Was ist eine Clusteranalyse?
Die Clusteranalyse befasst sich mit der Anwendung von Clustering-Algorithmen und dient der Erkennung versteckter Muster oder Gruppierungen in einem Datensatz. Sie wird daher häufig in der explorativen Datenanalyse eingesetzt, eignet sich aber auch zur Erkennung von Anomalien und zur Vorverarbeitung beim überwachten Lernen.
Clustering-Algorithmen bilden Gruppierungen auf eine Weise, dass Daten innerhalb einer Gruppe (oder eines Clusters) ein höheres Maß an Ähnlichkeit aufweisen als Daten in anderen Clustern. Es können verschiedene Ähnlichkeitsmaße herangezogen werden, z. B. euklidisch, probabilistisch oder Kosinusabstand und Korrelation. Die meisten Methoden des unüberwachten Lernens sind eine Form der Clusteranalyse.
Clustering-Algorithmen lassen sich in zwei große Gruppen einteilen:
- Das harte Clustering, bei dem jeder Datenpunkt ausschließlich zu einem Cluster gehört, wie z. B. die beliebte k-Means-Methode.
- Das weiche Clustering, bei dem jeder Datenpunkt zu mehr als einem Cluster gehören kann, wie z. B. bei der Gaußschen Verteilungskurve. Als Beispiele seien Phoneme in der Sprache genannt, die als Kombination aus mehreren Grundlauten modelliert werden können, sowie Gene, die an mehreren biologischen Prozessen beteiligt sein können.

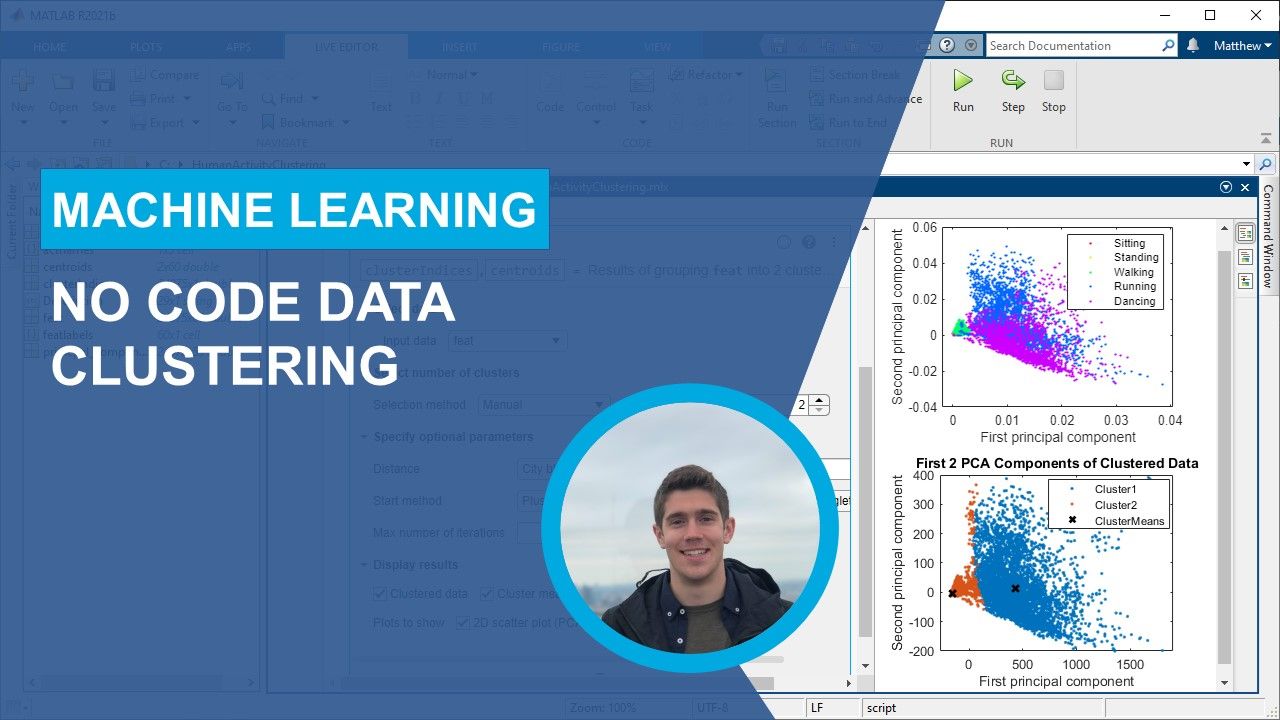
Das k-Means-Clustering repräsentiert Gruppen durch ihren Schwerpunkt – den Durchschnitt der einzelnen Elemente, dargestellt durch die Sterne in der Abbildung oben.

