Multiperiod Goal-Based Wealth Management Using Reinforcement Learning
This example shows a reinforcement learning (RL) approach to maximize the probability of obtaining an investor's wealth goal at the end of the investment horizon. This problem is known in the literature as goal-based wealth management (GBWM). In GBWM, risk is not necessarily measured using the standard deviation, the value-at-risk, or any other common risk metric. Instead, risk is understood as the likelihood of not attaining an investor's goal. This alternative concept of risk implies that, sometimes, in order to increase the probability of attaining an investor’s goal, the optimal portfolio’s traditional risk (that is, standard deviation) must increase if the portfolio is underfunded. In other words, for the investor’s view of risk to decrease, the traditional view of risk must increase if the portfolio’s wealth is too low.
The purpose of the investment strategy is to determine a dynamic portfolio allocation that maximizes the probability of achieving a wealth goal G at the time horizon T. The dynamic allocation strategy is the optimal solution of the following multiperiod portfolio optimization problem
,
where is the terminal portfolio wealth and are the possible actions and allocations at time .
To solve this problem, this example follows the GBWM strategy of Das and Varma [1] uses RL to optimize the probability of attaining an investment goal. The goal of RL is to train an agent to complete a task within an unknown environment. The agent receives observations and a reward from the environment and sends actions to the environment. The reward is a measure of how successful an action is with respect to completing the task goal.
The agent contains two components: a policy and a learning algorithm.
The policy is a mapping that selects actions based on the observations from the environment. Typically, the policy is a function approximator with tunable parameters, such as a deep neural network.
The learning algorithm continuously updates the policy parameters based on the actions, observations, and reward. The goal of the learning algorithm is to find an optimal policy that maximizes the cumulative reward received during the task.
In other words, reinforcement learning involves an agent learning the optimal behavior through repeated trial-and-error interactions with the environment without human involvement. For more information on reinforcement learning, see What Is Reinforcement Learning? (Reinforcement Learning Toolbox).
The main advantage of leveraging reinforcement learning is that you can use an unknown environment. That is, in theory, you do not need to make assumptions about the state transition probabilities, you do not need to define the probability that the investment achieves a certain wealth level in a given time period. However, reinforcement learning assumes that there is an accurate way to simulate the transition from one state to the next for a given time period.
Problem Definition
rng(0,'twister');Specify the initial wealth.
initialWealth = 100;
Specify the target wealth at the end of the investment horizon.
targetWealth = 200;
Specify a time horizon.
finalTimePeriod = 10;
Define the mean and covariance of the annual returns.
returnMean = [0.05; 0.1; 0.25];
returnCovariance = [0.0025 0 0 ;
0 0.04 0.02 ;
0 0.02 0.25 ];To solve the problem using RL, you need to define:
Actions — Portfolio weights for investment portfolio.
Observations — Time period and wealth at time period .
Environment — Model of the evolution of the problem. The environment simulates the next observation after receiving an action and computes its associated reward.
Reward — Part of the environment that measures how well the received action contributes to achieving the task.
Agent — Component trained to complete the task within the environment. The agent is responsible for choosing the actions required to complete the task.
Define Actions
The action at each rebalancing period is to choose the weights of the investment portfolio for the next time period. In this example, assume that the possible portfolio weights are those of portfolios on the efficient frontier. Also, you can assume that the choice of possible portfolios is fixed throughout the full investment period and that they represent a finite subset of the efficient portfolios. By avoiding working with a set of continuous actions in this way, you simplify the training and easily account for the constraints on the portfolio weights (for example, that they sum to 1). However, you do have to assume that the distribution of the returns is time-homogeneous; that is, the underlying mean and covariance of the returns is the same at every time period.
