Increase Clock Frequency Using Clock-Rate Pipelining
This example shows how to apply clock-rate pipelining to optimize slow paths in your design and thereby reduce latency, increase clock frequency and decrease area usage. For more information on how to use clock-rate pipelining, see Clock-Rate Pipelining.
Introduction
Algorithmic design with Simulink® can introduce slow-rate datapaths in the generated HDL design. These paths correspond to slower Simulink sample time operations because the algorithmic data rate operates at a slower rate than the HDL clock rate.
Clock-rate pipelining identifies the maximal subregions in the model that operate at the same data rate and that are delimited either by rate-change blocks or Delay blocks. These subregions are called clock-rate regions because they are good candidates for clock-rate pipelining. If the output of a clock-rate region is a Delay block at the data rate, HDL Coder absorbs that Delay block, which results in a budget of several clock-rate pipelines equal to the ratio of data rate to the clock rate.
Consider the field-oriented control example Field-Oriented Control of a Permanent Magnet Synchronous Machine, which describes a motor-control design mapped to an FPGA. The input samples arrive every 20 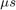 or 50 KHz. In a closed control loop, the controller latency must be within the desired response time. There is a delay on the output port that results in a latency of 20 .
or 50 KHz. In a closed control loop, the controller latency must be within the desired response time. There is a delay on the output port that results in a latency of 20 .
To meet design constraints like timing and area, you can apply several optimizations like input and output pipelining, distributed pipelining, streaming, and/or sharing. Additionally, you can implement non-trivial math functions like sqrt or divide as multi-cycle pipelined operations. Because the pipelines introduced by these optimizations are applied at the same rate at which the signal path operates, which is 20 , introducing additional pipelining creates undesirable latency overhead and can violate the closed loop latency budget.
However, the FPGA can implement this controller in the order of MHz, which means that the introduced pipelines can operate at the MHz rate and minimize the impact on latency. Clock-rate pipelining leverages this rate differential and pipelines the controller to improve its area and timing characteristics on the FPGA. This example shows how to incrementally apply timing and area optimizations using clock-rate pipelining.
Prepare the Model
Prepare the model so that it is ready for clock-rate pipelining.
Open the hdlcoderFocCurrentFixptHdl model, then define the rate differential. Signal paths in Simulink end up on slow paths in HDL either because the signal path operates at a slower sample time than the base sample time of the model, or because the Simulink base sample time corresponds to the data rate instead of the clock rate. The base sample time in this model is 20 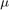 secs. The final FPGA implementation of the controller targets 40 MHz, or 25 ns.
secs. The final FPGA implementation of the controller targets 40 MHz, or 25 ns.
open_system('hdlcoderFocCurrentFixptHdl')

Setting the model sample time to 25 ns slows down Simulink simulation performance. HDL Coder can automatically determine how much faster the FPGA clock rate runs with respect to the Simulink base sample time when you select the configuration parameter Treat Simulink rates as actual hardware rates. In this case, HDL Coder calculates the oversampling value needed for your design by dividing the target frequency of the FPGA 40MHZ by the model base frequency 50KHz.
Set optimizations on subsystems. For fixed-point designs, HDL Coder applies clock-rate pipelining to subsystems only when it needs to insert pipelining. The HDL Coder options that introduce pipelining are distributed pipelining, sharing, streaming, input/output pipelining, constrained output pipeline, adaptive pipelining, and any block implementations that introduce multi-cycle implementations including floating point implementations. You can apply optimizations either locally, to maintain the subsystem hierarchies, or globally, if the underlying subsystems are flattened. In the local case, apply pipelining and optimization settings on individual subsystems. To apply global optimizations, set them on the top-level subsystem. For more information on prerequisites for hierarchy flattening, see Hierarchy Flattening.
Apply Clock-Rate Pipelining
Create a copy of the original model, hdlcoderFocCurrentFixptHdl, and save it as hdlcoderFocClockRatePipelining. In this example, you apply clock-rate pipelining optimizations to the new model and compare it to the original model.
srcHdlModel = 'hdlcoderFocCurrentFixptHdl'; dstHdlModel = 'hdlcoderFocClockRatePipelining'; dstHdlDut = [dstHdlModel '/FOC_Current_Control']; gmHdlModel = ['gm_' dstHdlModel]; gmHdlDut = ['gm_' dstHdlDut]; open_system(srcHdlModel); save_system(srcHdlModel,dstHdlModel);

The subsystem FOC_Current_Control that contains the algorithm for which HDL code is generated is the device under test (DUT). Open the DUT subsystem.
open_system(dstHdlDut);

Apply clock-rate pipelining. Clock-rate pipelining is enabled by default and automatically finds clock-rate regions when you generate HDL code. For more information, see Clock-Rate Pipelining.
hdlset_param(dstHdlModel, 'ClockRatePipelining', 'on');
Configure the model to increase clock speed by setting TargetFrequency to 40 MHz for the model, enabling TreatRatesAsHardwareRates to set an oversampling value for clock-rate pipelining, and enabling distributed pipelining for the model. The subsystems inherit the top-level distributed pipelining setting by default.
hdlset_param(dstHdlModel, 'TargetFrequency', 40); hdlset_param(dstHdlModel, 'TreatRatesAsHardwareRates', 'on'); hdlset_param(dstHdlModel, 'DistributedPipelining', 'on'); save_system(dstHdlModel);
To see the impact of clock-rate pipelining, generate HDL code and open the Code Generation report to the Clock-Rate Pipelining section.
makehdl(dstHdlDut);
### Working on the model <a href="matlab:open_system('hdlcoderFocClockRatePipelining')">hdlcoderFocClockRatePipelining</a>
### Generating HDL for <a href="matlab:open_system('hdlcoderFocClockRatePipelining/FOC_Current_Control')">hdlcoderFocClockRatePipelining/FOC_Current_Control</a>
### Using the config set for model <a href="matlab:configset.showParameterGroup('hdlcoderFocClockRatePipelining', { 'HDL Code Generation' } )">hdlcoderFocClockRatePipelining</a> for HDL code generation parameters.
