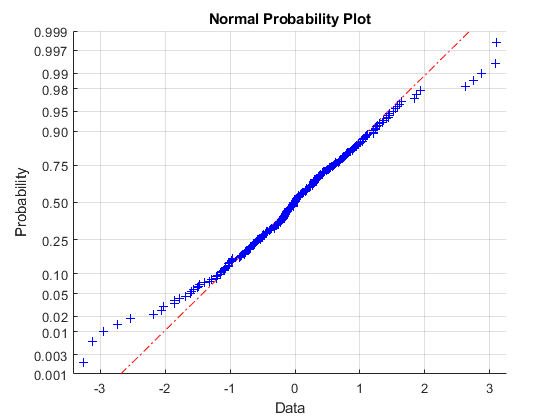
This approach makes it natural to explore the distributional assumptions of the variables. The creditDefaultCopula and creditMigrationCopula objects support either normal distributions, or t distributions for the underlying variables. For example, when using normplot the market returns have heavy tails, therefore a t-copula is more consistent with the data.
normplot(index_returns_std)
Estimating Correlations for Longer Periods
The weights are computed based on the daily correlation between the stocks and the index. However, the usual goal is to estimate potential losses from credit defaults at some time further in the future, often one year out.
To that end, it is necessary to calibrate the weights such that they correspond to the one-year correlations. It is not practical to calibrate directly against historical annual return data since any reasonable data set does not have enough data to be statistically significant due to the sparsity of the data points.
You then face the problem of computing annual return correlation from a more frequently sampled data set, for example, daily returns. One approach to solving this problem is to use an overlapping window. This way you can consider the set of all overlapping periods of a given length.
% As an example, consider an overlapping 1-week window. index_overlapping_returns = index_adj_close(6:end) ./ index_adj_close(1:end-5) - 1; stocks_overlapping_returns = stocks_adj_close(6:end,:) ./ stocks_adj_close(1:end-5,:) - 1; C = corr([index_overlapping_returns stocks_overlapping_returns]); w_weekly_overlapping = C(2:end,1); % Compare the correlation with the daily correlation. % Show the daily vs. the overlapping weekly correlations. barh([w_daily w_weekly_overlapping]) yticks(1:30) yticklabels(t.Properties.VariableNames(3:end)) title('Correlation with the Index'); legend('daily','overlapping weekly');
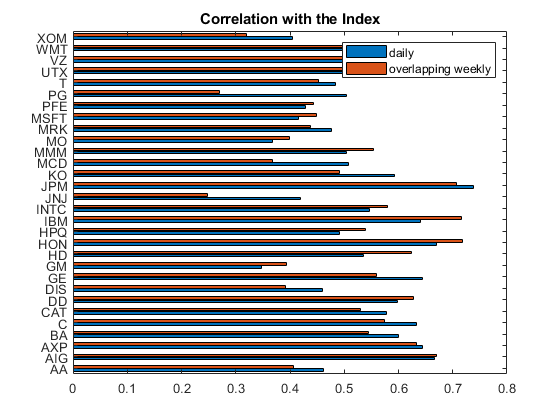
The maximum cross-correlation p-value for daily returns show a strong statistical significance.
maxdailypvalue = max(daily_pval(2:end,1)); disp(table(maxdailypvalue,... 'VariableNames',{'Daily'},... 'rownames',{'Maximum p-value'}))
Daily
__________
Maximum p-value 1.5383e-08
Moving to an overlapping rolling-window-style weekly correlation gives slightly different correlations. This is a convenient way to estimate longer period correlations from daily data. However, the returns of adjacent overlapping windows are correlated so the corresponding p-values for the overlapping weekly returns are not valid since the p-value calculation in the corr function does not account for overlapping window data sets. For example, adjacent overlapping window returns are composed of many of the same datapoints. This tradeoff is necessary since moving to nonoverlapping windows could result is an unacceptably sparse sample.
% Compare to non-overlapping weekly returns fridays = weekday(dates) == 6; index_weekly_close = index_adj_close(fridays); stocks_weekly_close = stocks_adj_close(fridays,:); index_weekly_returns = tick2ret(index_weekly_close); stocks_weekly_returns = tick2ret(stocks_weekly_close); [C,weekly_pval] = corr([index_weekly_returns stocks_weekly_returns]); w_weekly_nonoverlapping = C(2:end,1); maxweeklypvalue = max(weekly_pval(2:end,1)); % Compare the correlation with the daily and overlapping. barh([w_daily w_weekly_overlapping w_weekly_nonoverlapping]) yticks(1:30) yticklabels(t.Properties.VariableNames(3:end)) title('Correlation with the Index'); legend('daily','overlapping weekly','non-overlapping weekly');
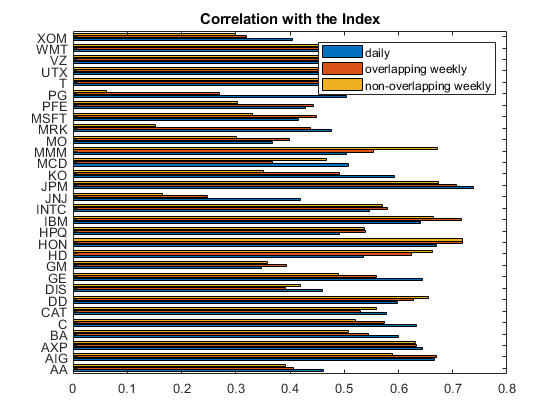
The p-values for the nonoverlapping weekly correlations are much higher, indicating a loss of statistical significance.