Start by creating a Portfolio (Financial Toolbox) object with the asset information from the Problem Definition.
p = Portfolio(AssetMean=returnMean,AssetCovar=returnCovariance);
Add constraints to the portfolio problem. Use setBounds (Financial Toolbox) to bound the portfolio weights. Individual assets cannot represent more than 50% of the portfolio wealth and shorting is not allowed.
p = setBounds(p,0,0.5);
Use setBudget (Financial Toolbox) to specify that the portfolio must be fully invested.
p = setBudget(p,1,1);
Compute the weights of 15 portfolios on the efficient frontier using estimateFrontier (Financial Toolbox). These portfolios represent the possible actions at each rebalancing period.
numPortfolios = 15; pwgt = estimateFrontier(p,numPortfolios);
Plot the efficient frontier using plotFrontier (Financial Toolbox).
figure [prsk,pret] = plotFrontier(p,pwgt); hold on scatter(prsk,pret,"red","o","LineWidth",2) hold off
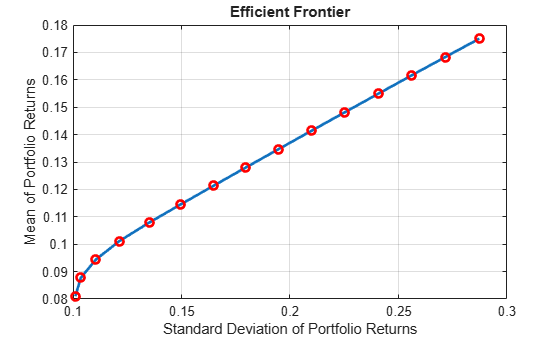
Use rlFiniteSetSpec (Reinforcement Learning Toolbox) to create the discrete action space for the reinforcement learning environment.
actionInfo = rlFiniteSetSpec(1:15);
Define Observations
The observations are defined as elements of the environment that describe important aspects of the current state. In this example the observations consist of the current time period and the wealth at that time period. Use rlNumericSpec (Reinforcement Learning Toolbox) to create the observations space, a vector containing two signals: the wealth level and the time period.
% Observation space: % [wealth; timePeriod] observationInfo = rlNumericSpec([2 1]);
Scale Observations
Signals with widely different ranges can skew the learning process, making it hard for the agent to successfully learn the important features. In this example, we scale the wealth level to the range [0,1]. To do this, we assume that the wealth follows a geometric Brownian motion
where is a standard normal random variable. The wealth does not need to follow a Brownian motion, but this assumption helps obtain reasonable upper and lower bounds on the wealth evolution.
Assuming that realistically takes values between and , we have that the smallest realistic value of is
% Define the minimum possible wealth. timeVec = 0:finalTimePeriod; mu_min = pret(1); sigma_max = prsk(end); WMinVec = initialWealth*exp((mu_min-(sigma_max^2)/2)*timeVec- ... 3*sigma_max*sqrt(timeVec)); WMin = min(WMinVec);
And the largest realistic value of is
% Define the maximum possible wealth. mu_max = pret(end); WMaxVec = initialWealth*exp((mu_max-(sigma_max^2)/2)*timeVec+ ... 3*sigma_max*sqrt(timeVec)); WMax = max(WMaxVec);
Create Environment Model
You create the environment model using the following steps:
Define a
myResetFunctionfunction that describes the initial conditions of the environment at the beginning of a training episode.Define a custom
myStepFunctionfunction that describes the dynamics of the environment. This includes how the state changes from a current state given the agent action and how the earned reward is computed by such an action. For the reward, here you can choose either a sparse reward function or a constant return reward function. At each training time step, the state of the model is updated using themyStepFunctionfunction. This function also determines when a training episode finishes.
For more information see Create Custom Environment Using Step and Reset Functions (Reinforcement Learning Toolbox).
Define Reset Function
The myResetFunction function (see Local Functions) sets the wealth level to its initial state, initialWealth, and the time period to 0.
resetFcn = @() myResetFunction(initialWealth,WMin,WMax);
State Change Model
The custom myStepFunction (see Local Functions) simulates the wealth evolution from the current time period to the next given the portfolio weights associated to the action selected by the agent. For simplicity, this example uses a geometric Brownian motion to simulate the wealth evolution. So, given a wealth level at time step t, the wealth level at time t+1 is:
,
where is a standard normal random variable and and are the mean and standard deviation of the portfolio associated with the th action.
Sparse Reward Function
Since the goal of the problem is to achieve the wealth target by the end of the investment period, you can use a reward function awards a value of 1 if the goal is achieved at the end of the investment period and 0 otherwise. See Local Functions for the sparseReward function.
