Treat Missing Data in a Credit Scorecard Workflow Using MATLAB fillmissing
This example shows a workflow to gather missing data, manually treat the training data, develop a new creditscorecard, and treat new data before scoring using the MATLAB® fillmissing.
The advantage of this method is that you can use all the options available in fillmissing to fill missing data, as well as other MATLAB functionality such as standardizeMissing and features for the treatment of outliers. In this approach, note that you must ensure that the treatment of the training data and the treatment of any new data set that requires scoring must be the same.
Alternatively, after you create a creditscorecard object, you can use the fillmissing function for the creditscorecard object to fill missing values. For additional information on alternative approaches for "treating" missing data, see Credit Scorecard Modeling with Missing Values.
The dataMissing table in the CreditCardData.mat file has two predictors with missing values — CustAge and ResStatus.
load CreditCardData.mat
head(dataMissing) CustID CustAge TmAtAddress ResStatus EmpStatus CustIncome TmWBank OtherCC AMBalance UtilRate status
______ _______ ___________ ___________ _________ __________ _______ _______ _________ ________ ______
1 53 62 <undefined> Unknown 50000 55 Yes 1055.9 0.22 0
2 61 22 Home Owner Employed 52000 25 Yes 1161.6 0.24 0
3 47 30 Tenant Employed 37000 61 No 877.23 0.29 0
4 NaN 75 Home Owner Employed 53000 20 Yes 157.37 0.08 0
5 68 56 Home Owner Employed 53000 14 Yes 561.84 0.11 0
6 65 13 Home Owner Employed 48000 59 Yes 968.18 0.15 0
7 34 32 Home Owner Unknown 32000 26 Yes 717.82 0.02 1
8 50 57 Other Employed 51000 33 No 3041.2 0.13 0
First, analyze the missing data information using the untreated training data.
Create a creditscorecard object using the CreditCardData.mat file to load the dataMissing that contains missing values. Set the 'BinMissingData' argument for creditscorecard to true to explicitly report information on missing values. Then apply automatic binning using autobinning.
sc = creditscorecard(dataMissing,'IDVar','CustID','BinMissingData',true); sc = autobinning(sc);
The bin information and bin plots for predictors that have missing data both show a <missing> bin at the end. The two predictors with missing values in this data set are CustAge and ResStatus.
bi = bininfo(sc,'CustAge');
disp(bi) Bin Good Bad Odds WOE InfoValue
_____________ ____ ___ ______ ________ __________
{'[-Inf,33)'} 69 52 1.3269 -0.42156 0.018993
{'[33,37)' } 63 45 1.4 -0.36795 0.012839
{'[37,40)' } 72 47 1.5319 -0.2779 0.0079824
{'[40,46)' } 172 89 1.9326 -0.04556 0.0004549
{'[46,48)' } 59 25 2.36 0.15424 0.0016199
{'[48,51)' } 99 41 2.4146 0.17713 0.0035449
{'[51,58)' } 157 62 2.5323 0.22469 0.0088407
{'[58,Inf]' } 93 25 3.72 0.60931 0.032198
{'<missing>'} 19 11 1.7273 -0.15787 0.00063885
{'Totals' } 803 397 2.0227 NaN 0.087112
plotbins(sc,'CustAge')
bi = bininfo(sc,'ResStatus');
disp(bi) Bin Good Bad Odds WOE InfoValue
______________ ____ ___ ______ _________ __________
{'Tenant' } 296 161 1.8385 -0.095463 0.0035249
{'Home Owner'} 352 171 2.0585 0.017549 0.00013382
{'Other' } 128 52 2.4615 0.19637 0.0055808
{'<missing>' } 27 13 2.0769 0.026469 2.3248e-05
{'Totals' } 803 397 2.0227 NaN 0.0092627
plotbins(sc,'ResStatus')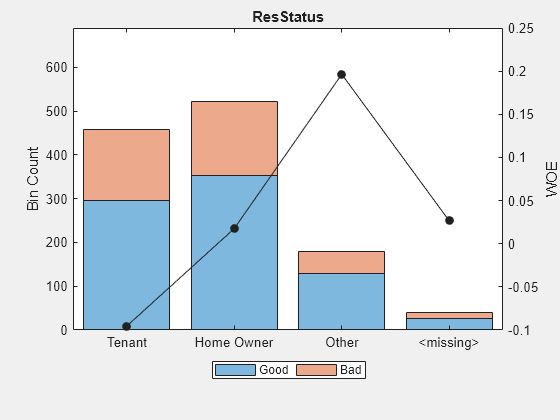
The missing bin can be left as is, although a common alternative is to treat the missing values. Note that treating the missing values must be done with care because it changes the data and can introduce bias.
