Keyword Spotting in Audio Using MFCC and LSTM Networks on NVIDIA Embedded Hardware from Simulink
This example shows how to deploy a Simulink® model on the NVIDIA® Jetson™ board for keyword spotting in audio data. This example identifies the keyword(YES) in the input audio data using Mel Frequency Cepstral Coefficients (MFCC) and a pretrained Bidirectional Long Short-Term Memory (BiLSTM) network.
Prerequisites
Target Board Requirements
NVIDIA Jetson embedded platform.
Ethernet crossover cable to connect the target board and host PC (if you cannot connect the target board to a local network).
USB audio device that supports 16kHz audio input connected to the target.
USB headphone connected to the target.
NVIDIA CUDA® toolkit and driver.
NVIDIA cuDNN library on the target.
Environment variables on the target for the compilers and libraries. For more information, see Install and Setup Prerequisites for NVIDIA Boards.
Connect to NVIDIA Hardware
The MATLAB® Coder™ support package for NVIDIA Jetson and NVIDIA DRIVE Platforms uses an SSH connection over TCP/IP to execute commands while building and running the generated CUDA code on the Jetson platforms. Connect the target platform to the same network as the host computer or use an Ethernet crossover cable to connect the board directly to the host computer. For information on how to set up and configure your board, see NVIDIA documentation.
To communicate with the NVIDIA hardware, create a live hardware connection object by using the jetson function. You must know the host name or IP address, user name, and password of the target board to create a live hardware connection object. For example, when connecting to the target board for the first time, create a live object for Jetson hardware by using the command:
hwobj = jetson('jetson-tx2-name','ubuntu','ubuntu');
Verify GPU Environment on Target Board
To verify that the compilers and libraries necessary for running this example are set up correctly, use the coder.checkGpuInstall (GPU Coder) function.
envCfg = coder.gpuEnvConfig('jetson'); envCfg.DeepLibTarget = 'cudnn'; envCfg.DeepCodegen = 1; envCfg.Quiet = 1; envCfg.HardwareObject = hwobj; coder.checkGpuInstall(envCfg);
Identify the Audio Devices Connected to Target Board
To find the list of audio capture devices connected to the target, use the listAudioDevices function. The output contains the Device IDs according to ALSA standards, the bit-depths, and the sample rates supported by the devices.
captureDeviceList = listAudioDevices(hwobj,'capture')

Similarly, to find the list of audio playback devices connected to the target, run the command.
playbackDeviceList = listAudioDevices(hwobj,'playback')

Audio Feature Extraction for the Deep Learning Classification
Keyword spotting (KWS) is an essential component of voice-assist technologies, where the user speaks a predefined keyword to wake-up a system before speaking a complete command or query to the device. The Bi-LSTM network used for keyword spotting takes feature sequences of mel-frequency cepstral coefficients (MFCC) generated from the input audio data. To extract MFCC coefficients from the audio data captured through the microphone, use the audioFeatureExtractor (Audio Toolbox) from Audio Toolbox™. Generate a MATLAB function to extracts features from the audio input using generateMATLABFunction method of the audioFeatureExtractor object. The generated function will be used in a MATLAB Function block during code generation and deployment.
WindowLength = 512; OverlapLength = 384; afe = audioFeatureExtractor('SampleRate',16000, ... 'Window',hann(WindowLength,'periodic'), ... 'OverlapLength',OverlapLength, ... 'mfcc',true,'mfccDelta', true, ... 'mfccDeltaDelta',true); setExtractorParams(afe,'mfcc','NumCoeffs',13);
Running the above command creates an audioFeatureExtractor object
generateMATLABFunction(afe,'computeMFCCFeatures');
A MATLAB Function block in the model will call the generated 'computeMFCCFeatures' function to extract features from the audio input. For information about generating MFCC coefficients and train an LSTM network, see Keyword Spotting in Noise Using MFCC and LSTM Networks (Audio Toolbox). For information about feature extraction in deep learning applications using audio inputs, see Feature Extraction (Audio Toolbox).
Simulink Model for Deep Learning Classification
The Simulink model captures real-time audio data using a USB based microphone. From the audio data, feature sequences of mel-frequency cepstral coefficients (MFCC) are extracted. The extracted feature sequences are used to predict the location of the keyword (YES) on a pre-trained BiLSTM network (kwsNet.mat).
open_system('exLSTM');