### Running HDL checks on the model 'hdlcoderFocClockRatePipelining'.
### Begin compilation of the model 'hdlcoderFocClockRatePipelining'...
### Begin compilation of the model 'hdlcoderFocClockRatePipelining'...
### Working on the model 'hdlcoderFocClockRatePipelining'...
### Working on... <a href="matlab:configset.internal.open('hdlcoderFocClockRatePipelining', 'GenerateModel')">GenerateModel</a>
### Begin model generation 'gm_hdlcoderFocClockRatePipelining'...
### Rendering DUT with optimization related changes (IO, Area, Pipelining)...
### Model generation complete.
### Generated model saved at <a href="matlab:open_system('hdlsrc/hdlcoderFocClockRatePipelining/gm_hdlcoderFocClockRatePipelining.slx')">hdlsrc/hdlcoderFocClockRatePipelining/gm_hdlcoderFocClockRatePipelining.slx</a>
### Clock-rate pipelining obstacles can be diagnosed by running this script: <a href="matlab:run('hdlsrc/hdlcoderFocClockRatePipelining/highlightClockRatePipelining')">hdlsrc/hdlcoderFocClockRatePipelining/highlightClockRatePipelining.m</a>
### To highlight blocks that obstruct distributed pipelining, click the following MATLAB script: <a href="matlab:run('hdlsrc/hdlcoderFocClockRatePipelining/highlightDistributedPipeliningBarriers')">hdlsrc/hdlcoderFocClockRatePipelining/highlightDistributedPipeliningBarriers.m</a>
### To clear highlighting, click the following MATLAB script: <a href="matlab:run('hdlsrc/hdlcoderFocClockRatePipelining/clearhighlighting.m')">hdlsrc/hdlcoderFocClockRatePipelining/clearhighlighting.m</a>
### Generating new validation model: '<a href="matlab:open_system('hdlsrc/hdlcoderFocClockRatePipelining/gm_hdlcoderFocClockRatePipelining_vnl')">gm_hdlcoderFocClockRatePipelining_vnl</a>'.
### Validation model generation complete.
### Begin VHDL Code Generation for 'hdlcoderFocClockRatePipelining'.
### MESSAGE: The design requires 800 times faster clock with respect to the base rate = 2e-05.
### Begin VHDL Code Generation for 'FOC_Current_Control_tc'.
### Working on FOC_Current_Control_tc as hdlsrc/hdlcoderFocClockRatePipelining/FOC_Current_Control_tc.vhd.
### Code Generation for 'FOC_Current_Control_tc' completed.
### Working on hdlcoderFocClockRatePipelining/FOC_Current_Control/DQ_Current_Control/D_Current_Control/Saturate_Output as hdlsrc/hdlcoderFocClockRatePipelining/Saturate_Output.vhd.
### Working on hdlcoderFocClockRatePipelining/FOC_Current_Control/DQ_Current_Control/D_Current_Control as hdlsrc/hdlcoderFocClockRatePipelining/D_Current_Control.vhd.
### Working on hdlcoderFocClockRatePipelining/FOC_Current_Control/DQ_Current_Control as hdlsrc/hdlcoderFocClockRatePipelining/DQ_Current_Control.vhd.
### Working on hdlcoderFocClockRatePipelining/FOC_Current_Control/Clarke_Transform as hdlsrc/hdlcoderFocClockRatePipelining/Clarke_Transform.vhd.
### Working on hdlcoderFocClockRatePipelining/FOC_Current_Control/Park_Transform as hdlsrc/hdlcoderFocClockRatePipelining/Park_Transform.vhd.
### Working on hdlcoderFocClockRatePipelining/FOC_Current_Control/Sine_Cosine/Sine_Cosine_LUT as hdlsrc/hdlcoderFocClockRatePipelining/Sine_Cosine_LUT.vhd.
### Working on hdlcoderFocClockRatePipelining/FOC_Current_Control/Sine_Cosine as hdlsrc/hdlcoderFocClockRatePipelining/Sine_Cosine.vhd.
### Working on hdlcoderFocClockRatePipelining/FOC_Current_Control/Inverse_Park_Transform as hdlsrc/hdlcoderFocClockRatePipelining/Inverse_Park_Transform.vhd.
### Working on hdlcoderFocClockRatePipelining/FOC_Current_Control/Inverse_Clarke_Transform as hdlsrc/hdlcoderFocClockRatePipelining/Inverse_Clarke_Transform.vhd.
### Working on hdlcoderFocClockRatePipelining/FOC_Current_Control/Space_Vector_Modulation as hdlsrc/hdlcoderFocClockRatePipelining/Space_Vector_Modulation.vhd.
### Working on hdlcoderFocClockRatePipelining/FOC_Current_Control as hdlsrc/hdlcoderFocClockRatePipelining/FOC_Current_Control.vhd.
### Generating package file hdlsrc/hdlcoderFocClockRatePipelining/FOC_Current_Control_pkg.vhd.
### Code Generation for 'hdlcoderFocClockRatePipelining' completed.
### Generating HTML files for code generation report at <a href="matlab:hdlcoder.report.openReportV2Dialog('/tmp/Bdoc26a_3233028_1586746/tpae415596/hdlcoder-ex01953685/hdlsrc/hdlcoderFocClockRatePipelining', '/tmp/Bdoc26a_3233028_1586746/tpae415596/hdlcoder-ex01953685/hdlsrc/hdlcoderFocClockRatePipelining/html/index.html')">index.html</a>
### Creating HDL Code Generation Check Report file:///tmp/Bdoc26a_3233028_1586746/tpae415596/hdlcoder-ex01953685/hdlsrc/hdlcoderFocClockRatePipelining/FOC_Current_Control_report.html
### HDL check for 'hdlcoderFocClockRatePipelining' complete with 0 errors, 2 warnings, and 4 messages.
### HDL code generation complete.

In the Clock-Rate Pipelining section, under Detailed Report, there is a list of clock-rate pipelining obstacles. To remove the obstacles, you can apply the solutions listed in the report. For this example, disable the block parameter TreatAsAtomicUnit for both subsystems that are obstacles to treat the blocks in the subsystem as being at the same level in the model hierarchy as the subsystem. Clock-rate pipelining can then run across these subsystems and optimize your model.