% Compute the number of samples in each series. numDaily = numel(index_returns); numOverlapping = numel(index_overlapping_returns); numWeekly = numel(index_weekly_returns); disp(table([maxdailypvalue;numDaily],[NaN;numOverlapping],[maxweeklypvalue;numWeekly],... 'VariableNames',{'Daily','Overlapping','Non_Overlapping'},... 'rownames',{'Maximum p-value','Sample Size'}))
Daily Overlapping Non_Overlapping
__________ ___________ _______________
Maximum p-value 1.5383e-08 NaN 0.66625
Sample Size 250 246 50
Extrapolating Annual Correlation
A common assumption with financial data is that asset returns are temporally uncorrelated. That is, the asset return at time T is uncorrelated to the previous return at time T-1. Under this assumption, the annual cross-correlation is exactly equal to the daily cross-correlation.
Let be the daily log return of the market index on day t and be the daily return of a correlated asset. Using CAPM, the relation is modeled as:
The one-factor model is a special case of this relationship.
Under the assumption that asset and index returns are each uncorrelated with their respective past, then:
y,
Let the aggregate annual (log) return for each series be
where T could be 252 depending on the underlying daily data.
Let and be the daily variances, which are estimated from the daily return data.
The daily covariance between and is:
The daily correlation between and is:
Consider the variances and covariances for the aggregate year of returns. Under the assumption of no autocorrelation:
The annual correlation between the asset and the index is:
Under the assumption of no autocorrelation, notice that the daily cross-correlation is in fact equal to the annual cross-correlation. You can use this assumption directly in the one-factor model by setting the one-factor weights to the daily cross-correlation.
Handling Autocorrelation
If the assumption that assets have no autocorrelation is loosened, then the transformation from daily to annual cross-correlation between assets is not as straightforward. The now has additional terms.
First consider the simplest case of computing the variance of when T is equal to 2.
Since , then:
Consider T = 3. Indicate the correlation between daily returns that are days apart as .
In the general case, for the variance of an aggregate T-day return with autocorrelation from trailing k days, there is:
This is also the same formula for the asset variance:
The covariance between and as shown earlier is equal to .
Therefore, the cross-correlation between the index and the asset with autocorrelation from a trailing 1 through k days is:
Note that is the weight under the assumption of no autocorrelation. The square root term provides the adjustment to account for autocorrelation in the series. The adjustment depends more on the difference between the index autocorrelation and the stock autocorrelation, rather than the magnitudes of these autocorrelations. So the annual one-factor weight adjusted for autocorrelation is:
Compute Weights with Autocorrelation
Look for autocorrelation in each of the stocks with the previous day's return, and adjust the weights to incorporate the effect of a one-day autocorrelation.
corr1 = zeros(30,1); pv1 = zeros(30,1); for stockidx = 1:30 [corr1(stockidx),pv1(stockidx)] = corr(stocks_returns(2:end,stockidx),stocks_returns(1:end-1,stockidx)); end autocorrIdx = find(pv1 < 0.05)
autocorrIdx = 4×1
10
18
26
27
There are four stocks with low p-values that may indicate the presence of autocorrelation. Estimate the annual cross-correlation with the index under this model, considering the one-day autocorrelation.
% The weights based off of yearly cross correlation are equal to the daily cross % correlation multiplied by an additional factor. T = 252; w_yearly = w_daily; [rho_index, pval_index] = corr(index_returns(1:end-1),index_returns(2:end)); % Check to see if the index has any significant autocorrelation. fprintf('One day autocorrelation in the index p-value: %f\n',pval_index);
One day autocorrelation in the index p-value: 0.670196
if pval_index < 0.05 % If the p-value indicates there is no significant autocorrelation in the index, % set its rho to 0. rho_index = 0; end w_yearly(autocorrIdx) = w_yearly(autocorrIdx) .*... sqrt((T/2 + (T-1) .* rho_index) ./ (T/2 + (T-1) .* corr1(autocorrIdx))); % Compare the adjusted annual cross correlation values to the daily values. barh([w_daily(autocorrIdx) w_yearly(autocorrIdx)]) yticks(1:4); allNames = t.Properties.VariableNames(3:end); yticklabels(allNames(autocorrIdx)) title('Annual One Factor Weights'); legend('No autocorrelation','With autocorrelation','location','southeast');

See Also
creditDefaultCopula | simulate | portfolioRisk | riskContribution | confidenceBands | getScenarios