coxphfit
Cox proportional hazards regression
Description
b = coxphfit(X,T)b, of coefficient
estimates for a Cox proportional hazards
regression of the observed responses T on
the predictors X, where T is
either an n-by-1 vector or an n-by-2
matrix, and X is an n-by-p matrix.
The model does not include a constant term, and X cannot
contain a column of 1s.
b = coxphfit(X,T,Name,Value)Name,Value pair arguments.
[ also returns the loglikelihood, b,logl,H,stats]
= coxphfit(___)logl,
a structure, stats, that contains additional statistics,
and a two-column matrix, H, that contains the T values
in the first column and the estimated baseline cumulative hazard,
in the second column. You can use any of the input arguments in the
previous syntaxes.
Examples
Load the sample data.
load('lightbulb.mat');The first column of the light bulb data has the lifetime (in hours) of two different types of bulbs. The second column has the binary variable indicating whether the bulb is fluorescent or incandescent. 0 indicates that the bulb is fluorescent, and 1 indicates that it is incandescent. The third column contains the censorship information, where 0 indicates the bulb was observed until failure, and 1 indicates the bulb was censored.
Fit a Cox proportional hazards model for the lifetime of the light bulbs, also accounting for censoring. The predictor variable is the type of bulb.
b = coxphfit(lightbulb(:,2),lightbulb(:,1), ... 'Censoring',lightbulb(:,3))
b = 4.7262
The estimate of the hazard ratio is = 112.8646. This means that the hazard for the incandescent bulbs is 112.86 times the hazard for the fluorescent bulbs.
Load the sample data.
load('lightbulb.mat');The first column of the data has the lifetime (in hours) of two types of bulbs. The second column has the binary variable indicating whether the bulb is fluorescent or incandescent. 1 indicates that the bulb is fluorescent and 0 indicates that it is incandescent. The third column contains the censorship information, where 0 indicates the bulb is observed until failure, and 1 indicates the item (bulb) is censored.
Fit a Cox proportional hazards model, also accounting for censoring. The predictor variable is the type of bulb.
b = coxphfit(lightbulb(:,2),lightbulb(:,1),... 'Censoring',lightbulb(:,3))
b = 4.7262
Display the default control parameters for the algorithm coxphfit uses to estimate the coefficients.
statset('coxphfit')ans = struct with fields:
Display: 'off'
MaxFunEvals: 200
MaxIter: 100
TolBnd: []
TolFun: 1.0000e-08
TolTypeFun: []
TolX: 1.0000e-08
TolTypeX: []
GradObj: []
Jacobian: []
DerivStep: []
FunValCheck: []
Robust: []
RobustWgtFun: []
WgtFun: []
Tune: []
UseParallel: []
UseSubstreams: []
Streams: {}
OutputFcn: []
Save the options under a different name and change how the results will be displayed and the maximum number of iterations, Display and MaxIter.
coxphopt = statset('coxphfit'); coxphopt.Display = 'final'; coxphopt.MaxIter = 50;
Run coxphfit with the new algorithm parameters.
b = coxphfit(lightbulb(:,2),lightbulb(:,1),... 'Censoring',lightbulb(:,3),'Options',coxphopt)
Successful convergence: Norm of gradient less than OPTIONS.TolFun
b = 4.7262
coxphfit displays a report on the final iteration. Changing the maximum number of iterations did not affect the coefficient estimate.
Generate Weibull data depending on predictor X.
rng('default') % for reproducibility X = 4*rand(100,1); A = 50*exp(-0.5*X); B = 2; y = wblrnd(A,B);
The response values are generated from a Weibull distribution with a scale parameter depending on the predictor variable X and a shape parameter of 2.
Fit a Cox proportional hazards model.
[b,logL,H,stats] = coxphfit(X,y); [b logL]
ans = 1×2
0.9409 -331.1479
The coefficient estimate is 0.9409 and the log likelihood value is –331.1479.
Request the model statistics.
stats
stats = struct with fields:
covb: 0.0158
beta: 0.9409
se: 0.1256
z: 7.4889
p: 6.9462e-14
csres: [100×1 double]
devres: [100×1 double]
martres: [100×1 double]
schres: [100×1 double]
sschres: [100×1 double]
scores: [100×1 double]
sscores: [100×1 double]
LikelihoodRatioTestP: 6.6613e-16
The covariance matrix of the coefficient estimates, covb, contains only one value, which is equal to the variance of the coefficient estimate in this example. The coefficient estimate, beta, is the same as b and is equal to 0.9409. The standard error of the coefficient estimate, se, is 0.1256, which is the square root of the variance 0.0158. The -statistic, z, is beta/se = 0.9409/0.1256 = 7.4880. The p-value, p, indicates that the effect of X is significant.
Plot the Cox estimate of the baseline survivor function together with the known Weibull function.
stairs(H(:,1),exp(-H(:,2)),'LineWidth',2) xx = linspace(0,100); line(xx,1-wblcdf(xx,50*exp(-0.5*mean(X)),B),'color','r','LineWidth',2) xlim([0,50]) legend('Estimated Survivor Function','Weibull Survivor Function')
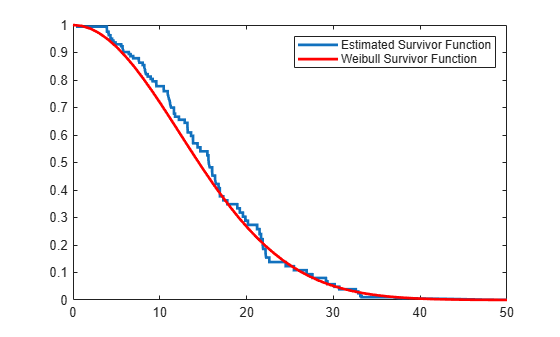
The fitted model gives a close estimate to the survivor function of the actual distribution.
Input Arguments
Name-Value Arguments
Output Arguments
More About
Algorithms
If you want to compute the baseline cumulative hazard rate (
H) for a stratum, the input data for the stratum must contain at least one fully observed observation. If a stratum has only censored observations, the outputHincludes a row withNaNs in the first two columns and the stratum information in the remaining columns.Before R2022a: If a stratum has only censored observations,
Hincludes a row of zeros and no stratum information.
References
[1] Cox, D.R., and D. Oakes. Analysis of Survival Data. London: Chapman & Hall, 1984.
[2] Lawless, J. F. Statistical Models and Methods for Lifetime Data. Hoboken, NJ: Wiley-Interscience, 2002.
[3] Kleinbaum, D. G., and M. Klein. Survival Analysis. Statistics for Biology and Health. 2nd edition. Springer, 2005.