Measure GPU Memory Bandwidth and Processing Power
This example shows how to measure some of the key performance characteristics of your GPU hardware.
GPUs can be used to speed up certain types of computations. However, GPU performance varies widely between different GPU devices. These three tests quantify the performance of a GPU:
How quickly can data be sent to the GPU or read back from it?
How fast can the GPU kernel read and write data?
How fast can the GPU perform computations in double and single precision?
After assessing these metrics, you can compare the performance of the GPU and the host CPU. This comparison indicated how much data or computation is required for the GPU to provide an advantage over the CPU.
Check GPU Setup
Check whether a GPU is available.
gpu = gpuDevice;
disp(gpu.Name + " GPU detected and available.")NVIDIA RTX A5000 GPU detected and available.
Measure Host/GPU Bandwidth
The first test estimates how quickly data can be sent to and read from the GPU. Because the GPU is plugged into the PCI bus, the bandwidth largely depends on how fast the PCI bus is and how many other devices are using it. However, there are some overheads that are included in the measurements, particularly the time taken to call the send and read functions and allocate the arrays. Because these are present in any "real world" use of the GPU, it is reasonable to include these overheads.
To define the test parameters:
Create a variable representing the number of bytes required to store a double-precision number.
Create an vector of sizes, where the maximum size is 1/4 of the available GPU memory. The tests loop over this vector and create arrays of increasing size. As an array on the GPU in MATLAB® cannot have more than elements, remove any sizes that will create arrays larger than this.
sizeOfDouble = 8; maxSize = 0.25*gpu.AvailableMemory; maxNumTests = 15; sizes = logspace(4,log10(maxSize),maxNumTests); sizes(sizes/sizeOfDouble > intmax) = [];
To measure the host/GPU bandwidth, for each array size in sizes:
Create random double-precision data on the host and on the GPU.
Use the
gputimeitfunction to time allocating memory and sending data from the host to the GPU using thegpuArrayfunction.Use the
timeitfunction to time allocating memory and sending data from the GPU to the host using thegatherfunction.Divide the amount of data sent by the measured time to determine the bandwidth.
numTests = numel(sizes); numElements = floor(sizes/sizeOfDouble); sendTimes = inf(1,numTests); gatherTimes = inf(1,numTests); for idx=1:numTests disp("Test " + idx + " of " + numTests + ". Timing send and gather for array with " + numElements(idx) + " elements.") % Generate random data on GPU and host. gpuData = randi([0 9],numElements(idx),1,"gpuArray"); hostData = gather(gpuData); % Time sending data to GPU. sendFcn = @() gpuArray(hostData); sendTimes(idx) = gputimeit(sendFcn); % Time gathering data back from GPU. gatherFcn = @() gather(gpuData); gatherTimes(idx) = gputimeit(gatherFcn); end
Test 1 of 15. Timing send and gather for array with 1250 elements. Test 2 of 15. Timing send and gather for array with 3236 elements. Test 3 of 15. Timing send and gather for array with 8379 elements. Test 4 of 15. Timing send and gather for array with 21694 elements. Test 5 of 15. Timing send and gather for array with 56170 elements. Test 6 of 15. Timing send and gather for array with 145431 elements. Test 7 of 15. Timing send and gather for array with 376538 elements. Test 8 of 15. Timing send and gather for array with 974896 elements. Test 9 of 15. Timing send and gather for array with 2524111 elements. Test 10 of 15. Timing send and gather for array with 6535191 elements. Test 11 of 15. Timing send and gather for array with 16920303 elements. Test 12 of 15. Timing send and gather for array with 43808456 elements. Test 13 of 15. Timing send and gather for array with 113424733 elements. Test 14 of 15. Timing send and gather for array with 293668645 elements. Test 15 of 15. Timing send and gather for array with 760339221 elements.
sendBandwidth = (sizes./sendTimes)/1e9; gatherBandwidth = (sizes./gatherTimes)/1e9;
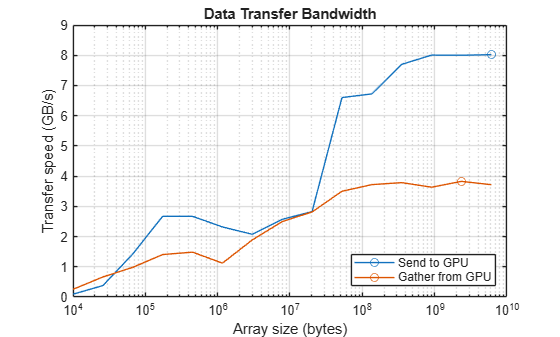
Determine the peak send and gather speeds. Note that the GPU used in this test supports PCI Express® version 4.0, which has a theoretical bandwidth of 1.97 GB/s per lane. For the 16-lane slots used by NVIDIA® compute cards this gives a theoretical bandwidth of 31.52 GB/s.
