distributionScores
Syntax
Description
Add-On Required: This feature requires the AI Verification Library for Deep Learning Toolbox add-on.
scores = distributionScores(discriminator,X)X
using the method you specify in the Method property of
discriminator. You can use the scores to separate data into
in-distribution (ID) and out-of-distribution (OOD) data sets. For example, you can classify
any observation with distribution confidence score less than or equal to the
Threshold property of discriminator as OOD. For
more information about how the software computes the distribution confidence scores, see
Distribution Confidence Scores.
scores = distributionScores(discriminator,X1,...,XN)
scores = distributionScores(___,VerbosityLevel=
also specifies the verbosity level.level)
Examples
Load a pretrained classification network.
load('digitsClassificationMLPNetwork.mat');Load ID data. Convert the data to a dlarray object.
XID = digitTrain4DArrayData;
XID = dlarray(XID,"SSCB");Modify the ID training data to create an OOD set.
XOOD = XID.*0.3 + 0.1;
Create a discriminator using the networkDistributionDiscriminator function.
method = "baseline";
discriminator = networkDistributionDiscriminator(net,XID,XOOD,method)discriminator =
BaselineDistributionDiscriminator with properties:
Method: "baseline"
Network: [1×1 dlnetwork]
Threshold: 0.9743
The discriminator object contains a threshold for separating the ID and OOD confidence scores.
Use the distributionScores function to find the distribution scores for the ID and OOD data. You can use the distribution confidence scores to separate the data into ID and OOD. The algorithm the software uses to compute the scores is set when you create the discriminator. In this example, the software computes the scores using the baseline method.
scoresID = distributionScores(discriminator,XID); scoresOOD = distributionScores(discriminator,XOOD);
Plot the distribution confidence scores for the ID and OOD data. Add the threshold separating the ID and OOD confidence scores.
figure histogram(scoresID,BinWidth=0.02) hold on histogram(scoresOOD,BinWidth=0.02) xline(discriminator.Threshold) legend(["In-distribution scores","Out-of-distribution scores","Threshold"],Location="northwest") xlabel("Distribution Confidence Scores") ylabel("Frequency") hold off

Load a pretrained classification network.
load("digitsClassificationMLPNetwork.mat");Load ID data and convert the data to a dlarray object.
XID = digitTrain4DArrayData;
XID = dlarray(XID,"SSCB");Modify the ID training data to create an OOD set.
XOOD = XID.*0.3 + 0.1;
Create a discriminator.
method = "baseline";
discriminator = networkDistributionDiscriminator(net,XID,XOOD,method);Use the distributionScores function to find the distribution scores for the ID and OOD data. You can use the distribution scores to separate the data into ID and OOD.
scoresID = distributionScores(discriminator,XID); scoresOOD = distributionScores(discriminator,XOOD);
Use rocmetrics to plot a ROC curve to show how well the model performs at separating the data into ID and OOD.
labels = [
repelem("In-distribution",numel(scoresID)), ...
repelem("Out-of-distribution",numel(scoresOOD))];
scores = [scoresID',scoresOOD'];
rocObj = rocmetrics(labels,scores,"In-distribution");
figure
plot(rocObj)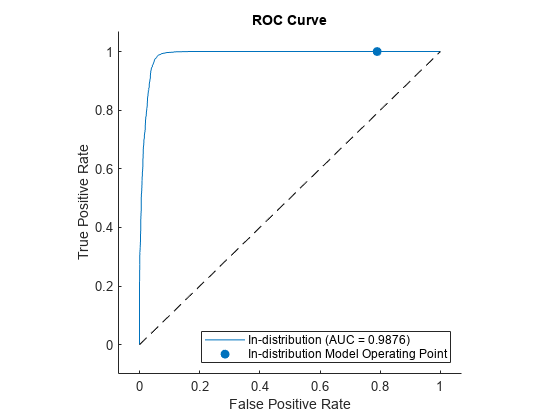
Input Arguments
Output Arguments
More About
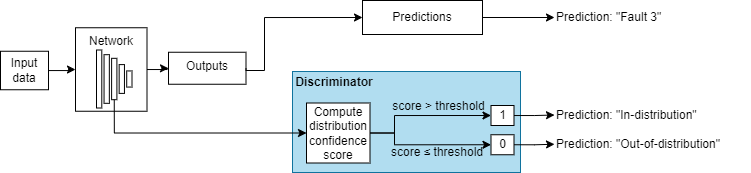
OOD data detection is a technique for assessing whether the inputs to a network are OOD. For methods that you apply after training, you can construct a discriminator which acts as an additional output of the trained network that classifies an observation as ID or OOD.
The discriminator works by finding a distribution confidence score for an input. You can then specify a threshold. If the score is less than or equal to that threshold, then the input is OOD. Two groups of metrics for computing distribution confidence scores are softmax-based and density-based methods. Softmax-based methods use the softmax layer to compute the scores. Density-based methods use the outputs of layers that you specify to compute the scores. For more information about how to compute distribution confidence scores, see Distribution Confidence Scores.
These images show how a discriminator acts as an additional output of a trained neural network.
Example Data Discriminators
| Example of Softmax-Based Discriminator | Example of Density-Based Discriminator |
|---|---|
|
For more information, see Softmax-Based Methods. |
For more information, see Density-Based Methods. |

References
[5] Jingkang Yang, Kaiyang Zhou, Yixuan Li, and Ziwei Liu, “Generalized Out-of-Distribution Detection: A Survey” August 3, 2022, http://arxiv.org/abs/2110.11334.
[6] Lee, Kimin, Kibok Lee, Honglak Lee, and Jinwoo Shin. “A Simple Unified Framework for Detecting Out-of-Distribution Samples and Adversarial Attacks.” arXiv, October 27, 2018. http://arxiv.org/abs/1807.03888.
Extended Capabilities
Version History
Introduced in R2023aSee Also
networkDistributionDiscriminator | isInNetworkDistribution | rocmetrics | minibatchqueue | coder.loadNetworkDistributionDiscriminator
Topics
- Verification of Neural Networks
- Out-of-Distribution Detection for Deep Neural Networks
- Out-of-Distribution Data Discriminator for YOLO v4 Object Detector
- Out-of-Distribution Detection for LSTM Document Classifier
- Out-of-Distribution Detection for BERT Document Classifier
- Compare Deep Learning Models Using ROC Curves