The model uses the following blocks from for capturing audio data:
1. NVIDIA ALSA Audio Capture block to capture real-time audio using a microphone connected to the target.
2. NVIDIA Audio File Read block to capture audio using a prerecorded audio file. The audio input source can be routed using the Manual switch block.
To use the microphone connected to the target to capture real-time audio, double-click the NVIDIA ALSA Audio Capture block to set the block parameters. Set the Device name, Device Bit depth, Number of channels (C), Audio sampling frequency, and Samples per frame(N) of the outgoing audio data.
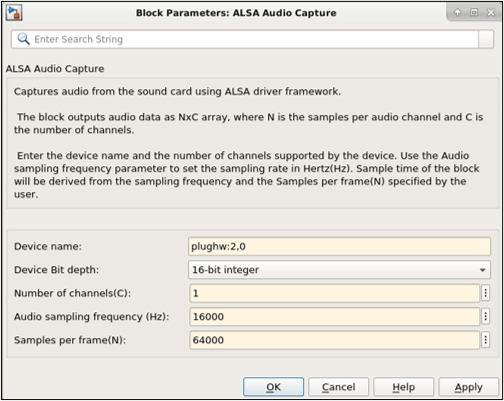
The Device name of the audio device must be set according to ALSA standards as shown in the above diagram. The Device Bit Depth, Number of channels and Audio sampling frequency must be of the supported values by the device. All the above values can be obtained from the listAudioDevices as mentioned previously. Samples per frame can be any positive integer.
To use prerecorded audio, double-click the NVIDIA Audio File Read block to set the block parameters. Set the File name, Samples per audio channel (N) of the outgoing audio data. The value of Samples per audio channel must be equal to the value of Samples per frame parameter of the NVIDIA ALSA Audio Capture block.
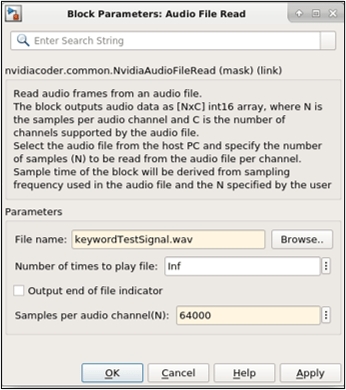
NOTE: The Samples per frame of the NVIDIA ALSA Audio Capture block and Samples per audio channel of the NVIDIA Audio File Read block must be the same value.
The extractKWSFeatures function block extracts a matrix of feature vectors. The feature vector contains the Mel-Frequency Cepstral Coefficients of the incoming audio. Each feature vector corresponds to the Mel-Frequency Cepstral Coefficients (MFCC) over a window of 128 samples. This block calls computeMFCCFeatures function, which is computed using the afe.
function featuresOut = extractKWSFeatures(audioIn)
%% Normalize the audio Input audioIn_double =
normalize(double(audioIn)); normAudio =
rescale(double(audioIn_double),-1,1);
M = [ -54.1156 5.0504 0.0032 0.8294 -0.4580 ... 0.1252 -0.3678 0.1088 -0.2502 0.0969 -0.3487 0.0167 ... -0.2754 -0.1579 0.0103 0.0017 0.0022 -0.0005 ... 0.0014 -0.0010 0.0010 -0.0005 0.0005 -0.0009 0.0002 ... -0.0006 -0.0012 -0.0002 0.0001 0.0000 0.0001 0.0001 ... 0.0001 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000];
S = [102.8084 3.6461 2.1506 1.6023 1.4204 1.1928 1.0268 ... 0.8682 0.7725 0.7044 0.6697 0.6169 0.5677 25.1409 ... 0.7279 0.4663 0.3530 0.3033 0.2672 0.2300 0.2060 ... 0.1915 0.1755 0.1647 0.1567 0.1471 11.6758 0.2938 ... 0.1928 0.1499 0.1291 0.1163 0.1025 0.0929 0.0874 ... 0.0803 0.0756 0.0720 0.0679];
features = computeMFCCFeatures(normAudio);
for i=1:size(features,1) features(i,:) = (features(i,:) - M)./S; end
featuresOut = features';
The generated feature vectors are given as inputs to the Stateful Classify (Deep Learning Toolbox) block from Deep learning toolbox. The block takes a pre-trained deep learning network kwsNet from a MAT-file as it is set as below.
set_param('exLSTM/Stateful Classify','Network','Network from MAT-file'); set_param('exLSTM/Stateful Classify','NetworkFilePath',fullfile(pwd,'kwsNet.mat')); set_param('exLSTM/Stateful Classify','Classification','on'); set_param('exLSTM/Stateful Classify','Predictions','off');
The block outputs a categorical vector of the size of number of feature vectors which signifies whether the window of the audio data corresponding to the feature vector contains the keyword (YES) or not. The applyMask function block takes in the output class vector from the Stateful Classify block and generates a mask vector. This mask vector is applied on the input audio and sets the chunks of the audio containing the keyword to 0. The resulting output audio data is resampled to a sampling frequency supported by the usb audio headphones connected to the target, using the Upsample (DSP System Toolbox) block. The upsampling factor (three, by default) depends on the Sampling rates supported by the USB-headphones connected to the target. The resulting audio signal is given as input to the NVIDIA ALSA Audio Playback block. Double-click the block to set the block parameters as shown below.
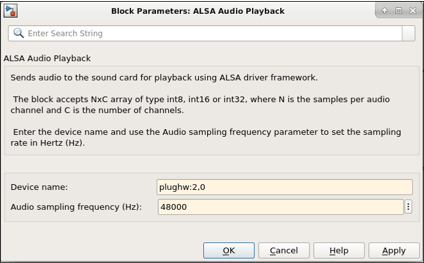
Configure the Model for Deployment
To generate CUDA code, these model configuration parameters must be set:
set_param('exLSTM','TargetLang','C++'); set_param('exLSTM','GenerateGPUCode','CUDA'); set_param('exLSTM', 'DLTargetLibrary','cudnn');
For more information on generating GPU Code in Simulink, see Code Generation from Simulink Models with GPU Coder (GPU Coder).
Enable MAT-file logging in the model to visualize plot the difference between input and output. This is an optional setting to verify the model is working correctly.
set_param('exLSTM','CodeInterfacePackaging','Nonreusable function'); set_param('exLSTM','MatFileLogging','on');
Open the Configuration Parameters dialog box, Hardware Implementation pane. Select Hardware board as NVIDIA Jetson (or NVIDIA Drive).

