Discrete FIR Filter
Finite-impulse response filter
Libraries:
DSP HDL Toolbox /
Filtering
Description
The Discrete FIR Filter block models finite-impulse response filter architectures optimized for HDL code generation. The block accepts scalar or frame-based input, supports multichannel input, and provides an option for programmable coefficients by using a parallel interface or a memory interface. The block provides a hardware-friendly interface with input and output control signals. To provide a cycle-accurate simulation of the generated HDL code, the block models architectural latency including pipeline registers and resource sharing.
The block provides three filter structures.
The direct form systolic architecture provides a fully parallel implementation that makes efficient use of Intel® and Xilinx® DSP blocks.
The direct form transposed architecture is a fully parallel implementation and is suitable for FPGA and ASIC applications.
The partly serial systolic architecture provides a configurable serial implementation that makes efficient use of FPGA DSP blocks.
For a filter implementation that matches multipliers, pipeline registers, and pre-adders to the DSP configuration of your FPGA vendor, specify your target device when you generate HDL code.
All single-channel filter structures remove multipliers for zero-valued coefficients, such as in half-band filters and Hilbert transforms. The block also provides an option to implement +/- 1 and power of 2 coefficients without a multiplier, and an option to implement all coefficients with CSD or factored-CSD logic. When you use scalar or multichannel input data, the filter shares multipliers for symmetric and antisymmetric coefficients. Frame-based filters do not implement symmetry optimization. Multichannel filters do not remove multipliers for zero-valued coefficients. Multichannel filters share resources between channels, even if the filter coefficients are different across the channels.
The latency between valid input data and the corresponding valid output data depends on the filter structure, serialization options, number of coefficients, and whether the coefficient values provide optimization opportunities. For details of structure and latency, see FIR Filter Architectures for FPGAs and ASICs.
Examples
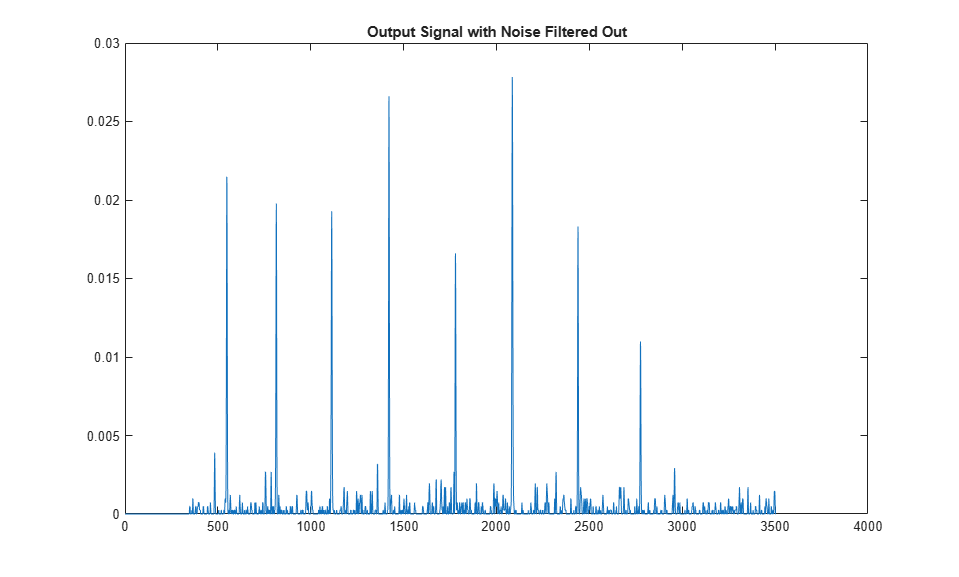

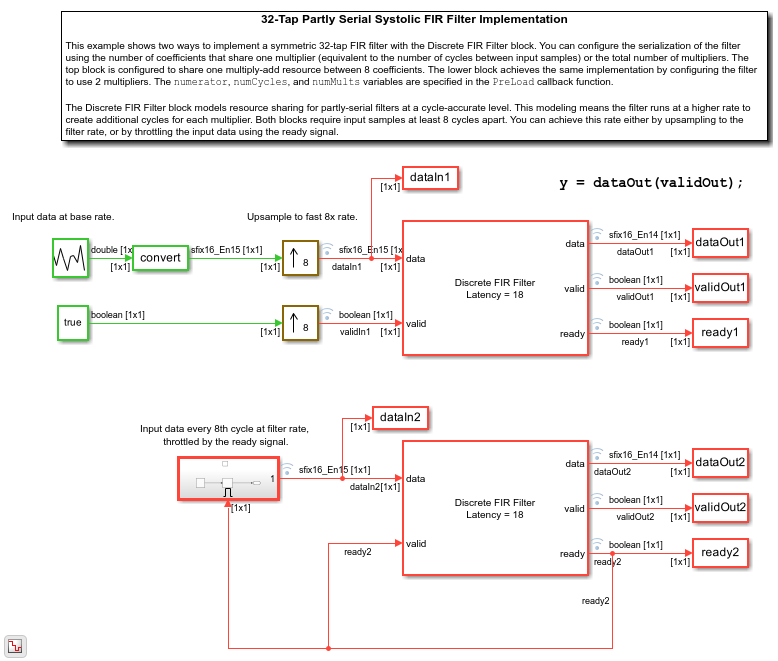


Ports
Input
data — Input data
scalar | column vector | row vector
Input data, specified as a scalar, column vector, or row vector of real or complex values. Use a column vector to increase throughput by processing samples in parallel.