set_param([dstHdlDut '/DQ_Current_Control/D_Current_Control'], 'TreatAsAtomicUnit', 'off'); set_param([dstHdlDut '/DQ_Current_Control/Q_Current_Control'], 'TreatAsAtomicUnit', 'off');
Generate HDL code and check the Clock-Rate Pipelining section of the Code Generation report to see that there are no longer clock-rate pipelining obstacles. For more information on the clock-rate pipelining section of the Code Generation report, see Clock-Rate Pipelining Report.
makehdl(dstHdlDut);
### Working on the model <a href="matlab:open_system('hdlcoderFocClockRatePipelining')">hdlcoderFocClockRatePipelining</a>
### Generating HDL for <a href="matlab:open_system('hdlcoderFocClockRatePipelining/FOC_Current_Control')">hdlcoderFocClockRatePipelining/FOC_Current_Control</a>
### Using the config set for model <a href="matlab:configset.showParameterGroup('hdlcoderFocClockRatePipelining', { 'HDL Code Generation' } )">hdlcoderFocClockRatePipelining</a> for HDL code generation parameters.
### Running HDL checks on the model 'hdlcoderFocClockRatePipelining'.
### Begin compilation of the model 'hdlcoderFocClockRatePipelining'...
### Begin compilation of the model 'hdlcoderFocClockRatePipelining'...
### Working on the model 'hdlcoderFocClockRatePipelining'...
### Working on... <a href="matlab:configset.internal.open('hdlcoderFocClockRatePipelining', 'GenerateModel')">GenerateModel</a>
### Begin model generation 'gm_hdlcoderFocClockRatePipelining'...
### Rendering DUT with optimization related changes (IO, Area, Pipelining)...
### Model generation complete.
### Generated model saved at <a href="matlab:open_system('hdlsrc/hdlcoderFocClockRatePipelining/gm_hdlcoderFocClockRatePipelining.slx')">hdlsrc/hdlcoderFocClockRatePipelining/gm_hdlcoderFocClockRatePipelining.slx</a>
### To highlight blocks that obstruct distributed pipelining, click the following MATLAB script: <a href="matlab:run('hdlsrc/hdlcoderFocClockRatePipelining/highlightDistributedPipeliningBarriers')">hdlsrc/hdlcoderFocClockRatePipelining/highlightDistributedPipeliningBarriers.m</a>
### To clear highlighting, click the following MATLAB script: <a href="matlab:run('hdlsrc/hdlcoderFocClockRatePipelining/clearhighlighting.m')">hdlsrc/hdlcoderFocClockRatePipelining/clearhighlighting.m</a>
### Generating new validation model: '<a href="matlab:open_system('hdlsrc/hdlcoderFocClockRatePipelining/gm_hdlcoderFocClockRatePipelining_vnl')">gm_hdlcoderFocClockRatePipelining_vnl</a>'.
### Validation model generation complete.
### Begin VHDL Code Generation for 'hdlcoderFocClockRatePipelining'.
### MESSAGE: The design requires 800 times faster clock with respect to the base rate = 2e-05.
### Begin VHDL Code Generation for 'FOC_Current_Control_tc'.
### Working on FOC_Current_Control_tc as hdlsrc/hdlcoderFocClockRatePipelining/FOC_Current_Control_tc.vhd.
### Code Generation for 'FOC_Current_Control_tc' completed.
### Working on hdlcoderFocClockRatePipelining/FOC_Current_Control/DQ_Current_Control/D_Current_Control/Saturate_Output as hdlsrc/hdlcoderFocClockRatePipelining/Saturate_Output.vhd.
### Working on hdlcoderFocClockRatePipelining/FOC_Current_Control/DQ_Current_Control/D_Current_Control as hdlsrc/hdlcoderFocClockRatePipelining/D_Current_Control.vhd.
### Working on hdlcoderFocClockRatePipelining/FOC_Current_Control/DQ_Current_Control/Q_Current_Control/Saturate_Output as hdlsrc/hdlcoderFocClockRatePipelining/Saturate_Output_block.vhd.
### Working on hdlcoderFocClockRatePipelining/FOC_Current_Control/DQ_Current_Control/Q_Current_Control as hdlsrc/hdlcoderFocClockRatePipelining/Q_Current_Control.vhd.
### Working on hdlcoderFocClockRatePipelining/FOC_Current_Control/DQ_Current_Control as hdlsrc/hdlcoderFocClockRatePipelining/DQ_Current_Control.vhd.
### Working on hdlcoderFocClockRatePipelining/FOC_Current_Control/Clarke_Transform as hdlsrc/hdlcoderFocClockRatePipelining/Clarke_Transform.vhd.
### Working on hdlcoderFocClockRatePipelining/FOC_Current_Control/Park_Transform as hdlsrc/hdlcoderFocClockRatePipelining/Park_Transform.vhd.
### Working on hdlcoderFocClockRatePipelining/FOC_Current_Control/Sine_Cosine/Sine_Cosine_LUT as hdlsrc/hdlcoderFocClockRatePipelining/Sine_Cosine_LUT.vhd.
### Working on hdlcoderFocClockRatePipelining/FOC_Current_Control/Sine_Cosine as hdlsrc/hdlcoderFocClockRatePipelining/Sine_Cosine.vhd.
### Working on hdlcoderFocClockRatePipelining/FOC_Current_Control/Inverse_Park_Transform as hdlsrc/hdlcoderFocClockRatePipelining/Inverse_Park_Transform.vhd.
### Working on hdlcoderFocClockRatePipelining/FOC_Current_Control/Inverse_Clarke_Transform as hdlsrc/hdlcoderFocClockRatePipelining/Inverse_Clarke_Transform.vhd.
### Working on hdlcoderFocClockRatePipelining/FOC_Current_Control/Space_Vector_Modulation as hdlsrc/hdlcoderFocClockRatePipelining/Space_Vector_Modulation.vhd.
