Distributed Pipelining: Speed Optimization
This example shows how to optimize a Simulink® design for speed by using the distributed pipelining optimization.
Distributed pipelining is a subsystem-wide optimization supported by HDL Coder for reducing the critical path and achieving high clock speed hardware. By turning on distributed pipelining, HDL Coder redistributes the input pipeline registers, output pipeline registers of the subsystem, and the registers in the subsystem to positions that minimize the combinatorial logic between registers and maximize the clock speed of the chip synthesized from the generated HDL code. For more information on distributed pipelining, see Specify Distributed Pipelining Settings.
Prerequisites
This example uses Xilinx® Vivado® as the synthesis tool. To set up the synthesis tool, use the function hdlsetuptoolpath.
This example targets a Xilinx Virtex®-7 with a speed grade of -1. HDL Coder™ has a default timing database for Xilinx Virtex-7 with a speed grade of -1. If you are targeting a device that HDL Coder does not have a characterized timing database for, use the function genhdltdb to create your own timing database. For a list of characterized timing databases, see Critical Path Estimation Without Running Synthesis.
If you generate your own timing database, you can use the model parameter TimingDatabaseDirectory to set the timing database for the model to your custom timing database created. For more information, see Custom Timing Database Directory.
Open the Model
Consider the following example model of a symmetric FIR filter. The combinatorial logic from an input or a register to an output or another register contains a product block and an adder tree. Distributed pipelining moves the output registers set at the subsystem level to reduce the levels of the combinatorial logic.
load_system('sfir_fixed'); open_system('sfir_fixed/symmetric_fir');

Set Output Pipeline Stage
To increase the clock speed, you can set a number of pipeline stages for any subsystem. Without turning on distributed pipelining, the specified number of registers are added to each of the output ports of the subsystem. Some synthesis tools support optimizations, such as retiming, that optimize the position of the registers during synthesis.
To see the effects of distributed pipelining in reducing the critical path and increasing the clock frequency, enable CriticalPathEstimation to estimate a critical path for your design. When you enable critical path estimation, HDL Coder uses a target-specific timing database to estimate the critical path. If you do not set a Synthesis Tool Chip Family and Synthesis Tool Speed Value to specify the specific target timing database, HDL Coder sets default values for both parameters for critical path estimation, and generates a warning when generating HDL code. To prevent the warning, specify the Synthesis Tool Chip Family and Synthesis Tool Speed Value. You can do this with or without a Synthesis Tool specified. For more information, see Critical Path Estimation Without Running Synthesis.
hdlset_param('sfir_fixed', 'CriticalPathEstimation', 'on'); hdlset_param('sfir_fixed', 'SynthesisToolChipFamily', 'virtex7', 'SynthesisToolSpeedValue', '-1')
In this example, the subsystem output pipeline register is set to 2.
The code generation model explicitly reflects the inserted register at output ports of the subsystem (highlighted in orange).
hdlset_param('sfir_fixed/symmetric_fir', 'OutputPipeline', 2); makehdl('sfir_fixed/symmetric_fir'); open_system('gm_sfir_fixed/symmetric_fir'); set_param('gm_sfir_fixed', 'SimulationCommand', 'update');
### Working on the model <a href="matlab:open_system('sfir_fixed')">sfir_fixed</a>
### Generating HDL for <a href="matlab:open_system('sfir_fixed/symmetric_fir')">sfir_fixed/symmetric_fir</a>
### Using the config set for model <a href="matlab:configset.showParameterGroup('sfir_fixed', { 'HDL Code Generation' } )">sfir_fixed</a> for HDL code generation parameters.
