detect
Detect objects using ACF object detector configured for monocular camera
Syntax
Description
[___] = detect(___,
specifies options using one or more name-value arguments. For example,
Name=Value)detect(detector,I,WindowStride=2) sets the stride of the sliding
window used to detect objects to 2.
Examples
Configure an ACF object detector for use with a monocular camera mounted on an ego vehicle. Use this detector to detect vehicles within video frames captured by the camera.
Load an acfObjectDetector object pretrained to detect vehicles.
detector = vehicleDetectorACF;
Model a monocular camera sensor by creating a monoCamera object. This object contains the camera intrinsics and the location of the camera on the ego vehicle.
focalLength = [309.4362 344.2161]; % [fx fy] principalPoint = [318.9034 257.5352]; % [cx cy] imageSize = [480 640]; % [mrows ncols] height = 2.1798; % height of camera above ground, in meters pitch = 14; % pitch of camera, in degrees intrinsics = cameraIntrinsics(focalLength,principalPoint,imageSize); monCam = monoCamera(intrinsics,height,'Pitch',pitch);
Configure the detector for use with the camera. Limit the width of detected objects to a typical range for vehicle widths: 1.5–2.5 meters. The configured detector is an acfObjectDetectorMonoCamera object.
vehicleWidth = [1.5 2.5]; detectorMonoCam = configureDetectorMonoCamera(detector,monCam,vehicleWidth);
Load a video captured from the camera, and create a video reader and player.
videoFile = fullfile(toolboxdir('driving'),'core','drivingdata','caltech_washington1.avi'); reader = VideoReader(videoFile); videoPlayer = vision.VideoPlayer('Position',[29 597 643 386]);
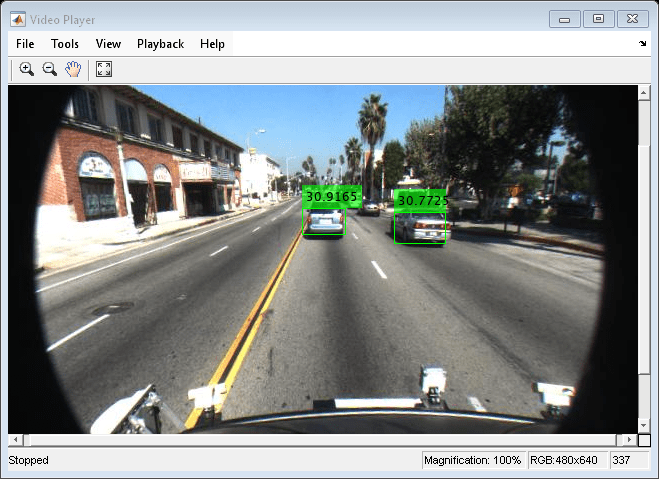
Run the detector in a loop over the video. Annotate the video with the bounding boxes for the detections and the detection confidence scores.
cont = hasFrame(reader); while cont I = readFrame(reader); % Run the detector. [bboxes,scores] = detect(detectorMonoCam,I); if ~isempty(bboxes) I = insertObjectAnnotation(I, ... 'rectangle',bboxes, ... scores, ... 'AnnotationColor','g'); end videoPlayer(I) % Exit the loop if the video player figure is closed. cont = hasFrame(reader) && isOpen(videoPlayer); end release(videoPlayer);
Input Arguments
Name-Value Arguments
Output Arguments
Version History
Introduced in R2017a