### Working on hdlcoderFocClockRatePipelining/FOC_Current_Control as hdlsrc/hdlcoderFocClockRatePipelining/FOC_Current_Control.vhd.
### Generating package file hdlsrc/hdlcoderFocClockRatePipelining/FOC_Current_Control_pkg.vhd.
### Code Generation for 'hdlcoderFocClockRatePipelining' completed.
### Generating HTML files for code generation report at <a href="matlab:hdlcoder.report.openReportV2Dialog('/tmp/Bdoc26a_3233028_1586746/tpae415596/hdlcoder-ex01953685/hdlsrc/hdlcoderFocClockRatePipelining', '/tmp/Bdoc26a_3233028_1586746/tpae415596/hdlcoder-ex01953685/hdlsrc/hdlcoderFocClockRatePipelining/html/index.html')">index.html</a>
### Creating HDL Code Generation Check Report file:///tmp/Bdoc26a_3233028_1586746/tpae415596/hdlcoder-ex01953685/hdlsrc/hdlcoderFocClockRatePipelining/FOC_Current_Control_report.html
### HDL check for 'hdlcoderFocClockRatePipelining' complete with 0 errors, 2 warnings, and 3 messages.
### HDL code generation complete.
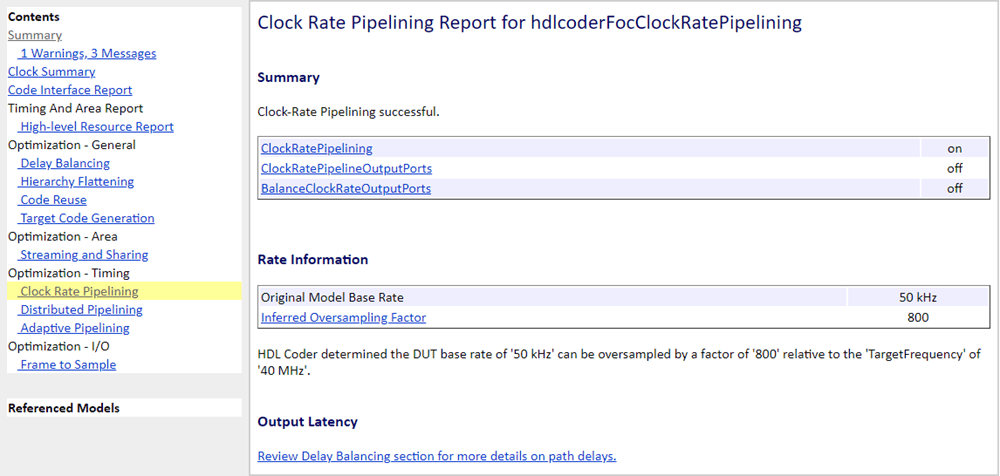
Look inside the top-level subsystem of the generated model. The generated model shows that the design has been clock-rate pipelined and is running at the fast rate. If there are subsystems in the generated model that are not clock-rate pipelined, then check if there were optimizations set on the subsystem in the original model.
open_system(gmHdlDut); set_param(gmHdlModel, 'SimulationCommand', 'update'); set_param(gmHdlDut, 'ZoomFactor', 'FitSystem');

Rate transitions are introduced on the design inputs to bring them to the clock rate, which is set by the target frequency, 1/40 MHz, or 25 ns. All pipelines are introduced at this rate and are operating at the clock rate. Finally, the output-side delay has been replaced by a down-sampling rate transition, which brings the signal back to the data rate. Compared to the original model, the pipelines inserted at the clock-rate improved the clock frequency of the new design, without incurring any additional sample time delays.
Verify that the functional behavior of the design is unchanged by using the validation model and co-simulation model. For more information, see Verification.
Apply Local Area Optimizations to Subsystems
The rate differential on the slow path implies that computation along this path can take several clock cycles. Specifically, the allowed latency is defined by the clock-rate budget. Apart from adding pipelines to improve clock frequency, you can reuse hardware resources by leveraging the latency budget. Apply resource sharing optimizations, such as setting the StreamingFactor and SharingFactor options in a slow-path region. This section demonstrates how resource sharing is applied within clock-rate regions.
When resource sharing is applied to a clock-rate path, HDL Coder oversamples the shared resource architecture for time-multiplexing as illustrated in Resource Sharing for Area Optimization. However, if sharing or streaming is requested in a slow datapath, then HDL Coder implements resource sharing without oversampling.
The Park_Transform subsystem and Inverse_Park_Transform subsystem each use four multipliers within them that can be potentially shared. Additionally, the Clarke_Transform subsystem and Inverse_Clarke_Transform subsystem each use two gains, which may be potentially shared, unless they are simply power-of-2 gains, which results in shifts instead of multiplications. As a result, the gain in Inverse_Clarke_Transform cannot be shared. Open the current model and highlight the subsystems where sharing can be applied.
srcHdlModel = 'hdlcoderFocClockRatePipelining'; dstHdlModel = 'hdlcoderFocSharing'; dstHdlDut = [dstHdlModel '/FOC_Current_Control']; gmHdlModel = ['gm_' dstHdlModel]; gmHdlDut = ['gm_' dstHdlDut]; open_system(srcHdlModel); save_system(srcHdlModel,dstHdlModel); open_system(dstHdlDut); hilite_system([dstHdlDut '/Park_Transform']); hilite_system([dstHdlDut '/Inverse_Park_Transform']); hilite_system([dstHdlDut '/Clarke_Transform']);

Set the sharing factors to the number of multipliers to share for each of the subsystems in order to apply resource sharing.
hdlset_param([dstHdlDut '/Park_Transform'], 'SharingFactor', 4); hdlset_param([dstHdlDut '/Inverse_Park_Transform'], 'SharingFactor', 4); hdlset_param([dstHdlDut '/Clarke_Transform'], 'SharingFactor', 2); save_system(dstHdlModel);
Generate HDL code using the makehdl command.
makehdl(dstHdlDut);
### Working on the model <a href="matlab:open_system('hdlcoderFocSharing')">hdlcoderFocSharing</a>
### Generating HDL for <a href="matlab:open_system('hdlcoderFocSharing/FOC_Current_Control')">hdlcoderFocSharing/FOC_Current_Control</a>
### Using the config set for model <a href="matlab:configset.showParameterGroup('hdlcoderFocSharing', { 'HDL Code Generation' } )">hdlcoderFocSharing</a> for HDL code generation parameters.