To treat missing values, you can apply different criteria. This example follows a straightforward approach to replace missing observations with the most common or typical value in the data distribution, which is the value of mode for the data. For this example, the mode happens to have a similar WOE value as the original <missing> bin. The similarity in values is favorable because similar WOE values means similar points in a scorecard.
For CustAge, bin 4 is the bin with the most observations and the mode value of the original data is 43.
modeCustAge = mode(dataMissing.CustAge); disp(modeCustAge)
43
The WOE value of the <missing> bin is similar to the WOE value of bin 4. Therefore, replacing the missing values in CustAge with the value of mode is reasonable.
To treat the data, create a copy of the data and fill the missing values.
dataTreated = dataMissing;
dataTreated.CustAge = fillmissing(dataTreated.CustAge,'constant',modeCustAge);For ResStatus, the value of 'Home Owner' is the value of the mode of the data, and the WOE value of the <missing> bin is closest to that of the 'Home Owner' bin.
modeResStatus = mode(dataMissing.ResStatus); disp(modeResStatus)
Home Owner
Use MATLAB® fillmissing to replace the missing data with 'Home Owner'.
dataTreated.ResStatus = fillmissing(dataTreated.ResStatus,'constant',string(modeResStatus));The treated data set now has no missing values.
disp(any(any(ismissing(dataTreated))))
0
Using the treated data set, apply the typical creditscorecard workflow. First, create a creditscorecard object with the treated data and then apply automatic binning.
scTreated = creditscorecard(dataTreated,'IDVar','CustID'); scTreated = autobinning(scTreated);
Compare the bin information of the untreated data for CustAge with the bin information of the treated data for CustAge.
bi = bininfo(sc,'CustAge');
disp(bi) Bin Good Bad Odds WOE InfoValue
_____________ ____ ___ ______ ________ __________
{'[-Inf,33)'} 69 52 1.3269 -0.42156 0.018993
{'[33,37)' } 63 45 1.4 -0.36795 0.012839
{'[37,40)' } 72 47 1.5319 -0.2779 0.0079824
{'[40,46)' } 172 89 1.9326 -0.04556 0.0004549
{'[46,48)' } 59 25 2.36 0.15424 0.0016199
{'[48,51)' } 99 41 2.4146 0.17713 0.0035449
{'[51,58)' } 157 62 2.5323 0.22469 0.0088407
{'[58,Inf]' } 93 25 3.72 0.60931 0.032198
{'<missing>'} 19 11 1.7273 -0.15787 0.00063885
{'Totals' } 803 397 2.0227 NaN 0.087112
biTreated = bininfo(scTreated,'CustAge');
disp(biTreated) Bin Good Bad Odds WOE InfoValue
_____________ ____ ___ ______ ________ _________
{'[-Inf,33)'} 69 52 1.3269 -0.42156 0.018993
{'[33,37)' } 63 45 1.4 -0.36795 0.012839
{'[37,40)' } 72 47 1.5319 -0.2779 0.0079824
{'[40,45)' } 156 86 1.814 -0.10891 0.0024345
{'[45,48)' } 94 39 2.4103 0.17531 0.0033002
{'[48,58)' } 256 103 2.4854 0.20603 0.01223
{'[58,Inf]' } 93 25 3.72 0.60931 0.032198
{'Totals' } 803 397 2.0227 NaN 0.089977
The first few bins are the same, but the treatment of missing values influences the binning results, starting with the bin where the missing data is placed. You can further explore your binning results using autobinning with a different algorithm or you can manually modify the bins using modifybins.