### Running HDL checks on the model 'sfir_fixed'.
### Begin compilation of the model 'sfir_fixed'...
### Working on the model 'sfir_fixed'...
### The code generation and optimization options you have chosen have introduced additional pipeline delays.
### The delay balancing feature has automatically inserted matching delays for compensation.
### The DUT requires an initial pipeline setup latency. Each output port experiences these additional delays.
### Output port 1: 2 cycles.
### Output port 2: 2 cycles.
### Working on... <a href="matlab:configset.internal.open('sfir_fixed', 'GenerateModel')">GenerateModel</a>
### Begin model generation 'gm_sfir_fixed'...
### Rendering DUT with optimization related changes (IO, Area, Pipelining)...
### Model generation complete.
### Generated model saved at <a href="matlab:open_system('hdlsrc/sfir_fixed/gm_sfir_fixed.slx')">hdlsrc/sfir_fixed/gm_sfir_fixed.slx</a>
### Estimated critical path for design: <a href="matlab:run('hdlsrc/sfir_fixed/criticalPathEstimated')">hdlsrc/sfir_fixed/criticalPathEstimated.m</a>
### To clear highlighting, click the following MATLAB script: <a href="matlab:run('hdlsrc/sfir_fixed/clearhighlighting.m')">hdlsrc/sfir_fixed/clearhighlighting.m</a>
### Begin VHDL Code Generation for 'sfir_fixed'.
### Working on sfir_fixed/symmetric_fir as hdlsrc/sfir_fixed/symmetric_fir.vhd.
### Generating package file hdlsrc/sfir_fixed/symmetric_fir_pkg.vhd.
### Code Generation for 'sfir_fixed' completed.
### Generating HTML files for code generation report at <a href="matlab:hdlcoder.report.openReportV2Dialog('/tmp/Bdoc26a_3233028_1592003/tpffb55611/hdlcoder-ex37495842/hdlsrc/sfir_fixed', '/tmp/Bdoc26a_3233028_1592003/tpffb55611/hdlcoder-ex37495842/hdlsrc/sfir_fixed/html/index.html')">index.html</a>
### Creating HDL Code Generation Check Report file:///tmp/Bdoc26a_3233028_1592003/tpffb55611/hdlcoder-ex37495842/hdlsrc/sfir_fixed/symmetric_fir_report.html
### HDL check for 'sfir_fixed' complete with 0 errors, 0 warnings, and 1 messages.
### HDL code generation complete.

The critical path estimated without distributed pipelining enabled is 10.269 ns. The estimated critical path appears in the Code Generation Report > Timing and Area Report > Critical Path Estimation tab.
Set Distributed Pipelining
Enable distributed pipelining for the model by entering:
hdlset_param('sfir_fixed', 'DistributedPipelining', 'on');
Generate HDL code with a specified generated model name, and open the generated model. The generated model explicitly reflects the distributed registers in the subsystem (highlighted in orange).
makehdl('sfir_fixed/symmetric_fir', 'GeneratedModelNamePrefix', 'gm2_'); open_system('gm2_sfir_fixed/symmetric_fir'); set_param('gm2_sfir_fixed', 'SimulationCommand', 'update');
### Working on the model <a href="matlab:open_system('sfir_fixed')">sfir_fixed</a>
### Generating HDL for <a href="matlab:open_system('sfir_fixed/symmetric_fir')">sfir_fixed/symmetric_fir</a>
### Using the config set for model <a href="matlab:configset.showParameterGroup('sfir_fixed', { 'HDL Code Generation' } )">sfir_fixed</a> for HDL code generation parameters.
### Running HDL checks on the model 'sfir_fixed'.
### Begin compilation of the model 'sfir_fixed'...
### Working on the model 'sfir_fixed'...
### The code generation and optimization options you have chosen have introduced additional pipeline delays.
### The delay balancing feature has automatically inserted matching delays for compensation.
### The DUT requires an initial pipeline setup latency. Each output port experiences these additional delays.
### Output port 1: 2 cycles.
### Output port 2: 2 cycles.
### Working on... <a href="matlab:configset.internal.open('sfir_fixed', 'GenerateModel')">GenerateModel</a>
### Begin model generation 'gm2_sfir_fixed'...
### Rendering DUT with optimization related changes (IO, Area, Pipelining)...
### Model generation complete.
### Generated model saved at <a href="matlab:open_system('hdlsrc/sfir_fixed/gm2_sfir_fixed.slx')">hdlsrc/sfir_fixed/gm2_sfir_fixed.slx</a>
### Estimated critical path for design: <a href="matlab:run('hdlsrc/sfir_fixed/criticalPathEstimated')">hdlsrc/sfir_fixed/criticalPathEstimated.m</a>
### To clear highlighting, click the following MATLAB script: <a href="matlab:run('hdlsrc/sfir_fixed/clearhighlighting.m')">hdlsrc/sfir_fixed/clearhighlighting.m</a>