You can use a row vector to represent multiple channels, or you can provide scalar multichannel data with the channels interleaved. The channels can have independent filter coefficients. (since R2023a)
In R2023a and
R2023b: you can use multichannel row-vector input
only if there are at least as many invalid cycles
between inputs as there are channels. When the input
is a multichannel vector, the
Filter
structure must be
set to Partly
serial
systolic, and
Number of
cycles must be
equal to or greater than the number of channels.
This time allows the block to implement a
partly-serial architecture that shares resources
between the channels.
Frame based (column vector) input is not supported with multichannel coefficients. To implement a high-throughput multichannel filter, you can use a For Each block to implement a high throughput filter for each channel. This implementation cannot share resources between the channels.
The size of the row or column vector must be less than or equal to 64 elements. To implement a multichannel filter with more than 64 channels, you must use interleaved scalar input.
When the input data type is an integer type or a fixed-point type, the block uses fixed-point arithmetic for internal calculations and provides parameters on the Data Types tab to customize the data types. When the input data type is a floating-point type, the block uses that input floating-point type for internal calculations and the output data type.
The software supports double and
single data types for simulation, but not for HDL code generation.
Data Types: fixed point | single | double | int8 | int16 | int32 | uint8 | uint16 | uint32
Complex Number Support: Yes
valid — Indicates valid input data
scalar
Control signal that indicates if the input data is valid.
When valid is 1
(true), the block captures the
values from the input data port. When
valid is 0
(false), the block ignores the
values from the input data
port.
Data Types: Boolean
coeff — Filter coefficients (Parallel interface)
real or complex row vector
Filter coefficients, specified as a row vector of real or complex values. You can change the input coefficients at any time. When you use scalar input data, the size of the coefficient vector depends on the size and symmetry of the sample coefficients specified in the Coefficients prototype parameter. The prototype specifies a sample coefficient vector that is representative of the symmetry and zero-valued locations of the expected input coefficients. The block uses the prototype to optimize the filter by sharing multipliers for symmetric or antisymmetric coefficients, and by removing multipliers for zero-valued coefficients. Therefore, provide only the nonduplicate coefficients at the port. For example, if you set the Coefficients prototype parameter to a symmetric 14-tap filter, the block expects a vector of 7 values on the coeff input port. You must still provide zeros in the input coeff vector for the nonduplicate zero-valued coefficients.
When you use frame-based input data, the block does not optimize the filter for coefficient symmetry. The block still uses the Coefficients prototype to remove multipliers for zero-valued coefficients. At the coeff input port, specify a vector that is the same size as the prototype.
If the input data is a fixed-point type, the coeff values must also be of a fixed point type. If the input data is a floating-point data type, the coeff values must be of the same data type.
The software supports double and
single data types for simulation, but not for HDL code generation.
Dependencies
To enable this port, set Coefficients
source to Input port
(Parallel interface).
Data Types: single | double | int8 | int16 | int32 | uint8 | uint16 | uint32 | fixed point
coeff — Filter coefficients (Memory interface)
real or complex scalar
Since R2023a
Filter coefficients, specified as a real or complex scalar value to write to internal memory. To load a single coefficient value to internal memory, specify a coeff value with a corresponding address on the caddr port and an enable signal on the cwren port. You can change the input coefficients at any time.

While you write new coefficients into memory, the block
ignores any input data, but still returns
dataOut with
validOut until it clears the
filter pipeline. The block resumes accepting input the
cycle after cdone is set to
1 (true).

The coefficient memory has the same number of addresses as the size of the Coefficients prototype parameter. The prototype specifies a sample coefficient vector that is representative of the symmetry and zero-valued locations of the expected input coefficients. When you use scalar input data, the block uses the prototype to optimize the filter by sharing multipliers for symmetric or antisymmetric coefficients, and by removing multipliers for zero-valued coefficients. You must write the entire set of coefficients to memory, including symmetric or zero-value coefficients. For example, if you set the Coefficients prototype parameter to a symmetric 14-tap filter, you must write 14 values to the memory interface.
