Getting Started with R-CNN, Fast R-CNN, and Faster R-CNN
Object detection is the process of finding and classifying objects in an image. One deep learning approach, regions with convolutional neural networks (R-CNN), combines rectangular region proposals with convolutional neural network features. R-CNN is a two-stage detection algorithm. The first stage identifies a subset of regions in an image that might contain an object. The second stage classifies the object in each region.
Applications for R-CNN object detectors include:
Autonomous driving
Smart surveillance systems
Facial recognition
Computer Vision Toolbox™ provides object detectors for the R-CNN, Fast R-CNN, and Faster R-CNN algorithms.
Instance segmentation expands on object detection to provide pixel-level segmentation of individual detected objects. Computer Vision Toolbox provides layers that support a deep learning approach for instance segmentation called Mask R-CNN. For more information, see Getting Started with Mask R-CNN for Instance Segmentation.
Object Detection Using R-CNN Algorithms
Models for object detection using regions with CNNs are based on the following three processes:
Find regions in the image that might contain an object. These regions are called region proposals.
Extract CNN features from the region proposals.
Classify the objects using the extracted features.
There are three variants of an R-CNN. Each variant attempts to optimize, speed up, or enhance the results of one or more of these processes.
R-CNN
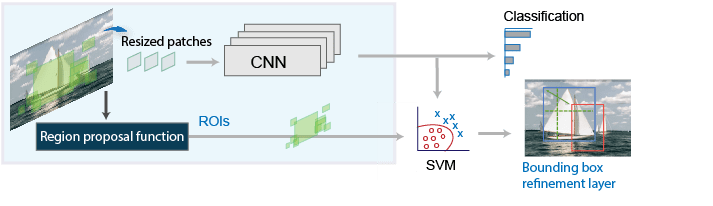
The R-CNN detector [2] first generates region proposals using an algorithm such as Edge Boxes[1]. The proposal regions are cropped out of the image and resized. Then, the CNN classifies the cropped and resized regions. Finally, the region proposal bounding boxes are refined by a support vector machine (SVM) that is trained using CNN features.
Use the trainRCNNObjectDetector function to
train an R-CNN object detector. The function returns an rcnnObjectDetector object that
detects objects in an image.
Fast R-CNN
As in the R-CNN detector , the Fast R-CNN[3] detector also uses an algorithm like Edge Boxes to generate region proposals. Unlike the R-CNN detector, which crops and resizes region proposals, the Fast R-CNN detector processes the entire image. Whereas an R-CNN detector must classify each region, Fast R-CNN pools CNN features corresponding to each region proposal. Fast R-CNN is more efficient than R-CNN, because in the Fast R-CNN detector, the computations for overlapping regions are shared.
Use the trainFastRCNNObjectDetector
function to train a Fast R-CNN object detector. The function returns a fastRCNNObjectDetector that detects
objects from an image.

Faster R-CNN
The Faster R-CNN[4] detector adds a region proposal network (RPN) to generate region proposals directly in the network instead of using an external algorithm like Edge Boxes. The RPN uses Anchor Boxes for Object Detection. Generating region proposals in the network is faster and better tuned to your data.
Use the trainFasterRCNNObjectDetector
function to train a Faster R-CNN object detector. The function returns a fasterRCNNObjectDetector that detects
objects from an image.

Comparison of R-CNN Object Detectors
This family of object detectors uses region proposals to detect objects within images. The number of proposed regions dictates the time it takes to detect objects in an image. The Fast R-CNN and Faster R-CNN detectors are designed to improve detection performance with a large number of regions.
| R-CNN Detector | Description |
|---|---|
trainRCNNObjectDetector |
|
trainFastRCNNObjectDetector |
|
trainFasterRCNNObjectDetector |
|
Transfer Learning
You can use a pretrained convolution neural network (CNN) as the basis for an R-CNN
detector, also referred to as transfer learning. See Pretrained Deep Neural Networks (Deep Learning Toolbox).
Use one of the following networks with the trainRCNNObjectDetector, trainFasterRCNNObjectDetector, or trainFastRCNNObjectDetector functions. To use any of these networks you
must install the corresponding Deep Learning Toolbox™ model:
'
alexnet(Deep Learning Toolbox)''
vgg16(Deep Learning Toolbox)''
vgg19(Deep Learning Toolbox)''
resnet50(Deep Learning Toolbox)''
resnet101(Deep Learning Toolbox)''
inceptionv3(Deep Learning Toolbox)''
googlenet(Deep Learning Toolbox)''
inceptionresnetv2(Deep Learning Toolbox)''
squeezenet(Deep Learning Toolbox)'
You can also design a custom model based on a pretrained image classification CNN. See the Design an R-CNN, Fast R-CNN, and a Faster R-CNN Model section and the Deep Network Designer (Deep Learning Toolbox) app.
Design an R-CNN, Fast R-CNN, and a Faster R-CNN Model
You can design custom R-CNN models based on a pretrained image classification CNN. You can also use the Deep Network Designer (Deep Learning Toolbox) to build, visualize, and edit a deep learning network.
The basic R-CNN model starts with a pretrained network. The last three classification layers are replaced with new layers that are specific to the object classes you want to detect.
For an example of how to create an R-CNN object detection network, see Create R-CNN Object Detection Network

The Fast R-CNN model builds on the basic R-CNN model. A box regression layer is added to improve on the position of the object in the image by learning a set of box offsets. An ROI pooling layer is inserted into the network to pool CNN features for each region proposal.
For an example of how to create a Fast R-CNN object detection network, see Create Fast R-CNN Object Detection Network

The Faster R-CNN model builds on the Fast R-CNN model. A region proposal network is added to produce the region proposals instead of getting the proposals from an external algorithm.
For an example of how to create a Faster R-CNN object detection network, see Create Faster R-CNN Object Detection Network

Label Training Data for Deep Learning
You can use the Image Labeler,
Video Labeler,
or Ground Truth Labeler (Automated Driving Toolbox) apps to interactively
label pixels and export label data for training. The apps can also be used to label
rectangular regions of interest (ROIs) for object detection, scene labels for image
classification, and pixels for semantic segmentation. To create training data from any
of the labelers exported ground truth object, you can use the objectDetectorTrainingData or pixelLabelTrainingData functions. For more details, see Training Data for Object Detection and Semantic Segmentation.
References
[1] Zitnick, C. Lawrence, and P. Dollar. "Edge boxes: Locating object proposals from edges." Computer Vision-ECCV. Springer International Publishing. Pages 391-4050. 2014.
[2] Girshick, R., J. Donahue, T. Darrell, and J. Malik. "Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation." CVPR '14 Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Pages 580-587. 2014
[3] Girshick, Ross. "Fast r-cnn." Proceedings of the IEEE International Conference on Computer Vision. 2015
[4] Ren, Shaoqing, Kaiming He, Ross Girshick, and Jian Sun. "Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks." Advances in Neural Information Processing Systems . Vol. 28, 2015.
See Also
Apps
- Image Labeler | Ground Truth Labeler (Automated Driving Toolbox) | Video Labeler | Deep Network Designer (Deep Learning Toolbox)
Functions
trainRCNNObjectDetector|trainFastRCNNObjectDetector|trainFasterRCNNObjectDetector|fasterRCNNObjectDetector|fastRCNNObjectDetector|rcnnObjectDetector
Related Examples
More About
- Anchor Boxes for Object Detection
- Deep Learning in MATLAB (Deep Learning Toolbox)
- Pretrained Deep Neural Networks (Deep Learning Toolbox)
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)