% Sparse reward function handle sparseRewardFcnHandle = @(loggedSignals) sparseReward(loggedSignals, ... finalTimePeriod,targetWealth,WMin,WMax);
Agents defined with a sparse reward are challenging to train because a large amount of states do not return any signal. This issue becomes more apparent as the episodes become long.
Constant Return Reward Function
To reduce the training time, you can also use a reward function that tries to lead the agent to achieve a minimum wealth level at each investment period. The constantReturnReward function (see Local Functions) assumes that the returns are the same throughout the entire investment horizon and that the return value satisfies the following inequality:
.
% Compute r, the constant return needed to satisfy the goal by the % end of the investment horizon. constantReturn = ... nthroot(targetWealth/initialWealth,finalTimePeriod) - 1;
When the wealth level is greater than , you give the agent a small reward (in this example, select a reward of 0.1). Finally, you still give a reward of 1 if the agent reaches the goal at the end of the investment period and 0 otherwise.
Define the constant return reward function handle.
% Reward Function Handle constantReturnRewardFcnHandle = @(loggedSignals) constantReturnReward(loggedSignals, ... initialWealth,finalTimePeriod,targetWealth,constantReturn,WMin,WMax);
Episode Termination
The custom step function flags that the episode has finished when the current time period reaches finalTimePeriod.
Define Custom Step Function
Select the reward function, then define the step function handle.
% Select a reward function rewardFcnHandle =sparseRewardFcnHandle; % Define step function handle stepFcn = @(action,loggedSignals) myStepFunction(action, ... loggedSignals,prsk,pret,finalTimePeriod,rewardFcnHandle,WMin,WMax);
Define Environment
Use rlFunctionEnv (Reinforcement Learning Toolbox) to construct the custom environment using the defined observations, actions, and reset and step functions.
gbwmEnvironment = rlFunctionEnv(observationInfo,actionInfo,stepFcn, ...
resetFcn);Define Agent
The purpose of the agent is to select actions that are sent to the environment. The agent then receives new observations from the environment and the reward generated by the submitted actions. The goal of RL is to train the agent to select the best possible actions to maximize the probability of attaining the wealth goal by the end of the investment period.
Reinforcement Learning Toolbox™ provides several built-in agents that you can train in environments with either continuous or discrete observation and action spaces. The table in the section "Built-In Agents" of Reinforcement Learning Agents (Reinforcement Learning Toolbox) summarizes the types of agents for the different types of observation and action spaces.
Given that the action space in this example is discrete and the observation space is continuous, this example uses a Deep Q-Network (DQN) Agent (Reinforcement Learning Toolbox).
Use rlAgentInitializationOptions (Reinforcement Learning Toolbox) to specify the number of neurons in each learnable layer.
initializationOptions =... rlAgentInitializationOptions('NumHiddenUnit',100);
Use rlDQNAgent (Reinforcement Learning Toolbox) to create the agent using the defined action and observation specifications.
DQNagent = rlDQNAgent(observationInfo,actionInfo, ...
initializationOptions);Set the agent options.
DQNagent.AgentOptions.DiscountFactor = 1; DQNagent.AgentOptions.EpsilonGreedyExploration.EpsilonDecay = 1e-4; DQNagent.AgentOptions.MaxMiniBatchPerEpoch = 10;
Train Agent
Once you define the agent and the environment, you can use the train (Reinforcement Learning Toolbox) function to train the DQN agent. To configure the options for training, use rlTrainingOptions (Reinforcement Learning Toolbox).
trainingOptions = rlTrainingOptions;
Set the maximum number of episodes to train to 4000. If you use a constant return function, training takes less time, so reduce the number of episodes.
trainingOptions.MaxEpisodes = 4000;
Set the window length for averaging the rewards to 1,000. ScoreAveragingWindowLength is the number of episodes included in the average.
trainingOptions.ScoreAveragingWindowLength = 1e3;
Train the agent. The Reinforcement Learning Episode Manager is opened. When the sparseReward function (see Local Functions) is selected as the reward from the environment, the training time is approximately five minutes. If you set do_train to false, a network pretrained using the sparserReward function is loaded.
