Erkennen von Übersteuern bei BMW-Automobilen mit Machine Learning
Von Tobias Freudling, BMW Group
Das Übersteuern ist ein unsicherer Zustand, in dem die Hinterräder eines Fahrzeugs in einer Kurve die Bodenhaftung verlieren (Abbildung 1). Sie kann durch abgefahrene Reifen, eine rutschige Fahrbahn, zu schnelles Durchfahren einer Kurve, abruptes Bremsen in einer Kurve oder eine Kombination dieser Faktoren entstehen.

Abbildung 1: Übersteuern eines BMW M4 auf einer Teststrecke.
Moderne Fahrdynamikregelungen sind so entworfen, dass sie bei erkanntem Übersteuern automatisch Korrekturmaßnahmen einleiten. Theoretisch können solche Systeme Übersteuern mithilfe von Modellen identifizieren, die auf grundlegender Mathematik basieren. Wenn beispielsweise Messwerte von Sensoren des Fahrzeugs festgelegte Schwellenwerte für Parameter des Modells überschreiten, erkennt das System, dass das Fahrzeug übersteuert. In der Praxis hat sich jedoch gezeigt, dass dieser Ansatz schwer zu implementieren ist, weil das Zusammenspiel der zahlreichen beteiligten Faktoren zu komplex ist. Ein Auto mit zu geringem Reifendruck auf einer vereisten Straße kann ganz andere Schwellenwerte benötigen als dasselbe Fahrzeug mit ordnungsgemäß befüllten Reifen auf einer trockenen Fahrbahn.
Bei BMW untersuchen wir einen Machine-Learning-Ansatz für das Erkennen von Übersteuern. Mithilfe von MATLAB® haben wir ein Modell mit überwachtem Machine Learning als Machbarkeitsnachweis entwickelt. Obwohl wir kaum Vorerfahrung mit Machine Learning hatten, erstellten wir in nur drei Wochen einen funktionierenden Prototyp für ein Motorsteuergerät (Engine Control Unit, ECU), der Übersteuern mit mehr als 98 % Genauigkeit erkennt.
Erfassen von Daten und Extrahieren von Merkmalen
Als Erstes erfassten wir reale Daten von einem Fahrzeug vor, während und nach dem Übersteuern. Unterstützt durch einen professionellen Testfahrer führten wir echte Fahrversuche in einem BMW M4 auf dem BMW-Testgelände in Miramas, Frankreich, durch (Abbildung 2).

Abbildung 2: Das BMW-Testgelände in Miramas, Frankreich.
Während der Tests erfassten wir Signale, die von Algorithmen für die Übersteuererkennung üblicherweise verwendet werden: die Vorwärtsbeschleunigung, die Querbeschleunigung, den Lenkwinkel und die Gierrate des Fahrzeugs. Außerdem protokollierten wir die Wahrnehmung des Übersteuerns durch den Fahrer: Wenn der Fahrer mitteilte, dass das Auto gerade übersteuerte, drückte meine mitfahrende Kollegin eine Taste auf ihrem Laptop. Sie ließ wieder los, wenn der Fahrer mitteilte, dass das Auto sich wieder normal verhielt. Aus diesen Tastendrücken erstellten wir die Ground-Truth-Kennzeichnungen, die zum Trainieren eines Modells mit überwachtem Lernen notwendig sind. Insgesamt erfassten wir ungefähr 259.000 Einzeldaten in 43 Minuten aufgezeichneter Daten.
Zurück an unserem Arbeitsort in München lasen wir die erfassten Daten in MATLAB ein und verwendeten die Classification Learner-App in der Statistics and Machine Learning Toolbox™, um Machine-Learning-Modelle mit einer Reihe von Klassifikatoren zu trainieren. Die Ergebnisse der Modelle, die wir anhand dieser Rohdaten trainierten, waren nicht besonders gut – die Genauigkeit lag zwischen 75 % und 80 %. Um genauere Ergebnisse zu erzielen, bereinigten und reduzierten wir die Rohdaten. Zuerst wendeten wir Filter an, um Rauschen in den Signaldaten zu reduzieren (Abbildung 3).
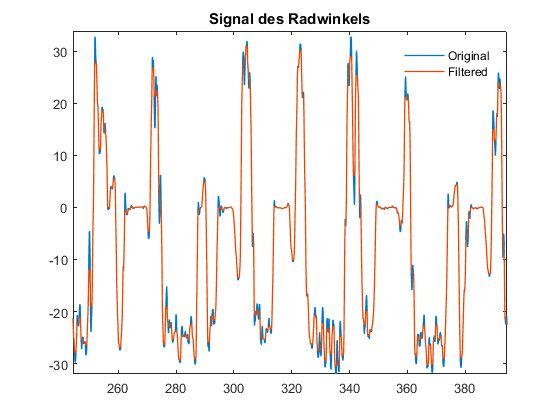
Abbildung 3: Das ursprüngliche Lenkwinkelsignal (blau) und dasselbe Signal nach dem Filtern (orange).
Als Nächstes identifizierten wir mit einer Peak-Analyse die Spitzen (lokalen Maxima) unserer gefilterten Eingangssignale (Abbildung 4).