For ResStatus, the results for the treated data look similar to the initial results, except for the higher counts in the 'Home Owner' bin due to the treatment. For a categorical variable with more categories (or levels), an automatic algorithm can find category groups and the results can show more differences for before and after the treatment.
bi = bininfo(sc,'ResStatus');
disp(bi) Bin Good Bad Odds WOE InfoValue
______________ ____ ___ ______ _________ __________
{'Tenant' } 296 161 1.8385 -0.095463 0.0035249
{'Home Owner'} 352 171 2.0585 0.017549 0.00013382
{'Other' } 128 52 2.4615 0.19637 0.0055808
{'<missing>' } 27 13 2.0769 0.026469 2.3248e-05
{'Totals' } 803 397 2.0227 NaN 0.0092627
biTreated = bininfo(scTreated,'ResStatus');
disp(biTreated) Bin Good Bad Odds WOE InfoValue
______________ ____ ___ ______ _________ __________
{'Tenant' } 296 161 1.8385 -0.095463 0.0035249
{'Home Owner'} 379 184 2.0598 0.018182 0.00015462
{'Other' } 128 52 2.4615 0.19637 0.0055808
{'Totals' } 803 397 2.0227 NaN 0.0092603
Fit the logistic model, scale the points, and display the final scorecard.
[scTreated, mdl] = fitmodel(scTreated,'Display','off'); scTreated = formatpoints(scTreated,'PointsOddsAndPDO',[500 2 50]); ScPoints = displaypoints(scTreated); disp(ScPoints)
Predictors Bin Points
______________ _____________________ ______
{'CustAge' } {'[-Inf,33)' } 53.507
{'CustAge' } {'[33,37)' } 55.798
{'CustAge' } {'[37,40)' } 59.646
{'CustAge' } {'[40,45)' } 66.868
{'CustAge' } {'[45,48)' } 79.013
{'CustAge' } {'[48,58)' } 80.326
{'CustAge' } {'[58,Inf]' } 97.559
{'CustAge' } {'<missing>' } NaN
{'ResStatus' } {'Tenant' } 62.161
{'ResStatus' } {'Home Owner' } 73.305
{'ResStatus' } {'Other' } 90.777
{'ResStatus' } {'<missing>' } NaN
{'EmpStatus' } {'Unknown' } 58.846
{'EmpStatus' } {'Employed' } 86.887
{'EmpStatus' } {'<missing>' } NaN
{'CustIncome'} {'[-Inf,29000)' } 29.906
{'CustIncome'} {'[29000,33000)' } 56.219
{'CustIncome'} {'[33000,35000)' } 67.938
{'CustIncome'} {'[35000,40000)' } 70.123
{'CustIncome'} {'[40000,42000)' } 70.931
{'CustIncome'} {'[42000,47000)' } 82.3
{'CustIncome'} {'[47000,Inf]' } 96.647
{'CustIncome'} {'<missing>' } NaN
{'TmWBank' } {'[-Inf,12)' } 51.05
{'TmWBank' } {'[12,23)' } 61.018
{'TmWBank' } {'[23,45)' } 61.818
{'TmWBank' } {'[45,71)' } 92.921
{'TmWBank' } {'[71,Inf]' } 133.14
{'TmWBank' } {'<missing>' } NaN
{'OtherCC' } {'No' } 50.806
{'OtherCC' } {'Yes' } 75.642
{'OtherCC' } {'<missing>' } NaN
{'AMBalance' } {'[-Inf,558.88)' } 89.788
{'AMBalance' } {'[558.88,1254.28)' } 63.088
{'AMBalance' } {'[1254.28,1597.44)'} 59.711
{'AMBalance' } {'[1597.44,Inf]' } 49.157
{'AMBalance' } {'<missing>' } NaN
The new scorecard does not know that the data was treated, hence it assigns NaNs to the <missing> bins. If you need to score a new data set and it contains missing data, by default, the score function sets the points to NaN. To further explore the handling of missing data, take a few rows from the original data as test data and introduce some missing data.