do_train = false; if do_train % Train the agent trainingStats = train(DQNagent,gbwmEnvironment,trainingOptions); else load('trainedAgent'); end
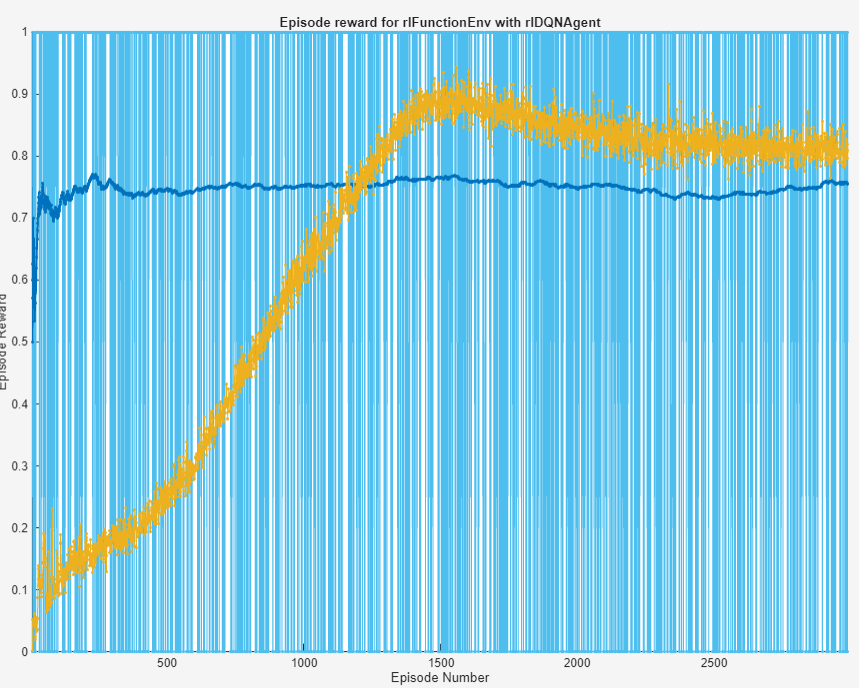
Simulate Using Agent
Simulate 1000 scenarios taking the actions of the training agent DQNagent. Use rlSimulationOptions (Reinforcement Learning Toolbox) to set the number of simulations.
numSimulations = 1e3; simulationOptions = rlSimulationOptions(NumSimulations=numSimulations);
Simulate the trained agent using sim (Reinforcement Learning Toolbox).
experience = sim(gbwmEnvironment,DQNagent,simulationOptions);
Obtain the wealth observations per period and the rewards at the end of the episode. These rewards show whether the target wealth is achieved by the end of the investment horizon or not.
% Retrieve simulation information cumulativeReward = 0; wealthSimulation = zeros(finalTimePeriod+1,numSimulations); for i = 1:numSimulations cumulativeReward = cumulativeReward+... experience(i).Reward.Data(end); wealthSimulation(:,i) =... squeeze(experience(i).Observation.obs1.Data(1,1,:)); end % Transform wealth levels from the simulation to the original space. wealthSimulation = wealthSimulation*(WMax-WMin) + WMin;
Calculate an empirical approximation of the success rate of the agent's policy.
% Compute the testing success probability.
successProb = cumulativeReward/numSimulationssuccessProb = 0.7910
For this problem, the approximated GBWM optimal probability is 79.1%. This problem can be solved using a dynamic optimization approach as in Dynamic Portfolio Allocation in Goal-Based Wealth Management for Multiple Time Periods (Financial Toolbox), where the optimal probability is 79.28%. Since both examples use a Brownian motion to simulate the wealth evolution, the solution from the dynamic programming approach is the closest to the theoretical optimum. Given that the probability obtained by the RL agent is 79.1%, it means that the policy obtained by the RL agent is close to the theoretical optimum as well.