When you use frame-based input data, the block does not optimize the filter for coefficient symmetry. The block still uses the Coefficients prototype parameter to remove multipliers for zero-valued coefficients. The coefficient memory has the same number of locations as the size of the prototype.
If the input data is a fixed-point type, the coeff values must also be of a fixed point type. If the input data is a floating-point data type, the coeff values must be of the same data type.
The software supports double and
single data types for simulation, but not for HDL code generation.
Dependencies
To enable this port, set Coefficients
source to Input port
(Memory interface).
Data Types: single | double | int8 | int16 | int32 | uint8 | uint16 | uint32 | fixed point
caddr — Filter coefficient address (Memory interface)
scalar
Since R2023a
Specify the filter coefficient address as a scalar integer value represented as an unsigned fixed-point type with zero fractional bits. The block derives the size of this integer value, and the size of the internal memory, from the number of unique coefficients in the Coefficients prototype parameter value.
Dependencies
To enable this port, set Coefficients
source to Input port
(Memory interface).
Data Types: fixdt(0,N,0)
cwren — Filter coefficients write enable (Memory interface)
scalar
Since R2023a
Set this input to 1
(true) to write the value on the
coeff port into the
caddr location in internal
memory.
Dependencies
To enable this port, set Coefficients
source to Input port
(Memory interface).
Data Types: Boolean
cdone — Filter coefficient write complete (Memory interface)
scalar
Since R2023a
Set this input to 1
(true) to indicate that the
current port values write the final coefficient value to
memory.
Dependencies
To enable this port, set Coefficients
source to Input port
(Memory interface).
Data Types: Boolean
reset — Clears internal states
scalar
Control signal that clears internal states. When
reset is 1
(true), the block stops the
current calculation and clears internal states. When
reset is 0
(false) and the input
valid is 1
(true), the block captures data
for processing.
For more reset considerations, see the Reset Signal section on the Hardware Control Signals page.
Dependencies
To enable this port, on the Control Ports tab, select Enable reset input port.
Data Types: Boolean
Output
Parameters
Algorithms
The filter architectures for the Discrete FIR Filter block are shared with other filter blocks and described in detail on the FIR Filter Architectures for FPGAs and ASICs page.
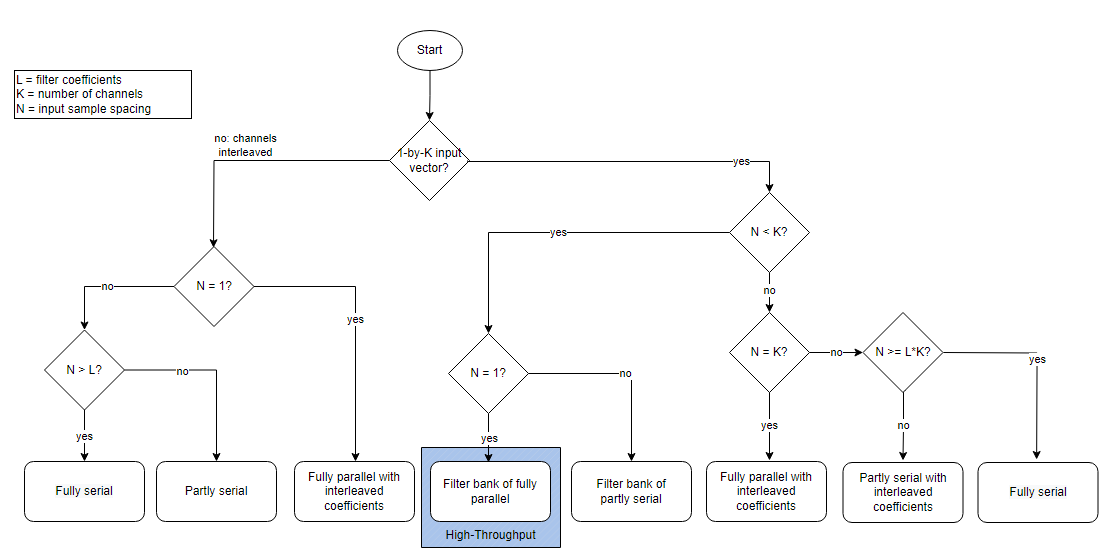
This flow chart shows the Discrete FIR Filter block architecture for multichannel coefficients, that is, when you set the Coefficients parameter to an K-by-L matrix.
If the filter is symmetric, the architecture shares multipliers for matching
coefficients, so effectively L =
L/2. To enable the symmetry optimization, the
symmetry characteristics of all channels must align. For example, if one channel
is even-symmetric, all channels must be even-symmetric.
The sections below show the hardware resources and synthesized clock speed for the Discrete FIR Filter block configured with each filter architecture.
Extended Capabilities
Version History
Introduced in R2017aYou can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)