testcholdout
Compare predictive accuracies of two classification models
Syntax
Description
testcholdout statistically assesses
the accuracies of two classification models. The function first compares
their predicted labels against the true labels, and then it detects
whether the difference between the misclassification rates is statistically
significant.
You can assess whether the accuracies of the classification
models are different, or whether one classification model performs
better than another. testcholdout can conduct several McNemar test variations,
including the asymptotic test, the exact-conditional test, and the
mid-p-value test. For cost-sensitive assessment, available
tests include a chi-square test (requires an Optimization Toolbox™ license)
and a likelihood ratio test.
h = testcholdout(YHat1,YHat2,Y)YHat1 and YHat2 have
equal accuracy for predicting the true class labels Y.
The alternative hypothesis is that the labels have unequal accuracy.
h = 1 indicates to reject
the null hypothesis at the 5% significance level. h = 0 indicates
to not reject the null hypothesis at 5% level.
h = testcholdout(YHat1,YHat2,Y,Name,Value)Name,Value pair arguments. For example,
you can specify the type of alternative hypothesis, specify the type
of test, or supply a cost matrix.
Examples
Input Arguments
Name-Value Arguments
Output Arguments
More About
McNemar Tests are hypothesis tests that compare two population proportions while addressing the issues resulting from two dependent, matched-pair samples.
One way to compare the predictive accuracies of two classification models is:
Partition the data into training and test sets.
Train both classification models using the training set.
Predict class labels using the test set.
Summarize the results in a two-by-two table similar to this figure.
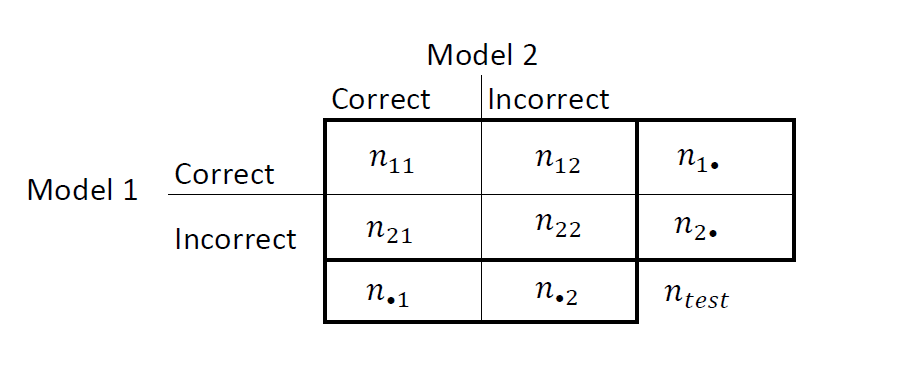
nii are the number of concordant pairs, that is, the number of observations that both models classify the same way (correctly or incorrectly). nij, i ≠ j, are the number of discordant pairs, that is, the number of observations that models classify differently (correctly or incorrectly).
The misclassification rates for Models 1 and 2 are and , respectively. A two-sided test for comparing the accuracy of the two models is
The null hypothesis suggests that the population exhibits marginal homogeneity, which reduces the null hypothesis to Also, under the null hypothesis, N12 ~ Binomial(n12 + n21,0.5) [1].
These facts are the basis for the available McNemar test variants: the asymptotic, exact-conditional, and mid-p-value McNemar tests. The definitions that follow summarize the available variants.
Asymptotic — The asymptotic McNemar test statistics and rejection regions (for significance level α) are:
For one-sided tests, the test statistic is
If where Φ is the standard Gaussian cdf, then reject H0.
For two-sided tests, the test statistic is
If , where is the χm2 cdf evaluated at x, then reject H0.
The asymptotic test requires large-sample theory, specifically, the Gaussian approximation to the binomial distribution.
The total number of discordant pairs, , must be greater than 10 ([1], Ch. 10.1.4).
In general, asymptotic tests do not guarantee nominal coverage. The observed probability of falsely rejecting the null hypothesis can exceed α, as suggested in simulation studies in [2]. However, the asymptotic McNemar test performs well in terms of statistical power.
Exact-Conditional — The exact-conditional McNemar test statistics and rejection regions (for significance level α) are ([4], [5]):
For one-sided tests, the test statistic is
If , where is the binomial cdf with sample size n and success probability p evaluated at x, then reject H0.
For two-sided tests, the test statistic is
If , then reject H0.
The exact-conditional test always attains nominal coverage. Simulation studies in [2] suggest that the test is conservative, and then show that the test lacks statistical power compared to other variants. For small or highly discrete test samples, consider using the mid-p-value test ([1], Ch. 3.6.3).
Mid-p-value test — The mid-p-value McNemar test statistics and rejection regions (for significance level α) are ([3]):
For one-sided tests, the test statistic is
If , where and are the binomial cdf and pdf, respectively, with sample size n and success probability p evaluated at x, then reject H0.
For two-sided tests, the test statistic is
If , then reject H0.
The mid-p-value test addresses the over-conservative behavior of the exact-conditional test. The simulation studies in [2] demonstrate that this test attains nominal coverage, and has good statistical power.
Tips
It is a good practice to obtain predicted class labels by passing any trained classification model and new predictor data to the
predictmethod. For example, for predicted labels from an SVM model, seepredict.Cost-sensitive tests perform numerical optimization, which requires additional computational resources. The likelihood ratio test conducts numerical optimization indirectly by finding the root of a Lagrange multiplier in an interval. For some data sets, if the root lies close to the boundaries of the interval, then the method can fail. Therefore, if you have an Optimization Toolbox license, consider conducting the cost-sensitive chi-square test instead. For more details, see
CostTestand Cost-Sensitive Testing.
References
Version History
Introduced in R2015a