### Running HDL checks on the model 'hdlcoderFocSharing'.
### Begin compilation of the model 'hdlcoderFocSharing'...
### Begin compilation of the model 'hdlcoderFocSharing'...
### Working on the model 'hdlcoderFocSharing'...
### Working on... <a href="matlab:configset.internal.open('hdlcoderFocSharing', 'GenerateModel')">GenerateModel</a>
### Begin model generation 'gm_hdlcoderFocSharing'...
### Rendering DUT with optimization related changes (IO, Area, Pipelining)...
### Model generation complete.
### Generated model saved at <a href="matlab:open_system('hdlsrc/hdlcoderFocSharing/gm_hdlcoderFocSharing.slx')">hdlsrc/hdlcoderFocSharing/gm_hdlcoderFocSharing.slx</a>
### To highlight blocks that obstruct distributed pipelining, click the following MATLAB script: <a href="matlab:run('hdlsrc/hdlcoderFocSharing/highlightDistributedPipeliningBarriers')">hdlsrc/hdlcoderFocSharing/highlightDistributedPipeliningBarriers.m</a>
### To clear highlighting, click the following MATLAB script: <a href="matlab:run('hdlsrc/hdlcoderFocSharing/clearhighlighting.m')">hdlsrc/hdlcoderFocSharing/clearhighlighting.m</a>
### Generating new validation model: '<a href="matlab:open_system('hdlsrc/hdlcoderFocSharing/gm_hdlcoderFocSharing_vnl')">gm_hdlcoderFocSharing_vnl</a>'.
### Validation model generation complete.
### Begin VHDL Code Generation for 'hdlcoderFocSharing'.
### MESSAGE: The design requires 800 times faster clock with respect to the base rate = 2e-05.
### Begin VHDL Code Generation for 'FOC_Current_Control_tc'.
### Working on FOC_Current_Control_tc as hdlsrc/hdlcoderFocSharing/FOC_Current_Control_tc.vhd.
### Code Generation for 'FOC_Current_Control_tc' completed.
### Working on hdlcoderFocSharing/FOC_Current_Control/DQ_Current_Control/D_Current_Control/Saturate_Output as hdlsrc/hdlcoderFocSharing/Saturate_Output.vhd.
### Working on hdlcoderFocSharing/FOC_Current_Control/DQ_Current_Control/D_Current_Control as hdlsrc/hdlcoderFocSharing/D_Current_Control.vhd.
### Working on hdlcoderFocSharing/FOC_Current_Control/DQ_Current_Control/Q_Current_Control/Saturate_Output as hdlsrc/hdlcoderFocSharing/Saturate_Output_block.vhd.
### Working on hdlcoderFocSharing/FOC_Current_Control/DQ_Current_Control/Q_Current_Control as hdlsrc/hdlcoderFocSharing/Q_Current_Control.vhd.
### Working on hdlcoderFocSharing/FOC_Current_Control/DQ_Current_Control as hdlsrc/hdlcoderFocSharing/DQ_Current_Control.vhd.
### Working on hdlcoderFocSharing/FOC_Current_Control/Clarke_Transform as hdlsrc/hdlcoderFocSharing/Clarke_Transform.vhd.
### Working on hdlcoderFocSharing/FOC_Current_Control/Park_Transform as hdlsrc/hdlcoderFocSharing/Park_Transform.vhd.
### Working on hdlcoderFocSharing/FOC_Current_Control/Sine_Cosine/Sine_Cosine_LUT as hdlsrc/hdlcoderFocSharing/Sine_Cosine_LUT.vhd.
### Working on hdlcoderFocSharing/FOC_Current_Control/Sine_Cosine as hdlsrc/hdlcoderFocSharing/Sine_Cosine.vhd.
### Working on hdlcoderFocSharing/FOC_Current_Control/Inverse_Park_Transform as hdlsrc/hdlcoderFocSharing/Inverse_Park_Transform.vhd.
### Working on hdlcoderFocSharing/FOC_Current_Control/Inverse_Clarke_Transform as hdlsrc/hdlcoderFocSharing/Inverse_Clarke_Transform.vhd.
### Working on hdlcoderFocSharing/FOC_Current_Control/Space_Vector_Modulation as hdlsrc/hdlcoderFocSharing/Space_Vector_Modulation.vhd.
### Working on hdlcoderFocSharing/FOC_Current_Control as hdlsrc/hdlcoderFocSharing/FOC_Current_Control.vhd.
### Generating package file hdlsrc/hdlcoderFocSharing/FOC_Current_Control_pkg.vhd.
### Code Generation for 'hdlcoderFocSharing' completed.
### Generating HTML files for code generation report at <a href="matlab:hdlcoder.report.openReportV2Dialog('/tmp/Bdoc26a_3233028_1586746/tpae415596/hdlcoder-ex01953685/hdlsrc/hdlcoderFocSharing', '/tmp/Bdoc26a_3233028_1586746/tpae415596/hdlcoder-ex01953685/hdlsrc/hdlcoderFocSharing/html/index.html')">index.html</a>
### Creating HDL Code Generation Check Report file:///tmp/Bdoc26a_3233028_1586746/tpae415596/hdlcoder-ex01953685/hdlsrc/hdlcoderFocSharing/FOC_Current_Control_report.html
### HDL check for 'hdlcoderFocSharing' complete with 0 errors, 2 warnings, and 3 messages.
### HDL code generation complete.
Review the generated model and observe that HDL Coder implements time-multiplexing at the clock rate using knowledge of the available latency budget due to the slow datapath.