% Plot the asset allocation for one simulation simNumber =650; figure tiledlayout(2,1) % Tile 1: Wealth progress nexttile plot(0:finalTimePeriod,wealthSimulation(:,simNumber)) hold on yline(targetWealth,'--k',LineWidth=2) title('Wealth Evolution') xlabel('Time Period') ylabel('Wealth Level') hold off % Tile 2: Optimal action nexttile bar(0:finalTimePeriod-1, ... pwgt(:,experience(simNumber).Action.act1.Data)','stacked') title('Portfolio Evolution') xlabel('Time Period') ylabel('Portfolio Weights') legend('Low risk asset','Medium risk asset','High risk asset')

Using the sparse reward function, in simulation number 650 at time the wealth drops below the initial wealth level. This drives the agent to choose a more conservative approach. Since the wealth is not recovering as fast as needed to achieve the goal by the end of the investment horizon, at the agent chooses the most aggressive portfolio. By choosing an aggressive portfolio, the expected return increases at the cost of increasing the volatility. This extreme choice made by the agent is the result of the objective function not taking into account possible losses. The reward is only obtained if the goal is met, so an all-or-nothing strategy makes sense towards the end of the investment period. If the investor also wants to take their losses into account, they can add those losses into the reward function to penalize cases where the losses become too high. The entire agent's optimal strategy is illustrated in Heatmap of Optimal Policy.
Using the previous code, simNumber=303 shows the following results. As with simulation 771, these results come from a model trained with the sparse reward function.
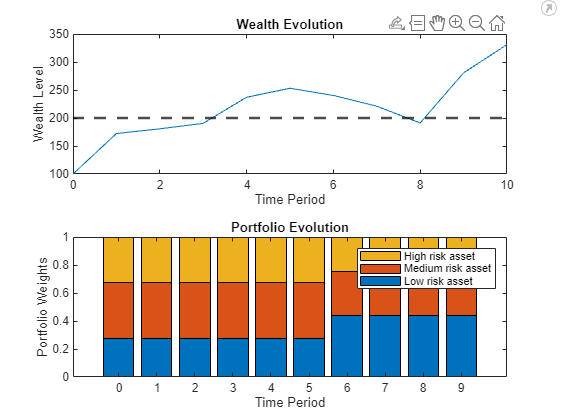
From time to the wealth evolution is favorable so the action remains the same. At , the wealth drops so the agent chooses a more conservative approach in this time period. Since the wealth level does not recover greatly as time passes, the agent holds the conservative approach to decrease risk all the way until the end of the investment horizon. These results show how the agent incorporates not only the wealth level but also the time period information into its decisions. Notice that even when the wealth level at goes well above the target goal, the action is still conservative. This is because as time progresses, the agent needs to decrease the risk level to ensure that the goal is attained by the end.
Heatmap of Optimal Policy
Compute a set of possible wealth levels using 25 logarithmically spaced points between the maximum and minimum. Then, create a grid of possible observations using these levels and the time steps.
% Logarithmic wealth levels numWealthPoints = 25; wealthLevel = logspace(log10(WMin),log10(WMax),numWealthPoints); % Possible observations wVar = repmat(wealthLevel',finalTimePeriod,1); tVar = repelem((0:finalTimePeriod-1)',numWealthPoints); % Transform wealth to [0,1] space to feed to agent wVarAgent = (wVar-WMin)/(WMax-WMin); % Create a grid for agent to evaluate obs = zeros(2,1,finalTimePeriod*numWealthPoints); obs(:,1,:) = [wVarAgent';tVar'];
Compute the action generated by the trained agent for each of the observations in the grid.
% Action for each observation
actions = getAction(DQNagent,obs);
actions = squeeze(actions{1});Use heatmap to visualize the action taken by the trained agent for each of the observations.