On the Target hardware resources section, enter the Device Address, Username, and Password of your NVIDIA Jetson target board.

Set the Build action, Build directory, and Display as shown. The Display represents the display environment and allows output to be displayed to the device corresponding to the environment.

Click Apply and OK.
Generate Code and Deploy Model on Target Board
Open the Hardware tab on the Simulink Editor. Select Build, Deploy & Start to generate CUDA code and deploy the code on the hardware.
Visualize the Difference Between Input and Output
The application generates MAT-files when MAT-file logging is enabled in the model before deployment. Copy the MAT-files generated in the build directory on the target and plot the input and output audio data.
getFile(hwobj,'~/exLSTM*.mat');
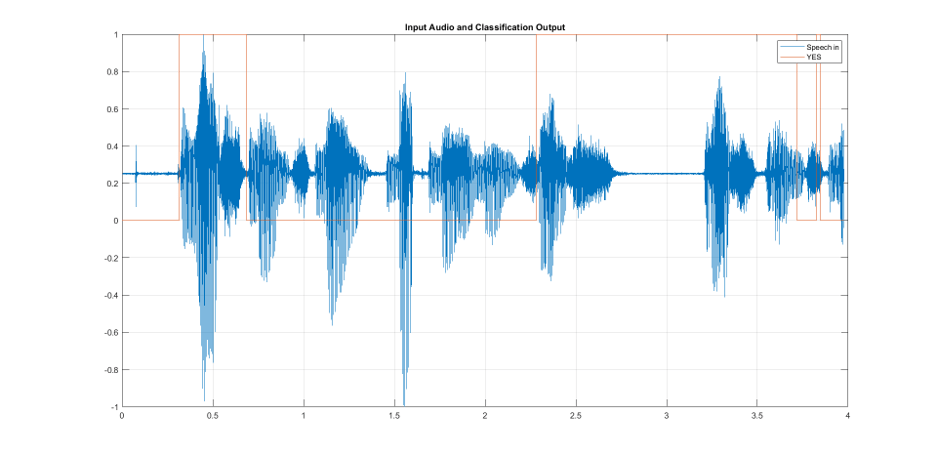
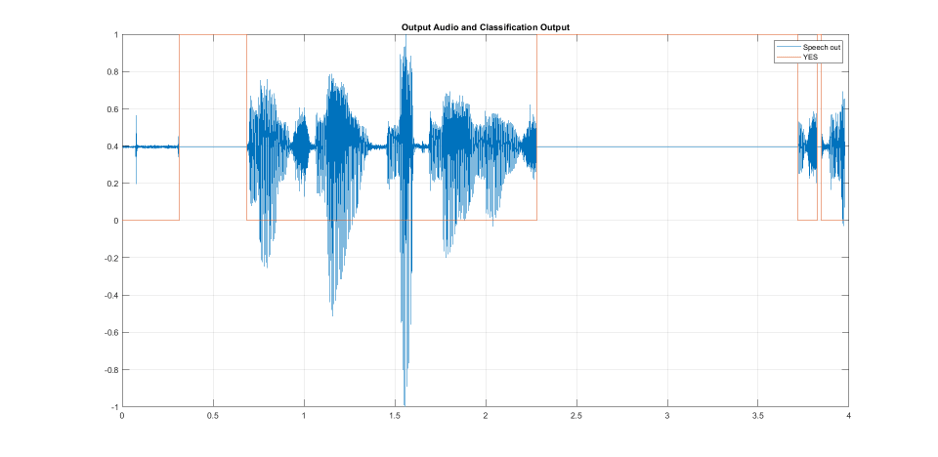
A sample input audio data captured through the microphone contains the following phrase is spoken during the duration of one sample time of the model : "yes means no but means yes yes means no". Plot the input audio signal (Speech in), prediction signal (YES), and output audio signal (Speech out).
visualizeClassificationResults;
Stop Application
To stop the application on the target, use the stopModel method of the hardware object.
stopModel(hwobj,'exLSTM');
Close Model
Run close_system to close the model.
close_system('exLSTM',0);
Things to Try
This example can also be run by generating C/C++ code. For generating C++ code, the DLTargetLibrary must be set as ARM Compute.
set_param('exLSTM','GenerateGPUCode','off'); set_param('exLSTM','DLTargetLibrary','ARM Compute'); set_param('exLSTM','DLArmComputeArch','armv7');
For this, ARM® compute library must be installed on the target.
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)