load_system(gmHdlDut); set_param(gmHdlModel, 'SimulationCommand', 'update'); set_param(gmHdlDut, 'ZoomFactor', 'FitSystem'); hilite_system([gmHdlDut '/ctr_0_799']); hilite_system([gmHdlDut '/Clarke_Transform/Clarke_Transform_shared']); hilite_system([gmHdlDut '/Park_Transform/Park_Transform_shared']); hilite_system([gmHdlDut '/Inverse_Park_Transform/Inverse_Park_Transform_shared']); open_system(gmHdlDut); Simulink.BlockDiagram.arrangeSystem(gmHdlDut);

The time-multiplexing architecture, also known as the single-rate sharing architecture is described in Single-Rate Resource Sharing Architecture. A global scheduler is created to enable and disable different regions of the design using enabled subsystems. The enable/disable control is implemented using a Limited Counter block ctr_0_799 that counts to the latency budget (0 to 799). The shared regions are implemented as enabled subsystems that are enabled according to an automatically determined schedule order. In this design, there are two subsystems containing groups of multipliers that are shared in four places and one subsystem containing a group of multipliers that are shared in two places. As a result of resource sharing, the multiplier count for the design has reduced from 20 to 13 without any latency penalties.
Apply Global Optimizations by Flattening the Model
Global cross-subsystem optimizations can be applied by leveraging the subsystem-flattening feature. With flattening, there are more number of resources that can be shared at the same level of hierarchy. To trigger such sharing, set either sharing or streaming on the top-level subsystem. The sharing factor value chosen must be an upper bound. To determine a good value, the resource usage of the design must be analyzed.
srcHdlModel = 'hdlcoderFocCurrentFixptHdl'; dstHdlModel = 'hdlcoderFocSharingWithFlattening'; dstHdlDut = [dstHdlModel '/FOC_Current_Control']; gmHdlModel = ['gm_' dstHdlModel]; gmHdlDut = ['gm_' dstHdlDut]; open_system(srcHdlModel); save_system(srcHdlModel,dstHdlModel); open_system(dstHdlDut); hdlset_param(dstHdlModel, 'ClockRatePipelining', 'on'); hdlset_param(dstHdlModel, 'TargetFrequency', 40); hdlset_param(dstHdlModel, 'TreatRatesAsHardwareRates', 'on'); hdlset_param(dstHdlModel, 'DistributedPipelining', 'on'); hdlset_param(dstHdlDut, 'FlattenHierarchy', 'on'); hilite_system([dstHdlDut '/Park_Transform']); hilite_system([dstHdlDut '/Inverse_Park_Transform']); hilite_system([dstHdlDut '/Clarke_Transform']); hilite_system([dstHdlDut '/Inverse_Clarke_Transform']);

The Park_Transform subsystem and the Inverse_Park_Transform subsystem each use four multipliers within them that can be potentially shared. Additionally, the Clarke_Transform subsystem and the Inverse_Clarke_Transform subsystem each use two gains, which may be potentially shared, unless they are simply power-of-2 gains, which results in shifts instead of multiplications. Choose the upper-bound value of four as the SharingFactor and generate HDL code.
hdlset_param(dstHdlDut, 'SharingFactor', 4);
save_system(dstHdlModel);
makehdl(dstHdlDut);
### Working on the model <a href="matlab:open_system('hdlcoderFocSharingWithFlattening')">hdlcoderFocSharingWithFlattening</a>
### Generating HDL for <a href="matlab:open_system('hdlcoderFocSharingWithFlattening/FOC_Current_Control')">hdlcoderFocSharingWithFlattening/FOC_Current_Control</a>
### Using the config set for model <a href="matlab:configset.showParameterGroup('hdlcoderFocSharingWithFlattening', { 'HDL Code Generation' } )">hdlcoderFocSharingWithFlattening</a> for HDL code generation parameters.
### Running HDL checks on the model 'hdlcoderFocSharingWithFlattening'.
### Begin compilation of the model 'hdlcoderFocSharingWithFlattening'...
### Begin compilation of the model 'hdlcoderFocSharingWithFlattening'...
### Working on the model 'hdlcoderFocSharingWithFlattening'...
### Working on... <a href="matlab:configset.internal.open('hdlcoderFocSharingWithFlattening', 'GenerateModel')">GenerateModel</a>
### Begin model generation 'gm_hdlcoderFocSharingWithFlattening'...
### Rendering DUT with optimization related changes (IO, Area, Pipelining)...
### Model generation complete.
### Generated model saved at <a href="matlab:open_system('hdlsrc/hdlcoderFocSharingWithFlattening/gm_hdlcoderFocSharingWithFlattening.slx')">hdlsrc/hdlcoderFocSharingWithFlattening/gm_hdlcoderFocSharingWithFlattening.slx</a>
### To highlight blocks that obstruct distributed pipelining, click the following MATLAB script: <a href="matlab:run('hdlsrc/hdlcoderFocSharingWithFlattening/highlightDistributedPipeliningBarriers')">hdlsrc/hdlcoderFocSharingWithFlattening/highlightDistributedPipeliningBarriers.m</a>
### To clear highlighting, click the following MATLAB script: <a href="matlab:run('hdlsrc/hdlcoderFocSharingWithFlattening/clearhighlighting.m')">hdlsrc/hdlcoderFocSharingWithFlattening/clearhighlighting.m</a>
### Generating new validation model: '<a href="matlab:open_system('hdlsrc/hdlcoderFocSharingWithFlattening/gm_hdlcoderFocSharingWithFlattening_vnl')">gm_hdlcoderFocSharingWithFlattening_vnl</a>'.
### Validation model generation complete.
### Begin VHDL Code Generation for 'hdlcoderFocSharingWithFlattening'.
### MESSAGE: The design requires 800 times faster clock with respect to the base rate = 2e-05.
### Begin VHDL Code Generation for 'FOC_Current_Control_tc'.
### Working on FOC_Current_Control_tc as hdlsrc/hdlcoderFocSharingWithFlattening/FOC_Current_Control_tc.vhd.
### Code Generation for 'FOC_Current_Control_tc' completed.
### Working on hdlcoderFocSharingWithFlattening/FOC_Current_Control as hdlsrc/hdlcoderFocSharingWithFlattening/FOC_Current_Control.vhd.