% Create heatmap figure T = table(wVar,tVar,actions, ... VariableNames={'WealthLevel','TimePeriod','Action'}); heatmap(T,'TimePeriod','WealthLevel',ColorVariable='Action', ... ColorMethod='none')
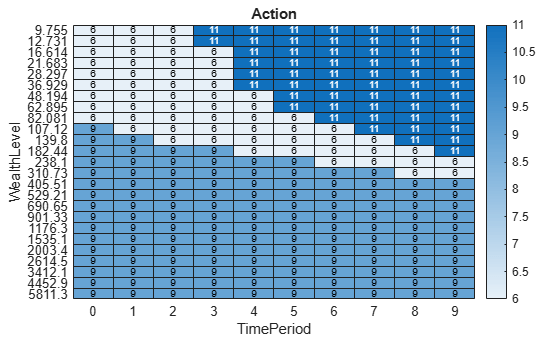
This figure shows the actions chosen by the agent for different wealth levels and time periods. The numbers inside the grid represent the action taken by the agent at each state. In this example, using the sparse reward function, the trained agent only invests in portfolio #6, #9, or #11, where the higher the portfolio number, the more aggressive the portfolio is. In this policy, the aggressiveness of the portfolio increases as time gets closer to the end of the investment horizon. Notice that only at the beginning of the investment horizon, it is more likely that the agent choose the most conservative portfolio, especially if the wealth is below the wealth that would be achieved by the constant reward assumption (see section Constant Return Reward). However, if the wealth is very low close to the end of the investment horizon, then the agent needs to increase the risk to improve the probability of attaining the desired goal. This choice increases the expected return, even at the cost of increasing the volatility. The extreme choice made by the agent is the result of the objective function not taking into account possible losses. If the investor also wants to take their losses into account, they can add those losses into the objective and reward function to penalize cases where the losses become too high.
References
[1] Das, S. R., and S. Varma. "Dynamic Goals-Based Wealth Management Using Reinforcement Learning." Journal Of Investment Management, 18 No.2 (2020): 1-20.
Local Functions
function [initialObservation,loggedSignals] =... myResetFunction(initialWealth,WMin,WMax) % Reset function to set wealth and time period to initial state. % Transform wealth to [0,1] space initialWealth = (initialWealth-WMin)/(WMax-WMin); % Store initial state in loggedSignals loggedSignals.Wealth = initialWealth; loggedSignals.TimePeriod = 0; % Return initial observation initialObservation = [initialWealth; loggedSignals.TimePeriod]; end function [nextObservation,reward,isDone,loggedSignals] =... myStepFunction(action,loggedSignals,prsk,pret,finalTimePeriod, ... rewardFunction,WMin,WMax) % Step function to compute the wealth obtained from investing in % the portfolio specified by the action. The function also % computes the reward obtained by the current action and checks if % episode is done. % Get current wealth and time period W = loggedSignals.Wealth; t = loggedSignals.TimePeriod; % Transform wealth to original space W = W*(WMax-WMin) + WMin; % Get risk and return levels for current action mu = pret(action,1); sigma = prsk(action,1); % Compute next wealth Z = randn; W = W*exp(mu-(sigma^2/2)+sigma*Z); % Return wealth to [0,1] space W = (W-WMin)/(WMax-WMin); % Store next state in LoggedSignal loggedSignals.Wealth = W; loggedSignals.TimePeriod = t+1; % Return observation nextObservation = [loggedSignals.Wealth;loggedSignals.TimePeriod]; % Compute reward reward = rewardFunction(loggedSignals); % Check if episode has ended if loggedSignals.TimePeriod >= finalTimePeriod isDone = true; else isDone = false; end end function reward = sparseReward(loggedSignals,finalTimePeriod, ... targetWealth,WMin,WMax) % Function that computes the reward obtained in the current state % following the sparse rule: % R(W,t) = 1 if t >= T and W >= targetWealth % 0 if t < T or W < targetWealth % Transform wealth to original space W = loggedSignals.Wealth*(WMax-WMin) + WMin; if loggedSignals.TimePeriod >= finalTimePeriod && W >= targetWealth reward = 1; else reward = 0; end end function reward = constantReturnReward(loggedSignals, ... initialWealth,finalTimePeriod,targetWealth,constantReturn) % Function that computes the reward obtained in the current state % following the constant return rule: % R(W,t) = 1 if t >= T and W >= targetWealth % 0.1 if t < T and W >= W0 * (1+r)^t % 0 o.w. % Get current state t = loggedSignals.TimePeriod; W = loggedSignals.Wealth; % Transform wealth to original space W = W*(WMax-WMin) + WMin; % Compute reward if t >= finalTimePeriod && W >= targetWealth reward = 1; elseif W >= initialWealth*(1+constantReturn)^t reward = 0.1; else reward = 0; end end
See Also
Portfolio (Financial Toolbox) | estimateFrontier (Financial Toolbox)
Topics
- Single Period Goal-Based Wealth Management (Financial Toolbox)
- Dynamic Portfolio Allocation in Goal-Based Wealth Management for Multiple Time Periods (Financial Toolbox)