Die Gaußsche Verteilungskurve, die Wahrscheinlichkeiten für die Zugehörigkeit zu Clustern zuweist und die Stärke der Assoziation mit verschiedenen Clustern darstellt.
Die Clusteranalyse wird in einer Vielzahl von Domänen und Anwendungen eingesetzt, um Muster und Sequenzen zu identifizieren:
- Cluster können in Datenkomprimierungsverfahren die Daten anstelle des Rohsignals darstellen.
- Cluster kennzeichnen Regionen von Bildern und LiDAR-Punktwolken in Segmentierungsalgorithmen.
- Das genetische Clustering und die Sequenzanalyse finden in der Bioinformatik ihren Einsatz.
Clustering-Techniken werden auch verwendet, um die Ähnlichkeit zwischen gelabelten und ungelabelten Daten beim teilüberwachten Lernen (Semi-Supervised Learning) herzustellen, bei dem die ersten Modelle mit einem Minimum an gelabelten Daten erstellt werden und dazu verwendet werden, den ursprünglich ungelabelten Daten ein Label zuzuweisen. Im Gegensatz dazu bezieht das teilüberwachte Clustering verfügbare Informationen über die Cluster in den Clustering-Prozess ein, so zum Beispiel, wenn bekannt ist, dass einige Beobachtungen zum selben Cluster gehören, oder wenn mehrere Cluster mit einer bestimmten Ergebnisvariablen assoziiert werden.
MATLAB® unterstützt viele gängige Algorithmen zur Clusteranalyse:
- Hierarchisches Clustering erzeugt eine mehrstufige Hierarchie von Clustern, indem es einen Clusterbaum erstellt.
- k-Means-Clustering teilt Daten in unterschiedliche k-Cluster basierend auf dem Abstand zum Schwerpunkt eines Clusters auf.
- Gaußsche Verteilungskurve bildet Cluster als eine Verteilung von multivariaten Normaldichtekomponenten.
- Dichtebasiertes räumliches Clustering (auch als DBSCAN bekannt) gruppiert Punkte, die nahe beieinander liegen, in Bereichen mit hoher Dichte und behält dabei Ausreißer in Regionen mit geringer Dichte im Blick. Kann beliebige nichtkonvexe Formen verarbeiten.
- Selbstorganisierende Karten verwenden neuronale Netze, die die Topologie und Verteilung der Daten erlernen.
- Spectral Clustering überträgt die Eingangsdaten in eine graphenbasierte Darstellung, in der die Cluster deutlicher voneinander getrennt sind als im ursprünglichen Merkmalsraum. Die Anzahl der Cluster kann durch die Untersuchung der Eigenwerte des Graphen geschätzt werden.
Wesentliche Punkte
- Die Clusteranalyse wird häufig in der explorativen Datenanalyse, zur Erkennung von Anomalien und Segmentierung sowie als Vorverarbeitung für überwachtes Lernen eingesetzt.
- k-Means-Clustering sowie hierarchisches Clustering bleiben weiterhin gefragt, aber für nichtkonvexe Formen sind fortgeschrittenere Techniken wie DBSCAN und Spectral Clustering erforderlich.
- Weitere unüberwachte Methoden, die zur Erkennung von Gruppierungen in Daten verwendet werden können, sind Verfahren zur Dimensionalitätsreduktion und das Feature Ranking.


Beispiele und Erläuterungen
Software-Referenz
Siehe auch: Statistics and Machine Learning Toolbox, Machine Learning mit MATLAB, Image Processing Toolbox, Wahrscheinlichkeitsverteilungen

Sie können auch eine Website aus der folgenden Liste auswählen:
Amerika
- América Latina (Español)
- Canada (English)
- United States (English)
Europa
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)
Asien-Pazifik
- Australia (English)
- India (English)
- New Zealand (English)
- 中国
- 日本Japanese (日本語)
- 한국Korean (한국어)