[maxSendBandwidth,maxSendIdx] = max(sendBandwidth);
[maxGatherBandwidth,maxGatherIdx] = max(gatherBandwidth);
fprintf("Achieved peak send speed of %.2f GB/s",maxSendBandwidth)Achieved peak send speed of 8.02 GB/s
fprintf("Achieved peak gather speed of %.2f GB/s",maxGatherBandwidth)Achieved peak gather speed of 3.83 GB/s
Plot the data transfer speeds against array size, and circle the peak for each case. With small data set sizes, overheads dominate. With larger amounts of data the PCI bus is the limiting factor.
figure semilogx(sizes,sendBandwidth,MarkerIndices=maxSendIdx,Marker="o") hold on semilogx(sizes,gatherBandwidth,MarkerIndices=maxGatherIdx,Marker="o") grid on title("Data Transfer Bandwidth") xlabel("Array size (bytes)") ylabel("Transfer speed (GB/s)") legend(["Send to GPU" "Gather from GPU"],Location="SouthEast") hold off
Measure Read and Write Speed During Memory Intensive Operations
Many operations do very little computation with each element of an array, so these operations are dominated by the time taken to fetch the data from memory or to write it back. Functions such as ones, zeros, nan, and true only write their output, whereas functions like transpose and tril both read and write but do no computation. Even simple operators like plus and minus do so little computation per element that they are bound only by the memory access speed.
The function plus performs one memory read and one memory write for each floating-point operation. As such, the function is limited by memory access speed and provides a good indicator of the speed of a read plus write operation.
Reset your GPU to clear its memory of GPU arrays allocated in the previous section.
reset(gpu)
Create a vector of sizes.
sizes = logspace(4.5,log10(maxSize),maxNumTests); sizes(sizes/sizeOfDouble > intmax) = [];
Measure the speed at which the GPU can read and write to GPU memory. Also measure the speed at which the host can read and write to host memory. For each array size in sizes:
Create random double-precision data on the GPU and on the host.
Use the
gputimeitfunction to time the execution of theplusfunction on the GPU.Use the
timeitfunction to time the execution of theplusfunction on the host.Divide the amount of data fetched and written by the measured time to determine the read and write bandwidth.
numTests = numel(sizes); numElements = floor(sizes/sizeOfDouble); memoryTimesGPU = inf(1,numTests); memoryTimesHost = inf(1,numTests); for idx=1:numTests disp("Test " + idx + " of " + numTests + ". Timing plus operation on GPU and CPU for arrays with " + numElements(idx) + " elements.") % Generate random data on GPU and host. gpuData = randi([0 9],numElements(idx),1,"gpuArray"); hostData = gather(gpuData); % Time the plus function on GPU. plusFcn = @() plus(gpuData,1.0); memoryTimesGPU(idx) = gputimeit(plusFcn); % Time the plus function on host. plusFcn = @() plus(hostData,1.0); memoryTimesHost(idx) = timeit(plusFcn); end
Test 1 of 15. Timing plus operation on GPU and CPU for arrays with 3952 elements. Test 2 of 15. Timing plus operation on GPU and CPU for arrays with 9426 elements. Test 3 of 15. Timing plus operation on GPU and CPU for arrays with 22479 elements. Test 4 of 15. Timing plus operation on GPU and CPU for arrays with 53606 elements. Test 5 of 15. Timing plus operation on GPU and CPU for arrays with 127835 elements. Test 6 of 15. Timing plus operation on GPU and CPU for arrays with 304851 elements. Test 7 of 15. Timing plus operation on GPU and CPU for arrays with 726981 elements. Test 8 of 15. Timing plus operation on GPU and CPU for arrays with 1733639 elements. Test 9 of 15. Timing plus operation on GPU and CPU for arrays with 4134226 elements. Test 10 of 15. Timing plus operation on GPU and CPU for arrays with 9858929 elements. Test 11 of 15. Timing plus operation on GPU and CPU for arrays with 23510685 elements. Test 12 of 15. Timing plus operation on GPU and CPU for arrays with 56066160 elements. Test 13 of 15. Timing plus operation on GPU and CPU for arrays with 133701518 elements. Test 14 of 15. Timing plus operation on GPU and CPU for arrays with 318839314 elements. Test 15 of 15. Timing plus operation on GPU and CPU for arrays with 760339221 elements.
memoryBandwidthGPU = 2*(sizes./memoryTimesGPU)/1e9; memoryBandwidthHost = 2*(sizes./memoryTimesHost)/1e9;
Determine the peak read and write speeds.
