Decide When to Use parfor
parfor-Loops in MATLAB
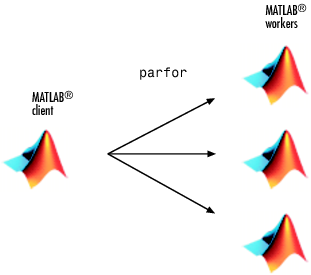
A parfor-loop in MATLAB® executes a series of statements in the loop body in parallel. The
MATLAB client issues the parfor command and coordinates
with MATLAB workers to execute the loop iterations in parallel on the workers in a
parallel pool. The client sends the necessary data on which
parfor operates to workers, where most of the computation is
executed. The results are sent back to the client and assembled.
A parfor-loop can provide significantly better performance
than its analogous for-loop, because several MATLAB workers can compute simultaneously on the same loop.
Each execution of the body of a parfor-loop is an
iteration. MATLAB workers evaluate iterations in no particular order and independently
of each other. Because each iteration is independent, there is no guarantee that the
iterations are synchronized in any way, nor is there any need for this. If the
number of workers is equal to the number of loop iterations, each worker performs
one iteration of the loop. If there are more iterations than workers, some workers
perform more than one loop iteration; in this case, a worker might receive multiple
iterations at once to reduce communication time.
Deciding When to Use parfor
A parfor-loop can be useful if you have a slow
for-loop. Consider parfor if you have:
Some loop iterations that take a long time to execute. In this case, the workers can execute the long iterations simultaneously. Make sure that the number of iterations exceeds the number of workers. Otherwise, you will not use all workers available.
Many loop iterations of a simple calculation, such as a Monte Carlo simulation or a parameter sweep.
parfordivides the loop iterations into groups so that each worker executes some portion of the total number of iterations.Multiple GPUs and your computations use GPU-enabled functions. For more information about using multiple GPUs in a
parfor-loop, see Run MATLAB Functions on Multiple GPUs.
A parfor-loop might not be useful if you have:
Code that has vectorized out the
for-loops. Generally, if you want to make code run faster, first try to vectorize it. For details how to do this, see Vectorization. Vectorizing code allows you to benefit from the built-in parallelism provided by the multithreaded nature of many of the underlying MATLAB libraries. However, if you have vectorized code and you have access only to local workers, thenparfor-loops may run slower thanfor-loops. Do not devectorize code to allow forparfor; in general, this solution does not work well.Loop iterations that take a short time to execute. In this case, parallel overhead dominates your calculation.
Loop iterations that all use the same GPU. GPUs contain many microprocessors that can perform computations in parallel and trying to further parallelize GPU computations using a
parfor-loop is unlikely to speed up your code.
You cannot use a parfor-loop when an iteration in your loop
depends on the results of other iterations. Each iteration must be independent of
all others. For help dealing with independent loops, see Ensure That parfor-Loop Iterations Are Independent.
The exception to this rule is to accumulate values in a loop using Reduction Variables.
In deciding when to use parfor, consider parallel overhead.
Parallel overhead includes the time required for communication, coordination and
data transfer — sending and receiving data — from client to workers
and back. If iteration evaluations are fast, this overhead could be a significant
part of the total time. Consider two different types of loop iterations:
for-loops with a computationally demanding task. These loops are generally good candidates for conversion into aparfor-loop, because the time needed for computation dominates the time required for data transfer.for-loops with a simple computational task. These loops generally do not benefit from conversion into aparfor-loop, because the time needed for data transfer is significant compared with the time needed for computation.
Example of parfor with Low Parallel Overhead
In this example, you start with a computationally demanding task inside a
for-loop. The for-loops are slow, and
you speed up the calculation using parfor-loops instead.
parfor splits the execution of
for-loop iterations over the workers in a parallel pool.
This example calculates the spectral radius of a matrix and
converts a for-loop into a parfor-loop.
Find out how to measure the resulting speedup and how much data is transferred to
and from the workers in the parallel pool.
