friedman
Friedman’s test
Syntax
Description
p = friedman(x,reps)friedman tests the null hypothesis
that the column effects are all the same against the alternative that they are not all the
same. Friedman's test provides an analysis that is similar to a two-way ANOVA without
interactions. For more information, see Friedman’s Test.
p = friedman(x,reps,displayopt)displayopt is 'on' (default)
and suppresses the display when displayopt is 'off'.
Examples
This example shows how to test for column effects in a two-way layout using Friedman's test.
Load the sample data.
load popcorn
popcornpopcorn = 6×3
5.5000 4.5000 3.5000
5.5000 4.5000 4.0000
6.0000 4.0000 3.0000
6.5000 5.0000 4.0000
7.0000 5.5000 5.0000
7.0000 5.0000 4.5000
This data comes from a study of popcorn brands and popper type (Hogg 1987). The columns of the matrix popcorn are brands (Gourmet, National, and Generic). The rows are popper type (Oil and Air). The study popped a batch of each brand three times with each popper. The values are the yield in cups of popped popcorn.
Use Friedman's test to determine whether the popcorn brand affects the yield of popcorn.
p = friedman(popcorn,3)
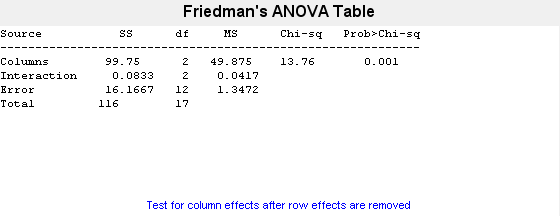
p = 0.0010
The small value of p = 0.001 indicates the popcorn brand affects the yield of popcorn.
Input Arguments
Output Arguments
More About
References
[1] Hogg, R. V., and J. Ledolter. Engineering Statistics. New York: MacMillan, 1987.
[2] Hollander, M., and D. A. Wolfe. Nonparametric Statistical Methods. Hoboken, NJ: John Wiley & Sons, Inc., 1999.
Version History
Introduced before R2006a