[maxBWGPU,maxBWIdxGPU] = max(memoryBandwidthGPU);
[maxBWHost,maxBWIdxHost] = max(memoryBandwidthHost);
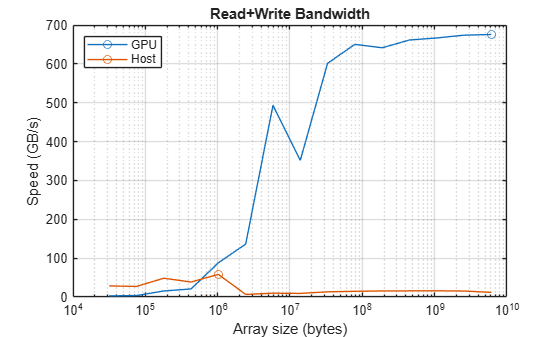
fprintf("Achieved peak read+write speed on the GPU: %.2f GB/s",maxBWGPU)Achieved peak read+write speed on the GPU: 675.63 GB/s
fprintf("Achieved peak read+write speed on the host: %.2f GB/s",maxBWHost)Achieved peak read+write speed on the host: 58.20 GB/s
Plot the read and write speeds against array size, and circle the peak for each case. Comparing this plot with the data-transfer plot above, it is clear that GPUs can typically read from and write to their memory much faster than they can get data from the host. So, it is important to minimize the number of host-GPU or GPU-host memory transfers. Ideally, programs should initially create data on the GPU. Otherwise, programs should transfer data to the GPU, then do as much as possible with the data while it is on the GPU before bringing the data back to the host only when complete.
figure semilogx(sizes,memoryBandwidthGPU,MarkerIndices=maxBWIdxGPU,Marker="o") hold on semilogx(sizes,memoryBandwidthHost,MarkerIndices=maxBWIdxHost,Marker="o") grid on title("Read+Write Bandwidth") xlabel("Array size (bytes)") ylabel("Speed (GB/s)") legend(["GPU" "Host"],Location="NorthWest") hold off
Measure Processing Power During Computationally Intensive Operations
Memory speed is less important for operations where there are a high number of floating-point computations per element read from or written to memory. These operations are said to have high computational density. In this case, the number and speed of the floating-point units is the limiting factor.
A good test of computational performance is a matrix-matrix multiply. For multiplying two matrices, the total number of floating-point calculations is
.
Two input matrices are read and one resulting matrix is written, for a total of elements read or written. This gives a computational density of (2N - 1)/3 FLOP/element. Contrast this with the plus function as used above, which has a computational density of 1/2 FLOP/element.
Reset your GPU to clear its memory of GPU arrays allocated in the previous section and create a vector of sizes.
reset(gpu) sizes = logspace(4,log10(maxSize)-1,maxNumTests); sizes(sizes/sizeOfDouble > intmax) = [];
Double Precision
MATLAB can perform calculations in double precision or single precision. Calculating in single precision instead of double precision can improve the performance of code running on your GPU, as most GPU cards are designed for graphics display, which demands a high single-precision performance. In contrast, CPUs are designed for general purpose computing and so do not provide this improvement when switching from double to single precision. For more information on converting data to single precision and performing arithmetic operations on single-precision data, see Floating-Point Numbers. Typical examples of workflows suitable for single-precision computation on the GPU include image processing and machine learning. However, other types of calculation, such as linear algebra problems, typically require double-precision processing.
For an approximate measure of the relative performance of your GPU in single precision compared to double precision, query the SingleDoubleRatio property of your device. This property describes the ratio of single- to double-precision floating-point units (FPUs) on the device. Most desktop GPUs have 24, 32, or even 64 times as many single-precision floating-point units as double-precision. Some GPUs also contain specialized cores that accelerate common deep learning operations. For example, Ampere architecture and later NVIDIA data center GPUs (A100 and H100) include Tensor Cores that can accelerate double-precision matrix multiplication. For these data center GPUs, the SingleDoubleRatio property might not accurately represent the relative performance in single precision compared to double precision for matrix multiplication.
gpu.SingleDoubleRatio
ans = 32
To measure the double-precision processing power, for each array size in sizes:
Create random double-precision data on the GPU and on the host.