In the MATLAB Editor, enter the following
for-loop. Addticandtocto measure the computation time.tic n = 200; A = 500; a = zeros(1,n); for i = 1:n a(i) = max(abs(eig(rand(A)))); end toc
Run the script, and note the elapsed time.
Elapsed time is 31.935373 seconds.
In the script, replace the
for-loop with aparfor-loop. AddticBytesandtocBytesto measure how much data is transferred to and from the workers in the parallel pool.tic ticBytes(gcp); n = 200; A = 500; a = zeros(1,n); parfor i = 1:n a(i) = max(abs(eig(rand(A)))); end tocBytes(gcp) toc
Run the new script on four workers, and run it again. Note that the first run is slower than the second run, because the parallel pool takes some time to start and make the code available to the workers. Note the data transfer and elapsed time for the second run.
By default, MATLAB automatically opens a parallel pool of workers on your local machine.
TheStarting parallel pool (parpool) using the 'Processes' profile ... connected to 4 workers. ... BytesSentToWorkers BytesReceivedFromWorkers __________________ ________________________ 1 15340 7024 2 13328 5712 3 13328 5704 4 13328 5728 Total 55324 24168 Elapsed time is 10.760068 seconds.parforrun on four workers is about three times faster than the correspondingfor-loop calculation. The speed-up is smaller than the ideal speed-up of a factor of four on four workers. This is due to parallel overhead, including the time required to transfer data from the client to the workers and back. Use theticBytesandtocBytesresults to examine the amount of data transferred. Assume that the time required for data transfer is proportional to the size of the data. This approximation allows you to get an indication of the time required for data transfer, and to compare your parallel overhead with otherparfor-loop iterations. In this example, the data transfer and parallel overhead are small in comparison with the next example.
The current example has a low parallel overhead and benefits from conversion into
a parfor-loop. Compare this example with the simple loop
iteration in the next example, see Example of parfor with High Parallel Overhead.
For another example of a parfor-loop with computationally
demanding tasks, see Nested parfor and for-Loops and Other parfor Requirements
Example of parfor with High Parallel Overhead
In this example, you write a loop to create a simple sine wave. Replacing the
for-loop with a parfor-loop does
not speed up your calculation. This loop does not have a
lot of iterations, it does not take long to execute and you do not notice an
increase in execution speed. This example has a high parallel overhead and does not
benefit from conversion into a parfor-loop.
Write a loop to create a sine wave. Use
ticandtocto measure the time elapsed.tic n = 1024; A = zeros(n); for i = 1:n A(i,:) = (1:n) .* sin(i*2*pi/1024); end toc
Elapsed time is 0.012501 seconds.
Replace the
for-loop with aparfor-loop. AddticBytesandtocBytesto measure how much data is transferred to and from the workers in the parallel pool.tic ticBytes(gcp); n = 1024; A = zeros(n); parfor (i = 1:n) A(i,:) = (1:n) .* sin(i*2*pi/1024); end tocBytes(gcp) toc
Run the script on four workers and run the code again. Note that the first run is slower than the second run, because the parallel pool takes some time to start and make the code available to the workers. Note the data transfer and elapsed time for the second run.
Note that the elapsed time is much smaller for the serialBytesSentToWorkers BytesReceivedFromWorkers __________________ ________________________ 1 13176 2.0615e+06 2 15188 2.0874e+06 3 13176 2.4056e+06 4 13176 1.8567e+06 Total 54716 8.4112e+06 Elapsed time is 0.743855 seconds.for-loop than for theparfor-loop on four workers. In this case, you do not benefit from turning yourfor-loop into aparfor-loop. The reason is that the transfer of data is much greater than in the previous example, see Example of parfor with Low Parallel Overhead. In the current example, the parallel overhead dominates the computing time. Therefore the sine wave iteration does not benefit from conversion into aparfor-loop.
This example illustrates why high parallel overhead calculations do not benefit
from conversion into a parfor-loop. To learn more about speeding
up your code, see Convert for-Loops into parfor-Loops