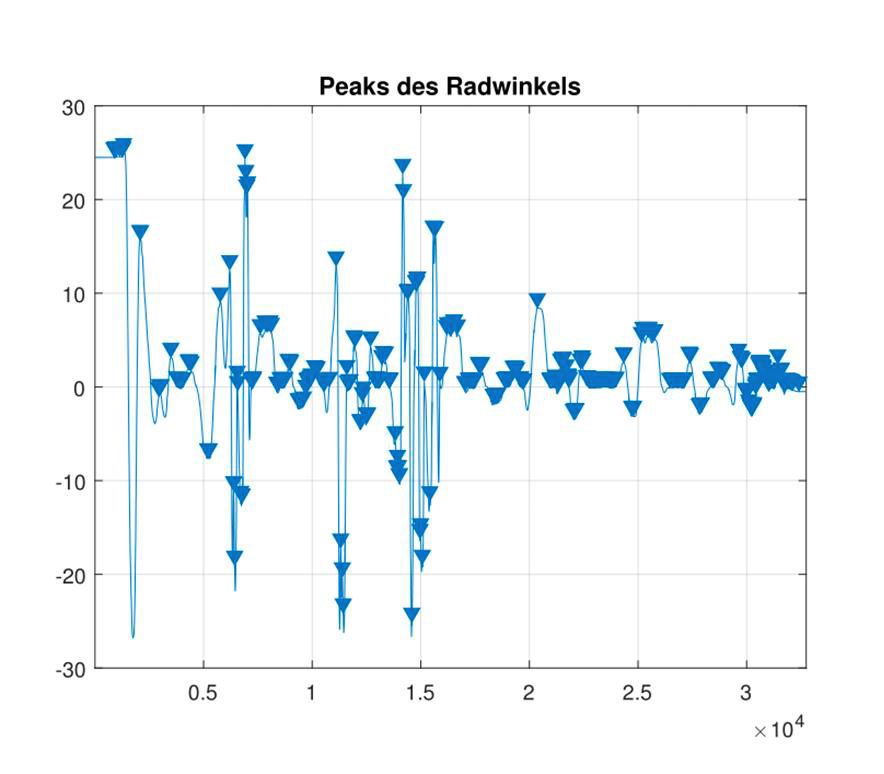
Abbildung 4: Das Lenkwinkelsignal mit identifizierten Spitzen.
Bewertung von Machine-Learning-Ansätzen
Nachdem wir die erfassten Daten gefiltert und reduziert hatten, konnten wir Ansätze mit überwachtem Machine Learning besser bewerten. Mit der Classification Learner-App probierten wir KNN-Klassifikatoren (k-Nearest Neighbor), SVMs (Support Vector Machines), eine quadratische Diskriminanzanalyse und Entscheidungsbäume aus. Außerdem verwendeten wir die App, um die Auswirkungen von Merkmalstransformationen mit einer Hauptkomponentenanalyse (Principal Component Analysis, PCA) zu betrachten.
Die Ergebnisse, die wir mit den bewerteten Klassifikatoren erhielten, sind in Tabelle 1 zusammengefasst. Alle Klassifikatoren identifizierten Übersteuern gut und drei von ihnen erreichten Richtig-positiv-Raten von mehr als 98 %. Der entscheidende Faktor waren die Richtig-negativ-Raten, also wie genau der Klassifikator ermitteln konnte, wann das Fahrzeug nicht übersteuerte. Hier waren Entscheidungsbäume besser als die anderen Klassifikatoren, mit einer Richtig-negativ-Rate von fast 96 %.
| Richtig positiv (%) | Richtig negativ (%) | Falsch positiv (%) | Falsch negativ (%) | |
| K-Nearest Neighbor mit PCA |
94,74 | 90,35 | 5,26 | 9,65 |
| Support Vector Machine | 98,92 | 73,07 | 1,08 | 26,93 |
| Quadratische Diskriminanzanalyse |
98,83 | 82,73 | 1,17 | 17,27 |
| Entscheidungsbäume |
98,16 | 95,86 | 1,84 | 4,14 |
Generieren von Code für Tests im Fahrzeug
Die mit dem Entscheidungsbaum erzielten Ergebnisse waren vielversprechend, aber wirklich ausschlaggebend würde die Leistung des Klassifikators für ein Steuergerät in einem echten Auto sein. Wir generierten mit MATLAB Coder™ Code aus dem Modell und kompilierten ihn für unsere Ziel-ECU, die in eine BMW 5er Limousine eingebaut war. Dieses Mal führten wir die Tests selbst auf dem BMW-Messgelände Aschheim in der Nähe unseres Arbeitsorts durch. Während ich fuhr, sammelte meine Kollegin Daten und protokollierte genau die Zeitpunkte, zu denen ich ein Übersteuern meldete.
Bei Ausführung in Echtzeit auf der ECU war die Leistung des Klassifikators überraschend hoch: Seine Genauigkeit lag bei etwa 95 %. Als wir mit den Tests begannen, wussten wir nicht, was wir erwarten sollten, weil wir ein anderes Fahrzeug verwendeten (einen BMW der 5er Reihe statt eines M4), eine andere Person fuhr und ein anderes Gelände genutzt wurde. Eine genauere Betrachtung der Daten zeigte, dass die meisten Abweichungen zwischen dem Modell und dem vom Fahrer wahrgenommenen Übersteuern um Anfang und Ende des Übersteuerns herum auftraten. Diese Abweichung ist verständlich; es kann sogar für den Fahrer selbst schwer zu erkennen sein, wann das Übersteuern beginnt und endet.
Nachdem wir erfolgreich ein Machine-Learning-Modell für die Übersteuererkennung entwickelt und auf einem ECU-Prototyp bereitgestellt haben, denken wir jetzt über zahlreiche andere potenzielle Anwendungen für Machine Learning bei BMW nach. Uns stehen riesige, über Jahrzehnte gesammelte Datenmengen zur Verfügung und inzwischen kann ein einziges Fahrzeug täglich ein Terabyte an Messdaten generieren. Machine Learning bietet uns eine Gelegenheit, Software zu entwickeln, die die verfügbaren Daten verwendet, um mehr über das Verhalten eines Fahrers zu lernen und sein Fahrerlebnis zu verbessern.
Veröffentlicht 2018