Use Parallel Computing for Parameter Estimation
Configure Your System for Parallel Computing
You can speed up parameter estimation using parallel computing on multicore
processors or multiprocessor networks. Use parallel computing with the
Parameter Estimator and sdo.optimize to estimate parameters using the
fmincon, lsqnonlin, and
patternsearch methods. Parallel computing is not supported
for the fminsearch (Simplex search)
method.
When you estimate model parameters using parallel computing, the software uses the available parallel pool. If none is available, and you select Automatically create a parallel pool in your Parallel Computing Toolbox™ preferences, the software starts a parallel pool using the settings in those preferences. To open a parallel pool that uses a specific cluster profile, use:
parpool(MyProfile);
MyProfile is the name of a cluster profile.
For information regarding creating a cluster profile, see Add and Modify Cluster Profiles (Parallel Computing Toolbox).
Model Dependencies
Model dependencies are any referenced models, data such as model variables, S-functions, and additional files necessary to run the model. Before starting the optimization, verify that the model dependencies are complete. Otherwise, you may get unexpected results.
Making Model Dependencies Accessible to Remote Workers
When you use parallel computing, the Simulink® Design Optimization™ software helps you identify model dependencies. To do so, the software uses the Dependency Analyzer. The dependency analysis may not find all the files required by your model. To learn more, see Dependency Analyzer Scope and Limitations. If your model has dependencies that are undetected or inaccessible by the parallel pool workers, then add them to the list of model dependencies.
The dependencies are made accessible to the parallel pool workers by specifying one of the following:
File dependencies: the model dependency files are copied to the parallel pool workers.
Path dependencies: the paths to the model dependencies are added to the paths of the parallel pool workers. If you are working in a multi-platform scenario, ensure that the paths are compatible across platforms.
Using file dependencies is recommended, however, in some cases it can be better to choose path dependencies. For example, if parallel computing is set up on a local multi-core computer, using path dependencies is preferred as using file dependencies creates multiple copies of the dependent files on the local computer.
For more information, see:
Estimate Parameters Using Parallel Computing in the Parameter Estimator App (Not supported in Simulink Online™.)
Estimate Parameters Using Parallel Computing in the Parameter Estimator App
To estimate model parameters using parallel computing in the Parameter Estimator:
Ensure that the software can access parallel pool workers that use the appropriate cluster profile.
For more information, see Configure Your System for Parallel Computing.
Open the Parameter Estimator for the Simulink model.
Configure the estimation data, estimation parameters and states, and, optionally, estimation settings.
For more information, see Specify Estimation Data, Specify Parameters for Estimation, and Specify Estimation Options.
On the Parameter Estimation tab, click
 More Options to open the
Estimation Options dialog box.
More Options to open the
Estimation Options dialog box.Select the Parallel tab.
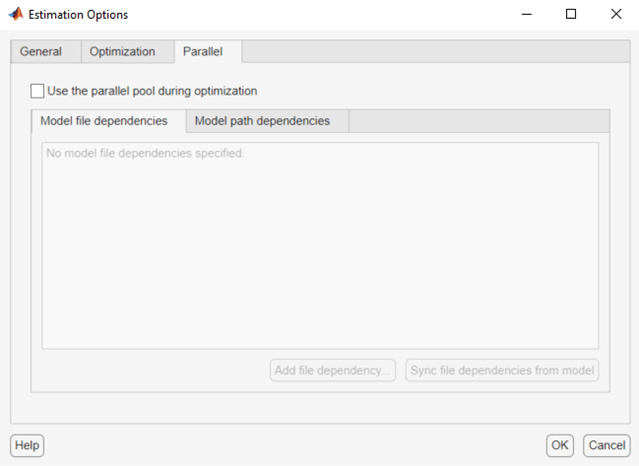
Select the Use the parallel pool during optimization check box.
This option checks for dependencies in your Simulink model. The file dependencies are displayed in the Model file dependencies list box, and corresponding path to the files in Model path dependencies. The files listed in Model file dependencies are copied to the remote workers.
Note
The automatic dependencies check may not detect all the dependencies in your model.