### Begin VHDL Code Generation for 'sfir_fixed'.
### Working on sfir_fixed/symmetric_fir as hdlsrc/sfir_fixed/symmetric_fir.vhd.
### Generating package file hdlsrc/sfir_fixed/symmetric_fir_pkg.vhd.
### Code Generation for 'sfir_fixed' completed.
### Generating HTML files for code generation report at <a href="matlab:hdlcoder.report.openReportV2Dialog('/tmp/Bdoc26a_3233028_1592003/tpffb55611/hdlcoder-ex37495842/hdlsrc/sfir_fixed', '/tmp/Bdoc26a_3233028_1592003/tpffb55611/hdlcoder-ex37495842/hdlsrc/sfir_fixed/html/index.html')">index.html</a>
### Creating HDL Code Generation Check Report file:///tmp/Bdoc26a_3233028_1592003/tpffb55611/hdlcoder-ex37495842/hdlsrc/sfir_fixed/symmetric_fir_report.html
### HDL check for 'sfir_fixed' complete with 0 errors, 0 warnings, and 1 messages.
### HDL code generation complete.
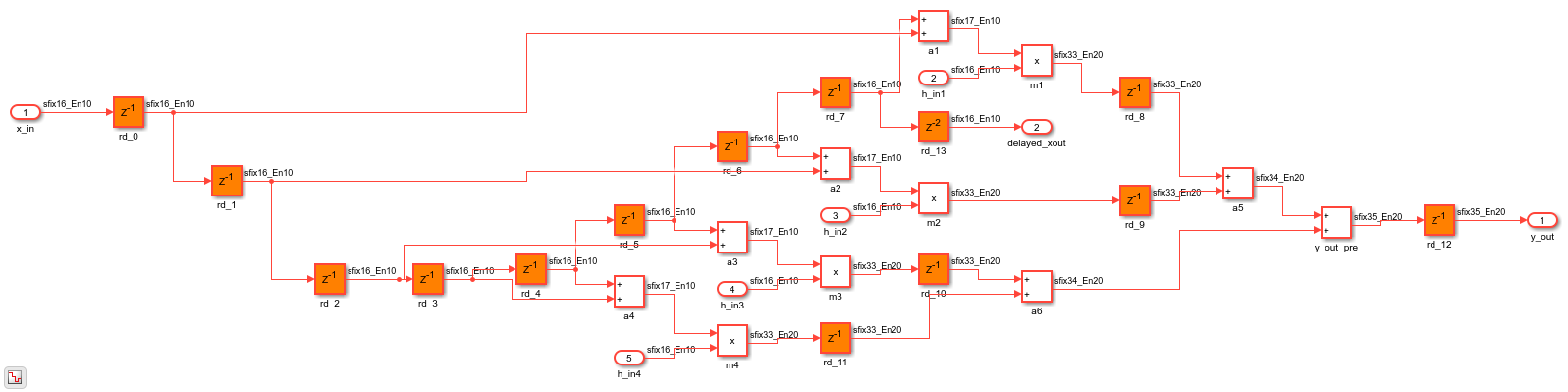
The critical path estimated with distributed pipelining on is now 7.443 ns.
Use Synthesis Timing Estimates for Distributed Pipelining
To more accurately reflect how components function on hardware to better distribute pipelines in your design and maximize the clock frequency for your target device, enable synthesis timing estimates for distributed pipelining using the model configuration parameter Use synthesis estimates for Distributed Pipelining or through the command-line.
hdlset_param('sfir_fixed', 'UseSynthesisEstimatesForDistributedPipelining', 'on');
Generate HDL code with a specified generated model name, and open the generated model.
makehdl('sfir_fixed/symmetric_fir', 'GeneratedModelNamePrefix', 'gm3_'); open_system('gm3_sfir_fixed/symmetric_fir'); set_param('gm3_sfir_fixed', 'SimulationCommand', 'update');
### Working on the model <a href="matlab:open_system('sfir_fixed')">sfir_fixed</a>
### Generating HDL for <a href="matlab:open_system('sfir_fixed/symmetric_fir')">sfir_fixed/symmetric_fir</a>
### Using the config set for model <a href="matlab:configset.showParameterGroup('sfir_fixed', { 'HDL Code Generation' } )">sfir_fixed</a> for HDL code generation parameters.
