Predict Hospital Readmission Using Text Classification | Text Analytics for Biomedical Applications, Part 4
From the series: Text Analytics for Biomedical Applications
Explore the code to build a text classification model that predicts if there will be an unintended hospital readmission within 30 days by analyzing notes of doctors and nurses taken during patient visits.
Published: 3 Feb 2021
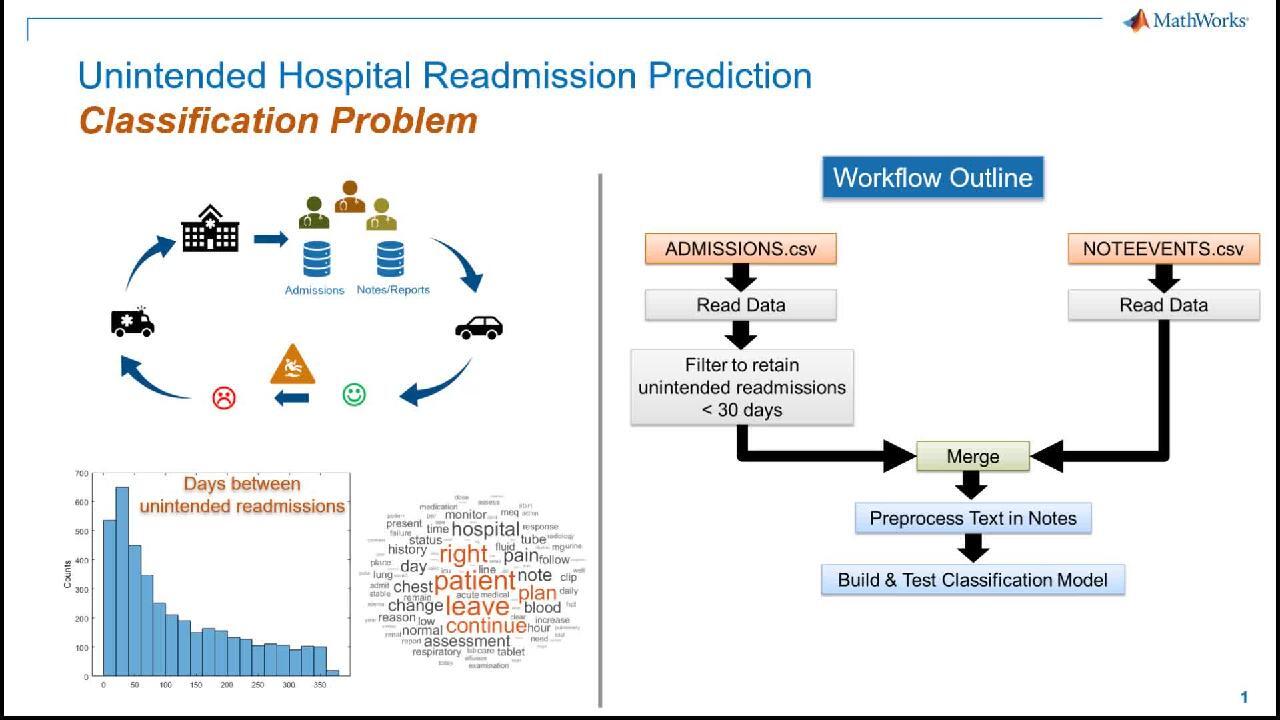
In this video, we are going to go through the steps of building a classification model for predicting unintended hospital readmissions. Now, on the right-hand side, we have the workflow outline where there are two different data sets. One has the information about the admissions. And the other one has the notes taken during a patient's visit.
We take the two data sets. We read it in. And then we filter, do some manipulations, and then merge the sets. Finally, using the combined data set, we then preprocess the text in the notes and build the classification model.
Now let's look into the MATLAB code for doing that. Now, this is the MATLAB Live Editor environment. And we are using the data MIMIC-III that we downloaded from PhysioNet, and you can do the same.