### Generating package file hdlsrc/hdlcoderFocSharingWithFlattening/FOC_Current_Control_pkg.vhd.
### Code Generation for 'hdlcoderFocSharingWithFlattening' completed.
### Generating HTML files for code generation report at <a href="matlab:hdlcoder.report.openReportV2Dialog('/tmp/Bdoc26a_3233028_1586746/tpae415596/hdlcoder-ex01953685/hdlsrc/hdlcoderFocSharingWithFlattening', '/tmp/Bdoc26a_3233028_1586746/tpae415596/hdlcoder-ex01953685/hdlsrc/hdlcoderFocSharingWithFlattening/html/index.html')">index.html</a>
### Creating HDL Code Generation Check Report file:///tmp/Bdoc26a_3233028_1586746/tpae415596/hdlcoder-ex01953685/hdlsrc/hdlcoderFocSharingWithFlattening/FOC_Current_Control_report.html
### HDL check for 'hdlcoderFocSharingWithFlattening' complete with 0 errors, 2 warnings, and 3 messages.
### HDL code generation complete.
Review the generated model and observe that HDL Coder implements time-multiplexing at the clock rate using knowledge of the available latency budget due to the slow datapath.
open_system(gmHdlDut); set_param(gmHdlModel, 'SimulationCommand', 'update'); set_param(gmHdlDut, 'ZoomFactor', 'FitSystem'); hilite_system([gmHdlDut '/ctr_0_799']); hilite_system([gmHdlDut '/crp_temp_shared']); hilite_system([gmHdlDut '/crp_temp_shared1']); hilite_system([gmHdlDut '/crp_temp_shared2']); hilite_system([gmHdlDut '/crp_temp_shared3']); hilite_system([gmHdlDut '/crp_temp_shared4']);

In this design, there are five subsystems containing groups of multipliers that are shared in four places or less across the model. These five subsystems have crp_temp_shared as part of their names.
In summary, with the design flattened, the multiplier count for the design has reduced from 20 to 7 without any latency penalties.
Minimize Latency
As an advanced maneuver, it is possible to reduce the output latency by removing the output Delay_Register and instead using the option to allow clock-rate pipelining of DUT output ports.
Create a new model as a copy of the hdlcoderFocSharing model and remove the output Delay_Register.
srcHdlModel = 'hdlcoderFocSharing'; dstHdlModel = 'hdlcoderFocMinLatency'; dstHdlDut = [dstHdlModel '/FOC_Current_Control']; gmHdlModel = ['gm_' dstHdlModel]; gmHdlDut = ['gm_' dstHdlDut]; open_system(srcHdlModel); save_system(srcHdlModel,dstHdlModel); delete_line(dstHdlDut,'Space_Vector_Modulation/1','Delay_Register/1'); delete_line(dstHdlDut,'Delay_Register/1','Phase_Voltage/1'); delete_block([dstHdlDut,'/Delay_Register']) add_line(dstHdlDut,'Space_Vector_Modulation/1','Phase_Voltage/1'); open_system(dstHdlDut);

The clock-rate pipelining for output ports option is available in the configuration parameters dialog box under the HDL Code Generation > Optimization > Pipelining tab: check the Allow clock-rate pipelining of DUT output ports option. The command-line property name for this option is ClockRatePipelineOutputPorts. When the ClockRatePipelineOutputPorts option is turned on and the output register is removed, the generated HDL code does not wait for the full sample step to generate the output. It instead generates the output within a few clock cycles as soon as the data is ready. The generated HDL code generates the output at the clock rate without waiting for the next sample step.
hdlset_param(dstHdlModel, 'ClockRatePipelineOutputPorts', 'on'); save_system(dstHdlModel); makehdl(dstHdlDut);
### Working on the model <a href="matlab:open_system('hdlcoderFocMinLatency')">hdlcoderFocMinLatency</a>
### Generating HDL for <a href="matlab:open_system('hdlcoderFocMinLatency/FOC_Current_Control')">hdlcoderFocMinLatency/FOC_Current_Control</a>
### Using the config set for model <a href="matlab:configset.showParameterGroup('hdlcoderFocMinLatency', { 'HDL Code Generation' } )">hdlcoderFocMinLatency</a> for HDL code generation parameters.
### Running HDL checks on the model 'hdlcoderFocMinLatency'.
### Begin compilation of the model 'hdlcoderFocMinLatency'...
### Begin compilation of the model 'hdlcoderFocMinLatency'...
### Working on the model 'hdlcoderFocMinLatency'...
### Clock-rate pipelining was applied on signals connected to the DUT's output ports. The DUT output port values are therefore updated at the clock-rate. The following ports are phase-offset by the stated number of clock cycles.
### Phase of output port 1: 13 clock cycles.
### Working on... <a href="matlab:configset.internal.open('hdlcoderFocMinLatency', 'GenerateModel')">GenerateModel</a>
### Begin model generation 'gm_hdlcoderFocMinLatency'...
### Rendering DUT with optimization related changes (IO, Area, Pipelining)...
### Model generation complete.
### Generated model saved at <a href="matlab:open_system('hdlsrc/hdlcoderFocMinLatency/gm_hdlcoderFocMinLatency.slx')">hdlsrc/hdlcoderFocMinLatency/gm_hdlcoderFocMinLatency.slx</a>
### To highlight blocks that obstruct distributed pipelining, click the following MATLAB script: <a href="matlab:run('hdlsrc/hdlcoderFocMinLatency/highlightDistributedPipeliningBarriers')">hdlsrc/hdlcoderFocMinLatency/highlightDistributedPipeliningBarriers.m</a>
### To clear highlighting, click the following MATLAB script: <a href="matlab:run('hdlsrc/hdlcoderFocMinLatency/clearhighlighting.m')">hdlsrc/hdlcoderFocMinLatency/clearhighlighting.m</a>
### Generating new validation model: '<a href="matlab:open_system('hdlsrc/hdlcoderFocMinLatency/gm_hdlcoderFocMinLatency_vnl')">gm_hdlcoderFocMinLatency_vnl</a>'.