### Running HDL checks on the model 'sfir_fixed'.
### Begin compilation of the model 'sfir_fixed'...
### Working on the model 'sfir_fixed'...
### The code generation and optimization options you have chosen have introduced additional pipeline delays.
### The delay balancing feature has automatically inserted matching delays for compensation.
### The DUT requires an initial pipeline setup latency. Each output port experiences these additional delays.
### Output port 1: 2 cycles.
### Output port 2: 2 cycles.
### Working on... <a href="matlab:configset.internal.open('sfir_fixed', 'GenerateModel')">GenerateModel</a>
### Begin model generation 'gm3_sfir_fixed'...
### Rendering DUT with optimization related changes (IO, Area, Pipelining)...
### Model generation complete.
### Generated model saved at <a href="matlab:open_system('hdlsrc/sfir_fixed/gm3_sfir_fixed.slx')">hdlsrc/sfir_fixed/gm3_sfir_fixed.slx</a>
### Estimated critical path for design: <a href="matlab:run('hdlsrc/sfir_fixed/criticalPathEstimated')">hdlsrc/sfir_fixed/criticalPathEstimated.m</a>
### To clear highlighting, click the following MATLAB script: <a href="matlab:run('hdlsrc/sfir_fixed/clearhighlighting.m')">hdlsrc/sfir_fixed/clearhighlighting.m</a>
### Begin VHDL Code Generation for 'sfir_fixed'.
### Working on sfir_fixed/symmetric_fir as hdlsrc/sfir_fixed/symmetric_fir.vhd.
### Generating package file hdlsrc/sfir_fixed/symmetric_fir_pkg.vhd.
### Code Generation for 'sfir_fixed' completed.
### Generating HTML files for code generation report at <a href="matlab:hdlcoder.report.openReportV2Dialog('/tmp/Bdoc26a_3233028_1592003/tpffb55611/hdlcoder-ex37495842/hdlsrc/sfir_fixed', '/tmp/Bdoc26a_3233028_1592003/tpffb55611/hdlcoder-ex37495842/hdlsrc/sfir_fixed/html/index.html')">index.html</a>
### Creating HDL Code Generation Check Report file:///tmp/Bdoc26a_3233028_1592003/tpffb55611/hdlcoder-ex37495842/hdlsrc/sfir_fixed/symmetric_fir_report.html
### HDL check for 'sfir_fixed' complete with 0 errors, 1 warnings, and 1 messages.
### HDL code generation complete.

Using synthesis timing estimates causes an increase in run time of the function makehdl, but it can reduce the critical path and increase the clock frequency of your design. For more information, see Distributed Pipelining Using Synthesis Timing Estimates.
The critical path estimation report shows that critical path is now 6.320 ns. The critical path estimation is just an estimated critical path based on a target-specific timing database. If you want the actual critical path on your target hardware, you must run the model through synthesis.
Synthesis Comparison of Distributed Pipelining With and Without Synthesis Timing Estimates
In the HDL Workflow Advisor, generate HDL code and perform FPGA synthesis using the Generic ASIC/FPGA workflow with these settings:
Synthesis tool set to
Xilinx VivadoFamily of the synthesis tool set to
virtex7Speed of the synthesis tool set to
-1Target Frequency (MHz) set to
120
For more information on the code generation and synthesis steps, see HDL Code Generation and FPGA Synthesis from Simulink Model.
The synthesis results without distributed pipelining enabled are:

The synthesis results shows negative slack, indicating that timing constraints are not met. The clock frequency is not calculated when timing constraints are not met.
The synthesis results with distributed pipelining enabled are:

The synthesis results show positive slack and a clock frequency of 178.05 MHz, indicating that the timing constraints are met and the target clock frequency of 120 MHz is met.
The synthesis results with distributed pipelining using synthesis timing estimates are:

The synthesis results show a clock frequency of 222.40 MHz, indicating that the timing constraints are met. The clock speed has increased by using synthesis timing estimates for distributed pipelining.
Distributed Pipelining Across Subsystem Hierarchies
If your DUT subsystem has subsystem hierarchy, meaning it contains lower-level subsystems, set the model parameter Distributed pipelining to on to have distributed pipelining run through the entire DUT without needing to enable DistributedPipelining for the DUT and each subsystem inside the DUT. The subsystem HDL block property DistributedPipelining is set to inherit by default, which means that each subsystem takes the DistributedPipelining value of its parent subsystem. The top-level DUT subsystem takes the value specified by the model parameter Distributed pipelining.
You can specifically enable or disable distributed pipelining for a lower-level subsystem if you set the HDL block property DistributedPipelining to On or Off for the subsystem. For more information, DistributedPipelining.