Use the
gputimeitfunction to time the execution of theplusfunction on the GPU in single and double precision.Use the
timeitfunction to time the execution of theplusfunction on the host in single and double precision.Divide the amount of data fetched and written by the measured time to determine the read and write bandwidth.
numTests = numel(sizes); NDouble = floor(sqrt(sizes/sizeOfDouble)); mmTimesHostDouble = inf(1,numTests); mmTimesGPUDouble = inf(1,numTests); for idx=1:numTests disp("Test " + idx + " of " + numTests + ". Timing double-precision matrix-matrix multiplication with " + NDouble(idx)^2 + " elements.") % Generate random data on GPU. A = rand(NDouble(idx),"gpuArray"); B = rand(NDouble(idx),"gpuArray"); % Time the matrix multiplication on GPU. mmTimesGPUDouble(idx) = gputimeit(@() A*B); % Gather the data and time matrix multiplication on the host. A = gather(A); B = gather(B); mmTimesHostDouble(idx) = timeit(@() A*B); end
Test 1 of 15. Timing double-precision matrix-matrix multiplication with 1225 elements. Test 2 of 15. Timing double-precision matrix-matrix multiplication with 2704 elements. Test 3 of 15. Timing double-precision matrix-matrix multiplication with 5929 elements. Test 4 of 15. Timing double-precision matrix-matrix multiplication with 13225 elements. Test 5 of 15. Timing double-precision matrix-matrix multiplication with 28900 elements. Test 6 of 15. Timing double-precision matrix-matrix multiplication with 63504 elements. Test 7 of 15. Timing double-precision matrix-matrix multiplication with 139876 elements. Test 8 of 15. Timing double-precision matrix-matrix multiplication with 308025 elements. Test 9 of 15. Timing double-precision matrix-matrix multiplication with 675684 elements. Test 10 of 15. Timing double-precision matrix-matrix multiplication with 1485961 elements. Test 11 of 15. Timing double-precision matrix-matrix multiplication with 3265249 elements. Test 12 of 15. Timing double-precision matrix-matrix multiplication with 7171684 elements. Test 13 of 15. Timing double-precision matrix-matrix multiplication with 15752961 elements. Test 14 of 15. Timing double-precision matrix-matrix multiplication with 34609689 elements. Test 15 of 15. Timing double-precision matrix-matrix multiplication with 76020961 elements.
Determine the peak double-precision processing power.
mmFlopsHostDouble = (2*NDouble.^3 - NDouble.^2)./mmTimesHostDouble;
[maxFlopsHostDouble,maxFlopsHostDoubleIdx] = max(mmFlopsHostDouble);
mmFlopsGPUDouble = (2*NDouble.^3 - NDouble.^2)./mmTimesGPUDouble;
[maxFlopsGPUDouble,maxFlopsGPUDoubleIdx] = max(mmFlopsGPUDouble);
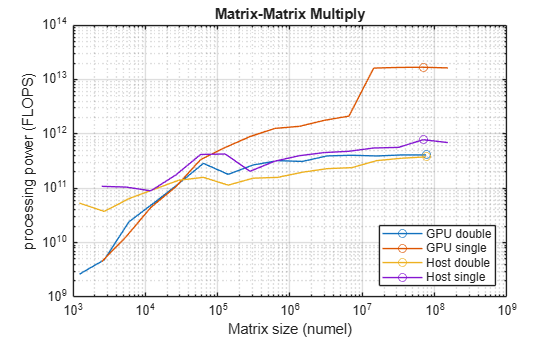
fprintf("Achieved peak double-precision processing power on the GPU: %.2f TFLOPS",maxFlopsGPUDouble/1e12)Achieved peak double-precision processing power on the GPU: 0.41 TFLOPS
fprintf("Achieved peak double-precision processing power on the host: %.2f TFLOPS",maxFlopsHostDouble/1e12)Achieved peak double-precision processing power on the host: 0.38 TFLOPS
Single Precision
You can convert data to single precision by using the single function, or by specifying single as the data type in a creation function such as zeros, ones, rand, and eye.
Measure the single-precision processing power. Generate single-precision random data using the rand function and specifying single as the data type.