tdata = dataTreated(11:14,mdl.PredictorNames); % Keep only the predictors retained in the model % Set some missing values tdata.CustAge(1) = NaN; tdata.ResStatus(2) = missing; tdata.EmpStatus(3) = missing; tdata.CustIncome(4) = NaN; disp(tdata)
CustAge ResStatus EmpStatus CustIncome TmWBank OtherCC AMBalance
_______ ___________ ___________ __________ _______ _______ _________
NaN Tenant Unknown 34000 44 Yes 119.8
48 <undefined> Unknown 44000 14 Yes 403.62
65 Home Owner <undefined> 48000 6 No 111.88
44 Other Unknown NaN 35 No 436.41
Score the new data and see how points are set to NaN, which leads to NaN scores.
[Scores,Points] = score(scTreated,tdata); disp(Scores)
NaN NaN NaN NaN
disp(Points)
CustAge ResStatus EmpStatus CustIncome TmWBank OtherCC AMBalance
_______ _________ _________ __________ _______ _______ _________
NaN 62.161 58.846 67.938 61.818 75.642 89.788
80.326 NaN 58.846 82.3 61.018 75.642 89.788
97.559 73.305 NaN 96.647 51.05 50.806 89.788
66.868 90.777 58.846 NaN 61.818 50.806 89.788
To assign points to missing data, one possibility is to use the name-value pair argument 'Missing' in formatpoints to choose how to assign points to missing values.
Use the 'MinPoints' option for the 'Missing' argument. This option assigns the minimum number of possible points in the scorecard to the missing data. In this example, the minimum number of possible points for CustIncome is 29.906, so the last row in the table gets 29.906 points for the missing CustIncome value.
scTreated = formatpoints(scTreated,'Missing','MinPoints'); [Scores,Points] = score(scTreated,tdata); disp(Scores)
469.7003 510.0812 518.0013 448.8099
disp(Points)
CustAge ResStatus EmpStatus CustIncome TmWBank OtherCC AMBalance
_______ _________ _________ __________ _______ _______ _________
53.507 62.161 58.846 67.938 61.818 75.642 89.788
80.326 62.161 58.846 82.3 61.018 75.642 89.788
97.559 73.305 58.846 96.647 51.05 50.806 89.788
66.868 90.777 58.846 29.906 61.818 50.806 89.788
However, for predictors treated in the training data, such as CustAge, the effect of the 'Missing' argument is inconsistent with the treatment of the training data. For example, for CustAge, the first observation gets 53.507 points for the missing value, yet if the new data were "treated," and the missing value for CustAge were replaced with the mode of the training data (age of 43), this observation falls in the [40,45) bin and receives 66.868 points.
Therefore, before scoring, data sets must be treated the same way the training data was treated. The use of the 'Missing' argument is still important to assign points for untreated predictors and the treated predictors receive points in a way that is consistent with the way the model was developed.
tdataTreated = tdata; tdataTreated.CustAge = fillmissing(tdataTreated.CustAge,'constant',modeCustAge); tdataTreated.ResStatus = fillmissing(tdataTreated.ResStatus,'constant',string(modeResStatus)); disp(tdataTreated)
CustAge ResStatus EmpStatus CustIncome TmWBank OtherCC AMBalance
_______ __________ ___________ __________ _______ _______ _________
43 Tenant Unknown 34000 44 Yes 119.8
48 Home Owner Unknown 44000 14 Yes 403.62
65 Home Owner <undefined> 48000 6 No 111.88
44 Other Unknown NaN 35 No 436.41
[Scores,Points] = score(scTreated,tdataTreated); disp(Scores)
483.0606 521.2249 518.0013 448.8099
disp(Points)
CustAge ResStatus EmpStatus CustIncome TmWBank OtherCC AMBalance
_______ _________ _________ __________ _______ _______ _________
66.868 62.161 58.846 67.938 61.818 75.642 89.788
80.326 73.305 58.846 82.3 61.018 75.642 89.788
97.559 73.305 58.846 96.647 51.05 50.806 89.788
66.868 90.777 58.846 29.906 61.818 50.806 89.788