### Validation model generation complete.
### Begin VHDL Code Generation for 'hdlcoderFocMinLatency'.
### MESSAGE: The design requires 800 times faster clock with respect to the base rate = 2e-05.
### Begin VHDL Code Generation for 'FOC_Current_Control_tc'.
### Working on FOC_Current_Control_tc as hdlsrc/hdlcoderFocMinLatency/FOC_Current_Control_tc.vhd.
### Code Generation for 'FOC_Current_Control_tc' completed.
### Working on hdlcoderFocMinLatency/FOC_Current_Control/Clarke_Transform as hdlsrc/hdlcoderFocMinLatency/Clarke_Transform.vhd.
### Working on hdlcoderFocMinLatency/FOC_Current_Control/DQ_Current_Control/D_Current_Control/Saturate_Output as hdlsrc/hdlcoderFocMinLatency/Saturate_Output.vhd.
### Working on hdlcoderFocMinLatency/FOC_Current_Control/DQ_Current_Control/D_Current_Control as hdlsrc/hdlcoderFocMinLatency/D_Current_Control.vhd.
### Working on hdlcoderFocMinLatency/FOC_Current_Control/DQ_Current_Control/Q_Current_Control/Saturate_Output as hdlsrc/hdlcoderFocMinLatency/Saturate_Output_block.vhd.
### Working on hdlcoderFocMinLatency/FOC_Current_Control/DQ_Current_Control/Q_Current_Control as hdlsrc/hdlcoderFocMinLatency/Q_Current_Control.vhd.
### Working on hdlcoderFocMinLatency/FOC_Current_Control/DQ_Current_Control as hdlsrc/hdlcoderFocMinLatency/DQ_Current_Control.vhd.
### Working on hdlcoderFocMinLatency/FOC_Current_Control/Inverse_Clarke_Transform as hdlsrc/hdlcoderFocMinLatency/Inverse_Clarke_Transform.vhd.
### Working on hdlcoderFocMinLatency/FOC_Current_Control/Inverse_Park_Transform as hdlsrc/hdlcoderFocMinLatency/Inverse_Park_Transform.vhd.
### Working on hdlcoderFocMinLatency/FOC_Current_Control/Park_Transform as hdlsrc/hdlcoderFocMinLatency/Park_Transform.vhd.
### Working on hdlcoderFocMinLatency/FOC_Current_Control/Sine_Cosine/Sine_Cosine_LUT as hdlsrc/hdlcoderFocMinLatency/Sine_Cosine_LUT.vhd.
### Working on hdlcoderFocMinLatency/FOC_Current_Control/Sine_Cosine as hdlsrc/hdlcoderFocMinLatency/Sine_Cosine.vhd.
### Working on hdlcoderFocMinLatency/FOC_Current_Control/Space_Vector_Modulation as hdlsrc/hdlcoderFocMinLatency/Space_Vector_Modulation.vhd.
### Working on hdlcoderFocMinLatency/FOC_Current_Control as hdlsrc/hdlcoderFocMinLatency/FOC_Current_Control.vhd.
### Generating package file hdlsrc/hdlcoderFocMinLatency/FOC_Current_Control_pkg.vhd.
### Code Generation for 'hdlcoderFocMinLatency' completed.
### Generating HTML files for code generation report at <a href="matlab:hdlcoder.report.openReportV2Dialog('/tmp/Bdoc26a_3233028_1586746/tpae415596/hdlcoder-ex01953685/hdlsrc/hdlcoderFocMinLatency', '/tmp/Bdoc26a_3233028_1586746/tpae415596/hdlcoder-ex01953685/hdlsrc/hdlcoderFocMinLatency/html/index.html')">index.html</a>
### Creating HDL Code Generation Check Report file:///tmp/Bdoc26a_3233028_1586746/tpae415596/hdlcoder-ex01953685/hdlsrc/hdlcoderFocMinLatency/FOC_Current_Control_report.html
### HDL check for 'hdlcoderFocMinLatency' complete with 0 errors, 2 warnings, and 3 messages.
### HDL code generation complete.
Notice that the makehdl command has generated a message, ### Phase of output port 1:, explaining how to sample the DUT outputs. The number of clock cycles specified in this message is how quickly the DUT outputs can be sampled and, in essence, is the latency of the design. The total latency of the design is down from a data-rate sample step of 20 to a few nanoseconds.
Review the generated model to observe that a new DUT subsystem is created whose output operates at the clock rate, which is 25 ns.
open_system(gmHdlDut); set_param(gmHdlModel, 'SimulationCommand', 'update'); set_param(gmHdlDut, 'ZoomFactor', 'FitSystem');

This option introduces additional latency into the generated HDL code that was not in the original simulation model. In doing this, the sample time of the output port has changed to the clock rate. This introduces a possible discrepancy in results during the validation and verification flow since the test-harness expects the design to generate outputs at the data rate. The validation model addresses this problem by inserting a down-sampling rate-transition to bring the output back to the data rate. Thus, the validation model still compares outputs at the data rate. The HDL testbench compares the new DUT outputs at the clock rate because the generated HDL outputs are emitted at the clock rate.
Summary
Clock-rate pipelining is a technique to optimize and pipeline slow paths in your design. Clock-rate pipelining ensures that pipelines are introduced at the clock rate for these HDL Coder constructs and optimizations:
Pipelined math operations: Several math blocks implement a multi-cycle, pipelined HDL implementation, e.g., Newton-Rhapson method for sqrt or recip, Cordic algorithm for trigonometric functions. These pipelines are introduced at clock rate if the block operates on a slow path.
Floating point mapping: As described above, floating point library mapping utilizes clock-rate pipelines when implementing floating point math.
Pipelining optimizations: All pipelining optimizations including input/output pipelining, adaptive pipelining and distributed pipelining use clock-rate registers on slow paths.
Resource sharing and streaming: Time-multiplexing of resource-shared architectures are implemented at the clock rate.
Slow paths are identified as paths using a slower Simulink sample time or when the oversampling value is greater than one. Using clock-rate pipelining, the design speed and area properties can be improved without compromising the total latency of the design.