NSingle = floor(sqrt(sizes/(sizeOfDouble/2))); mmTimesHostSingle = inf(1,numTests); mmTimesGPUSingle = inf(1,numTests); for idx=1:numTests disp("Test " + idx + " of " + numTests + ". Timing single-precision matrix-matrix multiplication with " + NSingle(idx)^2 + " elements.") % Generate random, single-precision data on GPU. A = rand(NSingle(idx),"single","gpuArray"); B = rand(NSingle(idx),"single","gpuArray"); % Time matrix multiplication on GPU. mmTimesGPUSingle(idx) = gputimeit(@() A*B); % Gather the data and time matrix multiplication on the host. A = gather(A); B = gather(B); mmTimesHostSingle(idx) = timeit(@() A*B); end
Test 1 of 15. Timing single-precision matrix-matrix multiplication with 2500 elements. Test 2 of 15. Timing single-precision matrix-matrix multiplication with 5476 elements. Test 3 of 15. Timing single-precision matrix-matrix multiplication with 11881 elements. Test 4 of 15. Timing single-precision matrix-matrix multiplication with 26244 elements. Test 5 of 15. Timing single-precision matrix-matrix multiplication with 58081 elements. Test 6 of 15. Timing single-precision matrix-matrix multiplication with 127449 elements. Test 7 of 15. Timing single-precision matrix-matrix multiplication with 279841 elements. Test 8 of 15. Timing single-precision matrix-matrix multiplication with 616225 elements. Test 9 of 15. Timing single-precision matrix-matrix multiplication with 1352569 elements. Test 10 of 15. Timing single-precision matrix-matrix multiplication with 2972176 elements. Test 11 of 15. Timing single-precision matrix-matrix multiplication with 6533136 elements. Test 12 of 15. Timing single-precision matrix-matrix multiplication with 14348944 elements. Test 13 of 15. Timing single-precision matrix-matrix multiplication with 31516996 elements. Test 14 of 15. Timing single-precision matrix-matrix multiplication with 69222400 elements. Test 15 of 15. Timing single-precision matrix-matrix multiplication with 152053561 elements.
Determine the peak single-precision processing power.
mmFlopsHostSingle = (2*NSingle.^3 - NSingle.^2)./mmTimesHostSingle;
[maxFlopsHostSingle,maxFlopsHostSingleIdx] = max(mmFlopsHostSingle);
mmFlopsGPUSingle = (2*NSingle.^3 - NSingle.^2)./mmTimesGPUSingle;
[maxFlopsGPUSingle,maxFlopsGPUSingleIdx] = max(mmFlopsGPUSingle);
fprintf("Achieved peak single-precision processing power on the GPU: %.2f TFLOPS",maxFlopsGPUSingle/1e12)Achieved peak single-precision processing power on the GPU: 16.74 TFLOPS
fprintf("Achieved peak single-precision processing power on the host: %.2f TFLOPS",maxFlopsHostSingle/1e12)Achieved peak single-precision processing power on the host: 0.78 TFLOPS
Plot the processing power against array size for double precision and single precision, and circle the peak for each case.
figure loglog(NDouble.^2,mmFlopsGPUDouble,MarkerIndices=maxFlopsGPUDoubleIdx,Marker="o") hold on loglog(NSingle.^2,mmFlopsGPUSingle,MarkerIndices=maxFlopsGPUSingleIdx,Marker="o") loglog(NDouble.^2,mmFlopsHostDouble,MarkerIndices=maxFlopsHostDoubleIdx,Marker="o") loglog(NSingle.^2,mmFlopsHostSingle,MarkerIndices=maxFlopsHostSingleIdx,Marker="o") grid on title("Matrix-Matrix Multiply") xlabel("Matrix size (numel)") ylabel("processing power (FLOPS)") legend(["GPU double" "GPU single" "Host double" "Host single"],Location="SouthEast") hold off
Conclusions
These tests reveal some important characteristics of GPU performance:
Transfers from host memory to GPU memory and back are relatively slow.
The GPU can read and write its memory much faster than the host CPU can read and write its memory.
Given large enough data, a GPU can perform calculations faster than the host CPU.
GPUs perform calculations faster in single precision than double precision, and often much faster.
It is notable that, in each test, large arrays were required for the GPU to outperform the host CPU. GPUs provide the greatest advantage when working with millions of elements at once.
For more detailed GPU benchmarks, including comparisons between different GPUs, see GPUBench on the MATLAB Central File Exchange.
See Also
gpuArray | gputimeit | gpuDevice | gpuDeviceTable