For more information, see Model Dependencies. In this case, add the undetected dependencies manually.
Add any file dependencies that the automatic check does not detect.
Specify the files in the Model file dependencies list box separated by semicolons or on separate lines.

Alternatively, click Add file dependency to open a dialog box, and select the file to add.
Note
If you do not want to copy the files to the remote workers, delete all entries in the Model file dependencies list box. Populate the Model path dependencies list box by clicking the Sync path dependencies from model, and add any undetected path dependencies. In addition, in the list box, update the paths on local drives to make them accessible to remote workers. For example, change
C:\to\\\\hostname\\C$\\.If you modify the Simulink model, resync the dependencies to ensure that any new dependencies are detected. Click Sync file dependencies from model in the Parallel Options tab to rerun the automatic dependency check for your model.
This action updates the Model file dependencies list box with any new file dependency found in the model.
Click OK.
In the Parameter Estimation tab, click Estimate to estimate the model parameters using parallel computing.
For information on troubleshooting problems related to estimation using parallel computing, see Troubleshooting.
Estimate Parameters Using Parallel Computing (Code)
To use parallel computing for parameter estimation at the command line:
Ensure that the software can access parallel pool workers that use the appropriate cluster profile.
For more information, see Configure Your System for Parallel Computing.
Open the model.
Configure an estimation experiment. For example, see Estimate Model Parameter Values (Code).
Enable parallel computing using an optimization option set,
opt.opt = sdo.OptimizeOptions; opt.UseParallel = true;
Find the model dependencies.
[dirs,files] = sdo.getModelDependencies(modelname)
Note
sdo.getModelDependenciesmay not detect all the dependencies in your model. For more information, see Model Dependencies. In this case, add the undetected dependencies manually.Modify
filesto include any file dependencies thatsdo.getModelDependenciesdoes not detect.files = vertcat(files,'C:\matlab\work\filename.m')Note
If you do not want to copy the files to the remote workers, use the path dependencies. Add any undetected path dependencies to
dirsand update the paths on local drives to make them accessible to remote workers. Seesdo.getModelDependenciesfor more details.Add the file dependencies for optimization.
opt.ParallelFileDependencies = files;
Run the optimization.
[pOpt,opt_info] = sdo.optimize(opt_fcn,param,opt);
For information on troubleshooting problems related to estimation using parallel computing, see Troubleshooting.
Troubleshooting
Why Are the Estimation Results With and Without Parallel Computing Different?
Different numerical precision on the client and worker machines can produce marginally different simulation results. Thus, the optimization method can take a different solution path and produce a different result.
When you use parallel computing with the
Pattern searchmethod, the search is more comprehensive and can result in a different solution. To learn more, see Parallel Computing with the Pattern search Method.
Why Didn’t the Estimation Speed up Using Parallel Computing?
When you estimate a few parameters or when the model does not take long to simulate, you do not see a speedup in the estimation time. In such cases, the overhead associated with creating and distributing the parallel tasks outweighs the benefits of running the estimation in parallel.
Using the
Pattern searchmethod with parallel computing might not speed up the optimization time. Without parallel computing, the method stops the search at each iteration as soon as it finds a solution better than the current solution. The candidate solution search is more comprehensive when you use parallel computing. Although the number of iterations might be larger, the optimization without using parallel computing might be faster.To learn more about the expected speedup, see Parallel Computing with the Pattern search Method.
Why Doesn’t the Estimation Using Parallel Computing Make Any Progress?
To troubleshoot the problem:
Run the optimization for a few iterations without parallel computing to see if the optimization progresses.
Check whether the remote workers have access to all model dependencies. Model dependencies include data variables and files required by the model to run.
To learn more, see Model Dependencies.
Why Does the Estimation Using Parallel Computing Continue When I Click Stop?
When
you use parallel computing with the Pattern search method,
the software must wait until the current optimization iteration completes
before it notifies the workers to stop. The optimization does not
terminate immediately when you click Stop,
and, instead, appears to continue running.
See Also
sdo.optimize | sdo.OptimizeOptions | sdo.getModelDependencies | parpool (Parallel Computing Toolbox)
Related Topics
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)