Now we are going to solve the problem in three steps. One is reading the data, and manipulating, and combining. Next is preprocessing the data for building the model, and then finally building the model and testing it.
Now let's take a look at the data in. And we are reading in admissions.csv. We can save it as a MAT file and then, later on, load it for doing further analysis with it. Now, once we have the data, then we sort the data with respect to SUBJECT_ID and admission time.
Next, take a look at, what are the different categories of hospital admissions? Now, from here, since our goal is to predict unintended admissions, we are going to only keep the ones in Emergency and Urgent, and eliminate the ones Newborn and Elective. So we do that in the next step. And then we only keep the repeat visitors because our intention is to predict readmissions.
Next, we create a variable to estimate the amount of time elapsed between visits, which is our T.Timelapse. Then we plot the time lapse to take a look at the distribution of the days in between unintended readmissions. So you can see that this is a huge range.
Now, next, we are reading in the notes data. And similarly, you can read it in. You can save it as a MAT file and load in afterwards. Now, in our Admissions table, we only have the patients that are repeat visitors. So similarly, in the Notes table, we are going to only keep the ones that are repeat visitors.
Then we join the data, and then sort the data, and only keep the variables that are relevant for us. Then let's take a look at the category of Notes. So when we plot the category of Notes, there are many different types of notes in the database.
Now, we can combine all the notes and use all of it and analysis, or pick and choose the ones that we think are going to be relevant. So in this case, we are going to only keep the Discharge Summary. So here, we are only keeping the Discharge Summary. Now we are creating another variable, a flag, to indicate whether the readmission was within 30 days.
So next, go into the preprocessing of the data. Now, here, we are creating a response variable from the flag that we've just created for readmission within 30 days. And we take the notes in the data, the discharge summaries, and preprocess it to make it ready for building the model.
Now, preprocessText is a helper function that we have at the bottom of the script that does very frequently done preprocessing tasks on text data like tokenization, breaking it down into individual words and symbols, erasing punctuation and stop words, and things like that. Next, we are creating a bag of words model, which is a very common way of building model with text data.
And then from the bag, we remove infrequent words, anything that appears less than two times. And then we take a look at the bag. From the bag, we are creating a matrix called term frequency-inverse document frequency. And this is where we take into account the fact that some words may appear many times in a specific document but may not appear anywhere else.
Now, next, we declare the response variable as a categorical variable and see that the class 1, which is there will be an admission, readmission, is about 20%. And the rest is about 80%. And we are dividing the data set into two parts. One is for training. The other one is for testing. The cvpartition, this function, tries to keep the same proportion of the classes in both training and the testing data sets.
Next, we will be building the model. Here, I'm using support vector machine to create the classification model. And I'm also using a weight matrix to indicate that it is important to me to correctly predict whether there is going to be a remission. So the case where the true class is readmission and the predicted class is nonreadmission is worse for me. So I'm penalizing those cases.
And then we build the model. And we take a look at the confusion chart for the true class and the predicted class. And the accuracy is about 73%, which is not great. So the next things that we can do is we can optimize the hyperparameters of the model automatically, or we could also use this app, called Classification Learner app, where you can try many different methods and choose the one that has the highest accuracy for this specific data set.
And all the Live Editor notebooks that I showed here, these are all available in GitHub. And we will be giving you the link to the GitHub repository so that you can download Live Editor notebooks and then try it out yourself. So here, we built a classification model for predicting unintended hospital readmission using the text data from doctors' and nurses' notes.
Featured Product
Text Analytics Toolbox










Website auswählen
Wählen Sie eine Website aus, um übersetzte Inhalte (sofern verfügbar) sowie lokale Veranstaltungen und Angebote anzuzeigen. Auf der Grundlage Ihres Standorts empfehlen wir Ihnen die folgende Auswahl: United States.
Sie können auch eine Website aus der folgenden Liste auswählen:
Amerika
- América Latina (Español)
- Canada (English)
- United States (English)
Europa
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)